With the rise in Artificial Intelligence, Deep Learning (DL) has seen exponential growth. Businesses across industries are increasingly adopting DL, driving a surge in demand for skilled AI engineers. As of 2026, the demand for DL professionals has risen by 80%, making it an ideal time to enter this field. This deep learning interview questions and answers guide will help you ace your interview.
This guide covers the most frequently asked deep learning interview questions for freshers, intermediates, and experienced professionals. It also outlines key roles and responsibilities in DL.
Preparing for a deep learning interview means building a solid understanding of both the fundamentals and the practical techniques used in real-world AI systems. Instead of just memorizing definitions, you should know how these concepts work, why they’re used, and when to apply them.
Interviewers often look for a mix of theoretical clarity, hands-on knowledge, and your ability to reason through problems. Below are the essential areas you should focus on while preparing. We will explore these concepts in the interview questions.
| Concept | What You Should Know? | Why It Matters in Interviews? |
|---|---|---|
| Neural Networks Basics | Layers, neurons, activation functions, forward & backward propagation. | Forms the foundation of all deep learning models. |
| Activation Functions | ReLU, Sigmoid, Tanh, Softmax—when and why they are used. | Shows your understanding of model behavior and training stability. |
| Loss Functions | MSE, Cross-Entropy, Hinge Loss, etc. | Interviewers check if you can pick the right loss for a task. |
| Optimization Algorithms | SGD, Adam, RMSProp, Momentum. | Demonstrates your ability to train and tune deep models effectively. |
| Regularization Techniques | Dropout, L2 regularization, early stopping, batch normalization. | Shows how you handle overfitting and improve generalization. |
| Convolutional Neural Networks (CNNs) | Filters, pooling, padding, feature extraction. | Essential for vision-based problem-solving questions. |
| Recurrent Neural Networks (RNNs) | LSTM, GRU, vanishing gradient problem. | Important for sequence modeling and NLP interviews. |
| Transformers & Attention | Self-attention mechanism, positional encoding, encoder-decoder. | Critical because most modern models (GPT, BERT) use transformers. |
| Hyperparameter Tuning | Learning rate, batch size, epochs, and architecture choices. | Shows your practical experience in improving model performance. |
| Model Evaluation | Accuracy, Precision, Recall, F1-score, and confusion matrix. | Interviewers check if you can measure the right metric for the task. |
Freshers may face challenges due to limited experience, but these questions will help you prepare effectively.
Some key applications include:
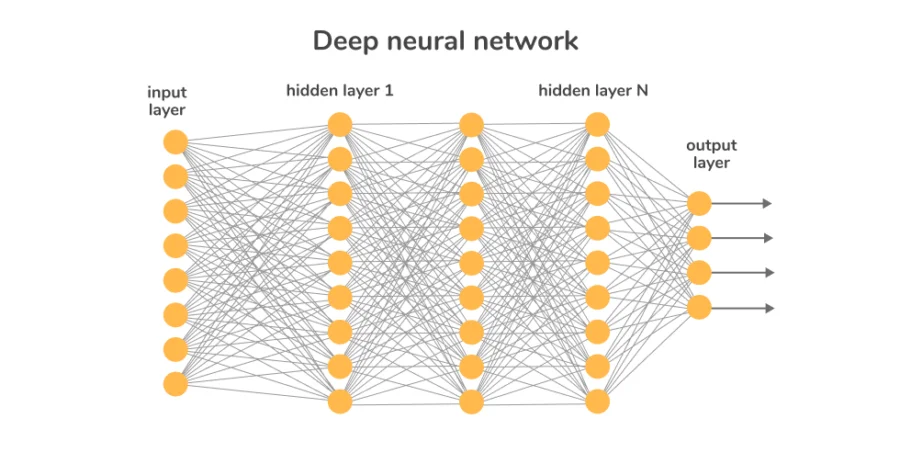
A deep neural network (DNN) is an artificial neural network (ANN) with multiple hidden layers between the input and output layers. These deep architectures use numerous layers and units to learn complex patterns and representations from data.
End-to-end learning in DL involves training a model on raw input data to produce the desired output without intermediate manual steps. The entire process is optimized simultaneously, enabling the model to learn complex mappings directly.
