Machine Learning (ML) and Artificial Intelligence (AI) are at the forefront of today's technical advancements. Whether you are a student, a tech professional or just a normal guy, it is almost everywhere in your daily life, creating a lot of opportunities for ML professionals. But how to become one? It of course requires in-depth understanding of core concepts and the ability to actually implement them. To help you navigate this complex landscape, we have compiled a list of the most frequently asked Machine Learning interview questions.
These questions are designed by our experienced trainers with significant years of experience in the industry. These have certainly been asked more times than others and answering them will certainly play a role in helping them clear the interview. Let's get started with the basic machine learning interview questions and answers.
Explore most asked machine learning interview questions and answers, covering topics like ML models, algorithms, techniques, etc, best for newbies & pros.
Let’s begin with the most basic Machine Learning interview questions and answers. These are mostly asked in beginner-level interviews to check the candidate’s fundamental knowledge.
Machine Learning is a robust technology that creates algorithms and statistical models to help computers learn from vast datasets for decision making and trend forecasting without using explicit programming. It is also a part of Artificial Intelligence. Everything you see in AI technologies, AI chatbots, AI assistants and more are somewhere related or trained with this technology.
Machine Learning is generally divided into three main categories including:
A. Supervised Learning: It is where an algorithm learns to map input data to a specific output based on example input-output pairs. This process involves training a model using a labeled dataset, which means each input in the dataset is associated with a known and correct output.
B. Unsupervised Learning: It involves analyzing and finding patterns in unlabeled data without any prior training. What makes it different from the supervised learning is that it does not require a teacher to correct its output
C. Reinforcement Learning: Reinforcement learning is an area concerned with how an agent ought to take actions in an environment to maximize the notion of cumulative reward.
Supervised learning is mainly divided into two types based on the type of the target variable. These two types are:
Further it is divided into different types of classification and regression techniques too.
Some of the most commonly used supervised techniques are:
Some of the commonly used unsupervised techniques are:
Both classification and regression are types of supervised learning techniques. This means that the data set would also be labeled. Classification segregates data points into predetermined categories and the target variable would be discrete in nature like binary labels (yes or no) or multi-level (the class I, class II and class III). For example-
However, in the case of regression, the target variable would be continuous in nature like the age of a person, sales figures, domestic growth, GDP, population, etc. For instance-
Dimensionality reduction or dimension reduction is a feature selection method used to reduce the number of variables under consideration in a data set. It is performed using PCA or TSNE. Once it is applied, we are left with variables that are statistically more significant. This makes it more helpful for model building exercises.
There are various types of dimensionality reduction techniques including:
Some of the common real life applications of machine learning algorithms include:
Ensemble learning is a combination of multiple machine learning models. It combines different weak learners to create a single and powerful model. This model can achieve better predictive performance than any individual model could alone.
It is used to improve accuracy and reliability, reduce errors and overcome the limitations of single models by mitigating issues like bias (underfitting) and variance (overfitting). This technique is widely applied in various fields for tasks such as medical diagnostics, financial risk assessment, and fraud detection.
There are generally two paradigms of ensemble methods including:
Related Article - Machine Learning Operations MLOps Overview
This section introduces the most important intermediate Machine Learning interview questions and answers. Exploring them will strengthen your technical knowledge and help you to improve your career.
Regularization is a set of practices used to deal with model overfitting. It helps to simplify and improves the performance of a model. In overfitting conditions where a model learns too well from the training data, even noise and outliers also affects learning which leads to extensive complexities and poor performance.
This is where regularization comes to rescue with different types of strategies to reduce the complexity and makes the model more efficient. There are three types of Regularization in machine learning including:
Cost=n1∑i=1n(yi−yi^)2+λ∑i=1m∣wi∣ |
Cost=n1∑i=1n(yi−yi^)2+λ∑i=1mwi2 |
Cost=n1∑i=1n(yi−yi^)2+λ((1−α)∑i=1m∣wi∣+α∑i=1mwi2) |
Feature engineering is a process of transforming input data into a more suitable and efficient form to improve the predictive performance of an ML model. It is one of the crucial processes for data scientists and engineers as the performance of any model depends on the data used to train them. They can use it to analyze and select the most appropriate data to achieve the best predictive performance.