Data normalization is a DL preprocessing technique that transforms data to have a consistent scale or distribution, often called feature scaling or standardization. It removes redundant data and ensures efficient model training.
Data normalization techniques include:
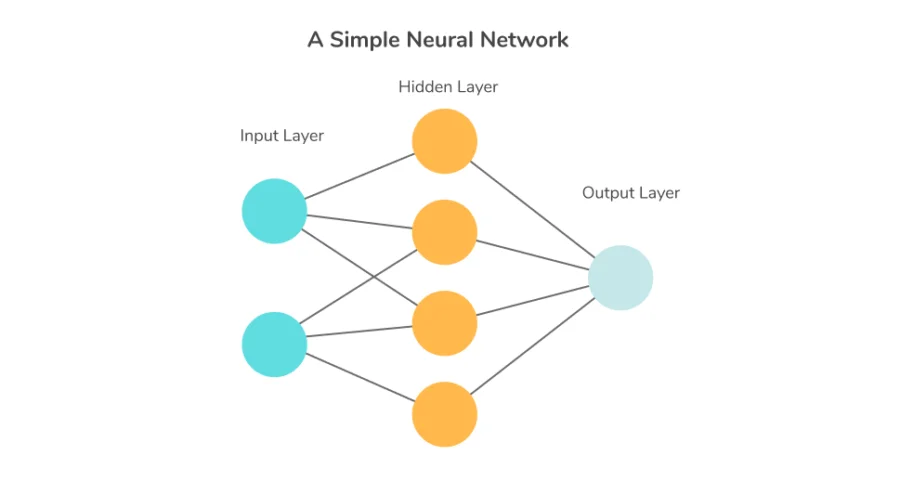
Neural networks are computational systems inspired by biological neural networks in the human brain. They use interconnected layers of nodes to recognize patterns and relationships in data, forming the foundation of DL.
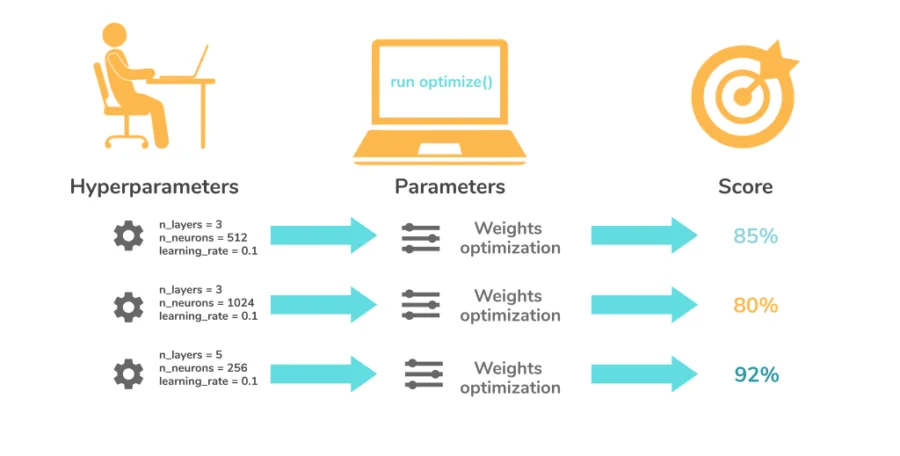
Hyperparameters are configuration settings that define the structure and training process of a DL model, set before training begins. Examples include learning rate, number of hidden layers, and batch size.
A Multi-layer Perceptron (MLP) is a feedforward ANN with input, hidden, and output layers of interconnected neurons. It uses non-linear activation functions to learn complex patterns for tasks like classification (e.g., image recognition) and regression, excelling with structured data.
Related Article- Deep Learning With TensorFlow
For those with some experience, these intermediate questions will strengthen your preparation.
There are several types of DNNs:
Forward propagation passes input data through the neural network to generate predictions. Back propagation calculates errors and updates weights and biases to minimize the loss, optimizing the model.
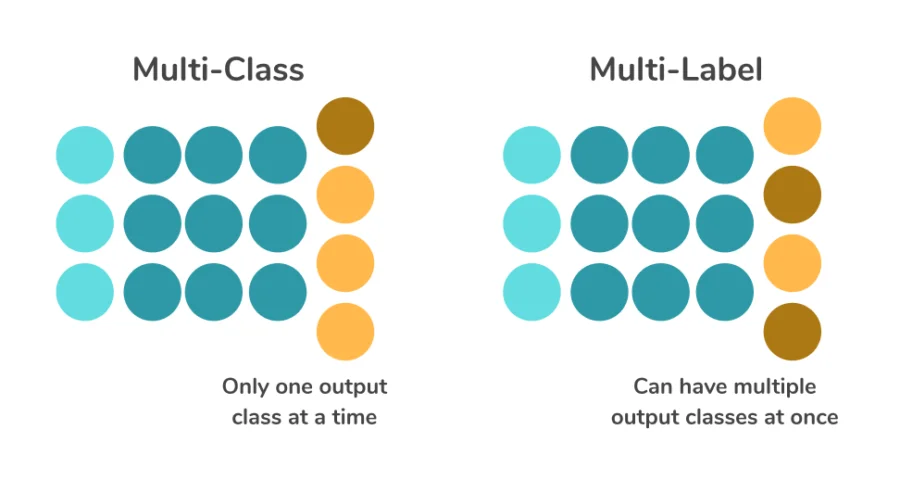
In multi-label classification, each instance can belong to multiple related classes simultaneously. In multi-class classification, each instance belongs to one of several mutually exclusive classes.
Key advantages of transfer learning include:
A tensor is a multidimensional array used to represent data in DL, generalizing vectors and matrices. All elements share the same data type, making tensors essential for computations in frameworks like TensorFlow.
Batch gradient descent computes gradients over the entire training dataset at each step, making it slow and computationally expensive for large datasets. It suits smooth or convex error surfaces.
Top face detection algorithms include:
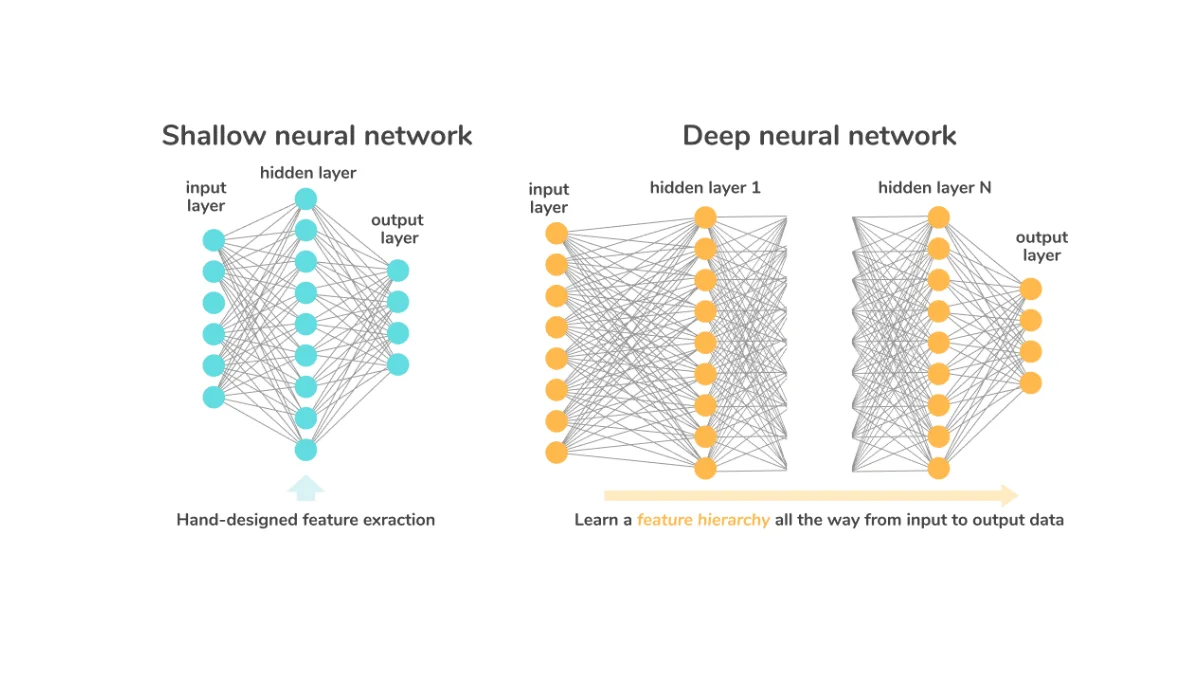
The primary difference is the number of hidden layers. Here are key distinctions:
| Feature | Shallow Networks | Deep Networks |
| Number of Hidden Layers | Typically one (or very few) | Multiple hidden layers |
| Complexity | Lower | High |
| Learning Capacity | Limited | High |
| Feature Extraction | Limited ability to extract complex features | Excellent at automatic feature extraction |
| Data Requirements | Works with smaller datasets | Requires large datasets |
| Computational Resources | Lower requirements | High requirements |
| Risk of Overfitting | Lower risk | Higher risk (needs regularization) |
| Types of Problems | Suitable for simpler problems | Suitable for complex tasks (e.g., image recognition, NLP) |
| Examples | Single-layer perceptrons, logistic regression | CNNs, RNNs, Transformers |
Related Article- Deep Learning Tutorial for Beginners
These advanced questions are tailored for experienced professionals.