Here are the difference between bagging and boosting.
| Feature | Bagging | Boosting |
| Primary Goal | Reduce Variance (Prevent Overfitting) | Reduce Bias (Improve Accuracy) |
| Data Sampling | Bootstrap (Random sampling with replacement). | Weights assigned to data points, higher weights for misclassified instances. |
| Model Training | Independent and Parallel | Sequential |
| Model Weighting | Equal | Weighted based on performance |
| Model Type | Typically homogeneous (same type of model) | Typically homogeneous |
| Focus | Stability and Robustness | Accuracy and Performance |
| Examples | Random Forest and Bagged Decision. | Trees AdaBoost, XGBoost and Gradient Boosting Machines (GBM). |
Naive Bayes is a simple, probabilistic classification algorithm that simplifies calculations and allows for fast predictions. It is based on Bayes' theorem, assuming features are independent of each other. Here is the formula of this algorithm -
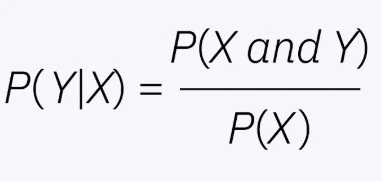
Let's understand its working with an instance. An individual Meghna takes a test to check if she has diabetes. Let's say the probability of her having diabetes is 5%, it will be our initial probability. In case, her result is positive the initial probability will become the posterior probability. This instance will be represented as follows -

Random Forest and Gradient Boosting are both powerful ensemble methods that use decision trees as base learners. Their approach of model creation is what makes them different. Here is a breakdown of their key differences -
| Feature | Random Forest | Gradient Boosting |
| Building Process | Parallel and independent trees | Sequential and error-correcting trees |
| Error Reduction | Variance reduction | Bias reduction |
| Overfitting | Less prone | More prone |
| Interpretability | Relatively easier | More complex |
| Training Speed | Faster | Slower |
| Hyperparameter Sensitivity | Less sensitive | More sensitive |
| Feature Randomization | Yes | Generally no (but stochastic gradient boosting exists) |
| Bootstrapping | Yes | No |
| Prediction Aggregation | Averaging/Voting | Additive model |
SVM is basically a type of supervised ML algorithm that is used to perform classification and regressions tasks. It is mostly known for its utility in classification tasks. This algorithm detects the hyperplane which is best for separating two classes by increasing the margin between them. This margin refers to the distance from the hyperplane and nearest data points.
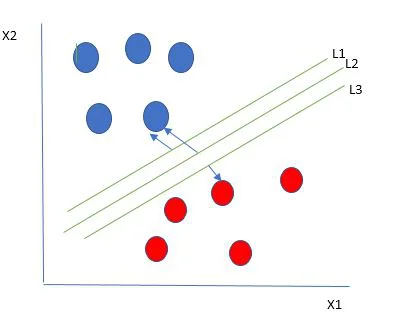
Multiple hyperplanes separating the data from two classes
A Receiver Operating Characteristic (ROC) curve is a graphical representation that evaluates the performance of a binary classification model. It does so by plotting the true positive rate (TPR) against the false positive rate (FPR) at different threshold settings. It is primarily used by data scientists, ML engineers and medical researchers.
Multicollinearity is an issue that often occurs in multiple regression models when two or more independent variables have high intercorrelations. In this case, data analysts and researchers may face skewed or misleading results when determining the performance of each independent variable. This means they can not predict or understand how well will dependent variable will perform in a statistical model.