If the problem is linearly separable, a deep network can use linear activation functions in each layer, though this is rare as non-linear activations are typically needed for complex tasks.
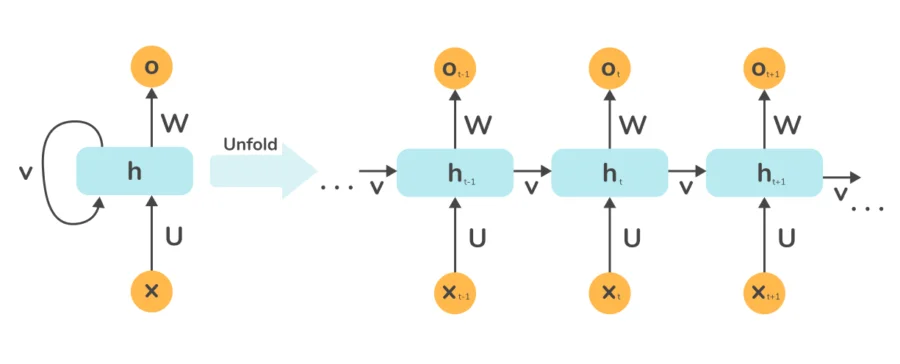
RNN backpropagation includes a temporal loop, allowing it to capture sequential dependencies in data, unlike standard ANN backpropagation, which processes static data without temporal context.
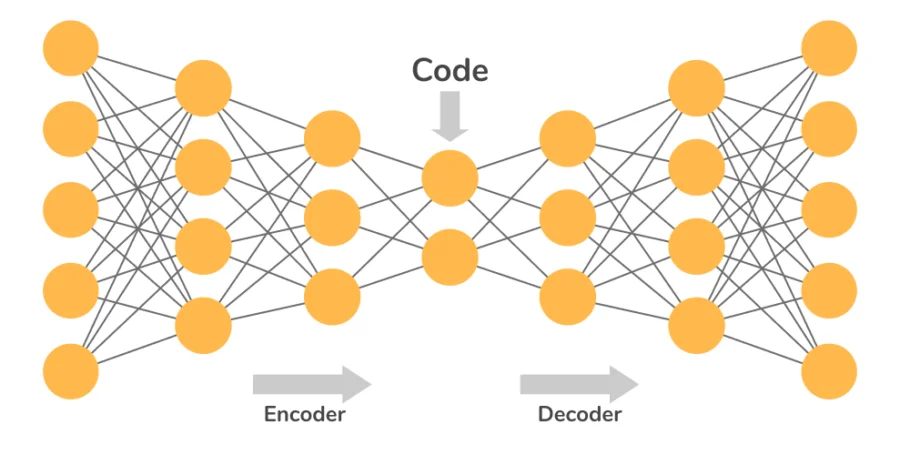
Autoencoders are neural networks where the input and output layers have the same dimensions, designed to replicate input data. They consist of:
Key applications include:
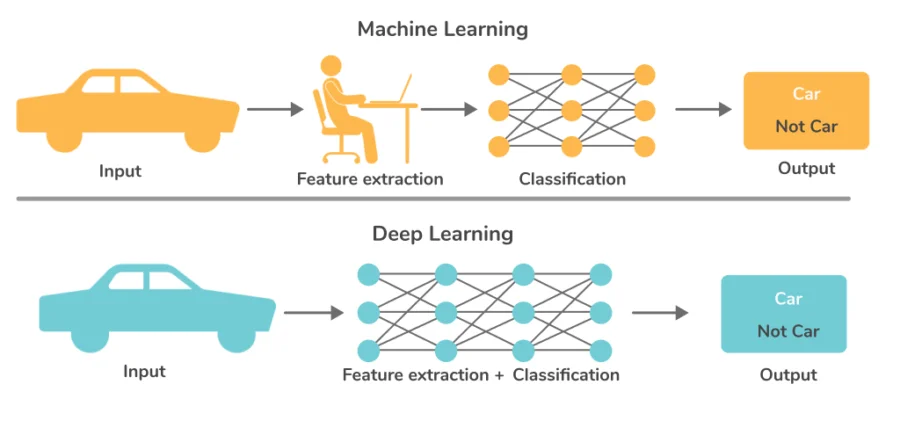
ML is a subset of AI that enables systems to learn from data without explicit programming. DL, a subset of ML, uses deep neural networks (e.g., ANNs, RNNs) to mimic human brain processes, tackling complex tasks like image recognition and NLP.
It excels in handling large-scale, unstructured, and multimodal data.
| Deep Learning | Machine Learning |
| Subset of ML | Subset of AI |
| Works with millions of data points | Works with thousands of data points |
| Uses neural networks for data representation | Uses structured data in various formats |
| Excels in complex, unstructured, and multimodal data | Suitable for structured data and simpler tasks |
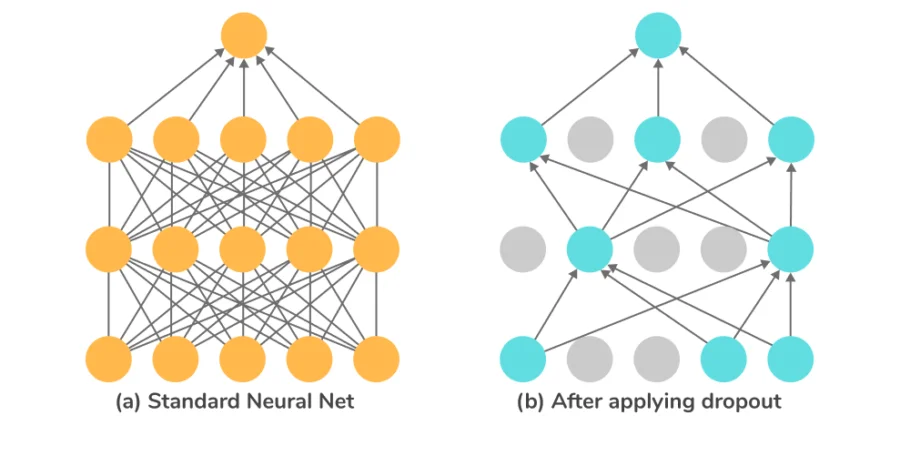
Dropout is a regularization technique in DL that prevents overfitting by randomly disabling 20-50% of neurons during training, improving model generalization.
A Feedforward Neural Network (FFNN) is a model where data moves unidirectionally from input to output layers without loops. It excels in static data tasks, including:
A cost function measures the error between a model's predictions and actual outputs, guiding weight adjustments during training. Common types include:
It provides feedback to optimize the model.
Effective DL algorithms for face detection, typically based on CNNs, include:
These questions focus on programming libraries, frameworks, and tools for DL engineers.
DL frameworks are software libraries and tools that simplify model development and training. They provide high-level APIs for building and optimizing neural networks. Popular frameworks include TensorFlow 2.x, PyTorch 2.x, Keras, and JAX.
Key TensorFlow elements for DL include:
Load and preprocess image data using TensorFlow Keras datasets, normalizing pixel values and encoding labels. Define a CNN with convolutional, pooling, and dense layers. Compile the model with an optimizer (e.g., Adam), loss function (e.g., Cross-Entropy), and metrics. Train on the dataset, monitor validation performance, and evaluate on test data for generalization.