Radial Basis Function (RBF) is a mathematical function whose value depends solely on the distance from a central point. This makes it useful for modeling non-linear relationships in tasks like function approximation, interpolation and classification. Here is the mathematical representation of this function -
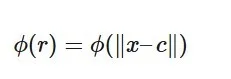
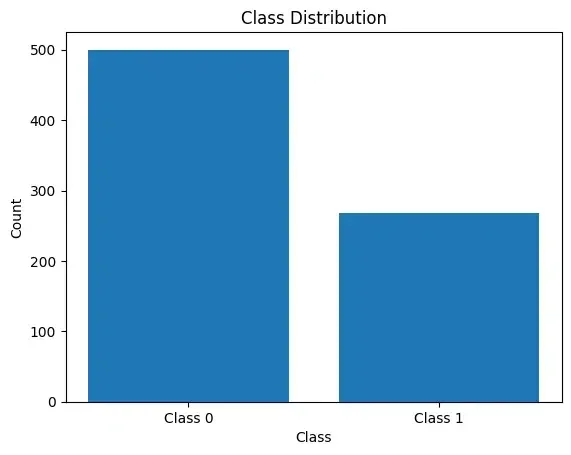
SMOTE also known as Synthetic Minority Oversampling Technique is method of handling class imbalance in datasets. It does so by generating samples of minority classes which distribute class in a balanced way. Here is an example of implementing SMOTE for imbalanced classification in Python -
import matplotlib.pyplot as plt import pandas as pd data = pd.read_csv('diabetes.csv') x=data.drop(["Outcome"],axis=1) y=data["Outcome"] count_class = y.value_counts() # Count the occurrences of each class plt.bar(count_class.index, count_class.values) plt.xlabel('Class') plt.ylabel('Count') plt.title('Class Distribution') plt.xticks(count_class.index, ['Class 0', 'Class 1']) plt.show() |
Output -
The following are the top advanced machine learning interview questions and answers. These are often asked in senior level machine learning job interviews. These are most suitable for experts with more than five years of experience in this industry.
Natural Language Processing (NLP) is a field of machine learning that helps computers understand and manipulate human language. Think of it as an interpreter between computers and humans that translates the language for both of them. NLP is also considered as an intersection of computer science, artificial intelligence and computational linguistics.
It is used to perform automatic summarization, translation, named entity recognition, relationship extraction, sentiment analysis, speech recognition, and topic segmentation. It is one of the fastest growing fields in the area of AI and ML, owing to the large amount of natural language that gets generated in the digital world of today.
Imbalancement in data is a characteristic of supervised learning. It occurs when the ratio of a level in the target variable is proportionately larger than the other. For instance: In the case of a binary target variable with 'yes' or 'no' levels, if the proportion of any one of them is significantly more than the other, we say the data is imbalanced.
Data can also be imbalanced for categorical variables with more than two levels.
The above phenomenon in data sets often results in skewed model results, if not handled properly. We can handle data imbalance by applying these techniques:
The assumptions of OLS regression technique are -
Read Also- How To Become A Machine Learning Engineer?
Machine learning (ML) is an application of artificial intelligence that provides systems the ability to automatically learn and improve from existing data and experience. The need to be explicitly programmed every time is eliminated. ML is concentrated on the development of computer programs to access data.
Machine starts learning/analyzing with observations or data (examples or instructions) to look for patterns and make better decisions in the future on the provided data. Computers are crafted to learn automatically without any human assistance or intervention, and adjust their actions accordingly. Machine learning focuses on analyzing and learning from data based on features/variables fed into the model to make better decisions.
Deep Learning, on the other hand, is a subset of machine learning techniques. It constructs artificial neural networks (ANNs), which copy and reconstruct the function and structure of the human brain. The focus here is on feature extraction. Information is deduced from multiple layers and each layer propagates the information to another layer for the final outcome.
In practice, deep learning, also known as deep structured learning or hierarchical learning, uses a large number of hidden layers of nonlinear processing to extract features from data. This data is then transformed into different levels of abstraction.
It is important to handle missing values when preparing the data for building models. Managing it involves finding the data that has missing values and deciding which techniques to use accordingly. Data types could either be discrete or continuous and hence, the missing values too. There are a few Machine Learning models that could handle missing values. Some of the basic techniques to handle missing values are:
Common steps for building an end-to-end ML model include:
Candidates must always be well-read and aware of the latest developments being made in ML by reading published research papers and scientific journals. You can find various research papers in the field of machine and DL for a better understanding. This is a field where you will have to keep practicing and this question checks whether you like to stay updated or not.
Machine learning, on the other hand, is a field of study that deals with developing algorithms and methodologies on its own.
In data mining, we extract information to build insights from different types of sources and data. It is an exhaustive process where one can use statistical and visualization techniques to extract meaningful insights.
F1 score is a performance measuring metric for supervised classification algorithms. It is the weighted average or the harmonic mean of the Recall and Precision values of a model. It is considered a robust technique to evaluate model performance.
Pruning is a method that is applicable to tree-based methods. Hence, it can be observed in supervised algorithms. Replacement of nodes of a decision tree in a top-down or bottom-up way is carried out during pruning. It becomes very helpful in increasing the accuracy of the decision tree while also reducing its complexity and overfitting.
The objective of pruning is to reduce the size of a tree without affecting the accuracy as measured by cross-validation. The two commonly used pruning methods are:
This section includes the most frequently asked Machine learning interview questions. These questions will help in interviews irrespective of your experience.
With the rapid evolution of ML, there are various exciting updates that come to mind. There is significant progress in generative AI making it capable of creating engaging content like images, videos and even music. We can also see a notable improvement towards the following areas -
Clustering algorithms are typically used for following application -
The linear regression gives a continuous and unbound output, which is not ideal for classification tasks. The classification tasks require discrete and bounded outcomes only. In case we use linear regression in a classification task, it will not give a convex graph for error function.
Therefore, there will not be any global minima that means the model will get stuck at some local minima. To avoid this issue, linear regression algorithms are not preferred to use in a classification task.
Both precision and recall are metrics that can evaluate the overall performance of a classification model. These are mostly used in class imbalance situations. Recall focuses on the ability to find all relevant instances, while precision only aims on accuracy of positive predictions.
Principal Component Analysis is a dimensionality reduction method that can change high-dimensional information into a lower-dimensional space, while retaining most of the original data. It does this by finding uncorrelated variables called principal components, which stores the most variance in the data.
These are -
Building a model involves the following steps -
Computation, Cognition and Communication are the three C's of ML. These are the foundational pillars for understanding how artificial intelligence can be transformative. Gaining insights into these concepts can help to shape the future of technology.
These two are the types of errors that can occur in classification models. The False Positive error means the model is making incorrect predictions of a negative case as positive. Just opposite to it, the False Negative error means the model incorrectly predicts a positive case as negative.
Both of these are machine learning algorithms that serve different purposes. K-means is an unsupervised learning algorithm often used in clustering. The goal of K-means is to group similar data points into clusters in respect to their features. On the other hand, KNN is a supervised learning algorithm best for classification or regression. KNN predicts the class of a data point according to the majority class of its next neighbors.
Coding is of course not the most important skill for a ML professional, but having it can be very beneficial. The senior job roles are often expected to have coding knowledge. Here are some of the common machine learning coding interview questions that can help you showcase your programming skills.
Here is how you perform rolling window mean:
import numpy as np
def rolling_window_mean(x: np.ndarray, k: int) -> np.ndarray:
"""
Return moving average with NaN for first k-1 positions.
"""
x = np.asarray(x, dtype=float)
if k <= 0:
raise ValueError("k must be positive")
if k > len(x):
return np.full(len(x), np.nan)
kernel = np.ones(k) / k
valid = np.convolve(x, kernel, mode="valid")
out = np.empty(len(x))
out[:k-1] = np.nan
out[k-1:] = valid
return out
|
Here is how you perform Target Encoding with CV:
import numpy as np
def target_encode_cv(col: np.ndarray, y: np.ndarray, n_splits: int) -> np.ndarray:
"""
Out-of-fold mean target encoding for a single categorical column.