Yes, PyTorch supports regularization to prevent overfitting. Add L1/L2 regularization to the loss function, include dropout layers (e.g., 20-50% dropout rate), and use early stopping to halt training if validation performance degrades.
Load a pre-trained model (e.g., ResNet, BERT), freeze early layers to retain learned features, add task-specific layers, and train them. Optionally unfreeze some layers for fine-tuning, using a smaller learning rate to adapt the model to the new task efficiently.
Now we will explore some of the most asked scenario based deep learning interview questions and answers. These are mostly asked to check your proficiency in real-world applications. I have also structured the answers exactly how you should answer these types of questions.
This kind of situation requires proper planning. First, I would stop relying on accuracy and redefine success using business-aligned metrics such as precision-recall, F1-score, recall@k, or cost-based metrics. With only 2% positives, accuracy is misleading.
On the data side, I would audit label quality by sampling edge cases and using techniques like disagreement analysis or weak supervision to identify noisy labels. For imbalance, I would apply class-weighted loss functions or focal loss instead of aggressive oversampling, which can amplify noise.
Finally, I would validate using stratified splits and possibly time-based validation if applicable, ensuring the evaluation setup reflects real production behavior.
I would start by confirming the issue through learning curves to check whether the model is variance-driven or data-limited. Then, I would verify data leakage to ensure no overlap or feature leakage between training and validation.
Next, I would simplify the model by reducing depth or parameters, add regularization techniques such as dropout, weight decay, and data augmentation, and tune the learning rate and batch size.
If performance still drops in production, I would compare training vs production feature distributions to detect data mismatch. Based on findings, I would either retrain with representative data or adjust the feature pipeline to better align with real-world inputs.
I would start with transfer learning or pre-trained models rather than training from scratch, as this provides strong performance with limited compute. Architecturally, I would choose efficient models like MobileNet, EfficientNet, or distilled versions of larger models.
At the training level, I would use mixed-precision training, optimized batch sizes, and early stopping to reduce wasted computation. I would also prioritize tuning high-impact hyperparameters first, such as learning rate and optimizer choice, instead of exhaustive searches.
If necessary, I would trade off marginal accuracy for latency-optimized inference, ensuring the final model meets both performance and resource constraints.
I would monitor input data drift, prediction distribution drift, and performance metrics such as precision and recall over time. I would also track feature-level statistics to detect changes in upstream data pipelines.
Once degradation is confirmed, I would identify whether the issue is covariate drift, concept drift, or data quality issues. Based on the root cause, I would either retrain the model with recent data, fine-tune it incrementally, or update feature engineering logic.
To prevent recurrence, I would implement automated monitoring, alerting, and scheduled retraining pipelines, ensuring long-term model reliability.
I would first provide a clear, human-readable explanation using tools like SHAP to highlight which features most influenced the rejection, focusing on factors such as income stability or credit history rather than model internals.
Next, I would audit the model for bias by analyzing performance across protected groups and checking fairness metrics like disparate impact or equal opportunity. If bias is detected, I would mitigate it through data rebalancing, feature review, or fairness-aware training techniques.
Finally, I would document the model’s decision logic, validation results, and fairness checks to ensure regulatory compliance, transparency, and trust, both for customers and internal stakeholders.
DL engineers have varied responsibilities, including:
These deep learning interview questions and answers are ideal for anyone looking to build a career in this field. Whether a beginner, intermediate, or professional, understanding common questions is key, and this guide provides a comprehensive overview.
Explore These Articles -
Top Applications of Artificial Intelligence
Salesforce Integration Interview Questions
Study core concepts like neural networks, backpropagation, optimization, and architectures (CNNs, RNNs, Transformers). Practice coding with TensorFlow or PyTorch and solve real-world problems.
Yes, programming skills, particularly in Python, are crucial for implementing models and solving practical DL interview problems.
Prepare thoroughly, stay confident, demonstrate problem-solving skills, and explain your thought process clearly during technical discussions.
Key topics include:
Deep learning uses multi-layered neural networks to automatically learn features, while traditional machine learning often requires manual feature selection.
Course Schedule
| Course Name | Batch Type | Details |
| TensorFlow Training | Every Weekday | View Details |
| TensorFlow Training | Every Weekend | View Details |