"""
col = np.asarray(col)
y = np.asarray(y, dtype=float)
n = len(col)
indices = np.arange(n)
np.random.shuffle(indices)
folds = np.array_split(indices, n_splits)
encoded = np.empty(n, dtype=float)
for i in range(n_splits):
val_idx = folds[i]
train_idx = np.concatenate([folds[j] for j in range(n_splits) if j != i])
train_means = {c: y[train_idx][col[train_idx] == c].mean()
for c in np.unique(col[train_idx])}
global_mean = y[train_idx].mean()
encoded[val_idx] = [train_means.get(c, global_mean) for c in col[val_idx]]
return encoded
|
Here is how you perform Non-Maximum Suppression (NMS):
import numpy as np
def nms(boxes: np.ndarray, scores: np.ndarray, iou_thresh: float) -> np.ndarray:
"""
Suppress overlapping boxes based on IoU.
boxes: (N,4) [x1,y1,x2,y2]
"""
x1, y1, x2, y2 = boxes.T
areas = (x2 - x1) * (y2 - y1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.clip(xx2 - xx1, 0, None)
h = np.clip(yy2 - yy1, 0, None)
inter = w * h
union = areas[i] + areas[order[1:]] - inter
iou = inter / np.maximum(union, 1e-12)
order = order[np.where(iou <= iou_thresh)[0] + 1]
return np.array(keep)
|
Here is how you perform Cosine Similarity Matrix:
import numpy as np
def cosine_similarity_matrix(A: np.ndarray, B: np.ndarray, eps: float = 1e-12) -> np.ndarray:
"""
Compute pairwise cosine similarity between rows of A and B.
"""
A = np.asarray(A, dtype=float)
B = np.asarray(B, dtype=float)
A_norm = np.linalg.norm(A, axis=1, keepdims=True)
B_norm = np.linalg.norm(B, axis=1, keepdims=True)
denom = np.clip(A_norm, eps, None) * np.clip(B_norm.T, eps, None)
return (A @ B.T) / denom
|
Here is how you perform Reservoir Sampling:
import random
from typing import Iterable, List
def reservoir_sample(stream: Iterable[int], k: int, seed: int | None = None) -> List[int]:
"""
Uniform reservoir sampling (Algorithm R).
"""
rng = random.Random(seed)
reservoir = []
for i, item in enumerate(stream):
if i < k:
reservoir.append(item)
else:
j = rng.randint(0, i)
if j < k:
reservoir[j] = item
return reservoir
|
Machine learning engineering is one of the most demanded, profitable and competitive careers. Here are some of the most asked machine learning engineer interview questions that can give you a competitive advantage.
Decision tree classification is basically a supervised ML method that uses a flowchart based structure to categorize data into predefined classes. It recursively splits the dataset into smaller and more homogeneous subsets based on feature values. It is a versatile technique of predicting categorical outcomes by finding optimal splits that minimize data impurity, using algorithms like Gini impurity or information gain. The process involves a hierarchical tree structure with:
There are various methods finding the optimal number of clusters like:
These three are the best methods, but you can also analyze a dendrogram from hierarchical clustering or use criteria like AIC and BIC with models like Gaussian Mixture Models. The choices completely depend on the user requirements and preference.
Upsampling is used to make data larger by adding or interpolating information. Downsampling is used to make data smaller by discarding information. Here are some other differences:
| Feature | Upsampling | Downsampling |
| Definition | Process of increasing resolution/size of data (image, signal, feature map). | Process of reducing resolution/size of data. |
| Data Handling | Adds new data points (interpolated or generated). | Removes or ignores some data points. |
| Image Example | 32x32 to 64x64 | 64x64 to 32x32 |
| Methods Used | Nearest Neighbor, Bilinear Interpolation, Bicubic, Transposed Convolution (in DL). | Max Pooling, Average Pooling, Strided Convolution, Subsampling. |
| Information Effect | Creates more pixels but may introduce artifacts or blurriness (since info is guessed). | Compresses data, may lose detail but highlights important features. |
| Purpose | Reconstruction, super-resolution, image generation, segmentation. | Feature extraction, dimensionality reduction, faster computation. |
| Deep Learning Use | Decoder part of autoencoders, GANs, segmentation networks (e.g., U-Net). | Encoder part of CNNs, reducing feature map size. |
| Computation Cost | Higher (more data points to process). | Lower (fewer data points). |
Identifying data leakage involves:
To prevent it:
One-shot learning is another machine learning technique that enables a model to recognize a new category or object from just a single labeled example. It is different from traditional models that require vast datasets for training. It focuses on the ability of models to generalize and learn a similarity function to compare new inputs to the single example. This makes it highly effective in scenarios where it is hard to get data like facial recognition and medical diagnostics.
Machine Learning is a part of Artificial Intelligence. Everything you do or perform in your profession is somehow related to AI. You need to know how they both relate. The following AI ML interview question can help you do that.
Supervised learning involves training a model on labeled data where the input feature is mapped to a known output target. Examples include regression and classification.
Unsupervised learning works with unlabeled data to find patterns or structures. It includes clustering or dimensionality reduction. Example algorithms: K-means (unsupervised) vs. linear regression (supervised).
Overfitting is the result of a model learning too well from the training data. It always performs well on training but poorly on unseen data. Prevention methods include:
The bias-variance tradeoff balances model complexity. If a model has a High bias it means the model is too simple and missing patterns. If a model is a High variance it means the model is too complex and is capturing noise. The goal is to find an optimal model complexity that minimizes total error (bias + variance + irreducible error).
Cross-validation is a technique to evaluate a model's performance by splitting data into multiple subsets (folds). The model trains on some folds and tests on others. This process is repeated across all folds. K-fold cross-validation ensures robust performance estimates to reduce overfitting and assess generalization.
SVM detects the optimal hyperplane that will separate classes with as maximum margin as possible. For non-linearly separable data, it uses the kernel trick (e.g., RBF kernel) to transform data into a higher-dimensional space. The main goal is to minimize classification errors while getting the maximum margin possible.
These scenario-based questions are designed to test a candidate's ability to apply ML concepts to real-world problems. These are focused on emerging topics like federated learning, edge AI, multimodal models, explainable AI (XAI), and machine unlearning. They emphasize practical problem-solving, ethical considerations, and recent advancements in ML as of 2026.
In this scenario, federated learning (FL) is ideal as it allows model training across decentralized devices without sharing raw data. Here's my step-by-step approach:
Edge AI shifts computation to the device edge, reducing reliance on cloud servers. My approach:
Multimodal learning fuses data from multiple modalities (text + images) for richer insights. Step-by-step design:
XAI makes opaque models interpretable, crucial for regulated industries. My approach:
Machine unlearning efficiently erases specific data influences, an emerging ethical ML topic. Step-by-step:
A sudden drop in recommendation performance often indicates model drift, data quality issues, or changing user behavior. My approach would be:
This systematic approach helps restore recommendation quality while minimizing business risk.
Accuracy alone can be misleading when working with highly imbalanced datasets such as fraud detection.
The primary goal would be reducing false negatives rather than maximizing overall accuracy.
Reliable forecasting requires careful preprocessing and feature engineering before model selection.
This approach ensures the model captures both seasonal patterns and long-term business trends.
Large Language Models can hallucinate when they lack sufficient context. Instead of retraining, I would implement:
This strategy significantly improves accuracy while avoiding the cost of retraining a large foundation model.
Production issues often arise from infrastructure constraints, data drift, or differences between training and serving environments.
A strong MLOps strategy ensures the model remains accurate, scalable, and reliable throughout its lifecycle.
Preparing for machine learning interviews requires a strategic approach to showcase your expertise in algorithms, data science, programming and problem-solving. The best way to excel in machine learning interviews is to follow the given steps:
Core concepts of machine learning like supervised learning, unsupervised learning, reinforcement learning and deep learning builds the foundation. There are also different kinds of algorithms like linear regression, logistic regression, decision trees, random forests, support vector machines and neural networks. Some other topics are gradient descent, overfitting, underfitting, regularization (L1/L2) and hyperparameter tuning.
You have to master or familiarize yourself with all of the above mentioned concepts. They are building blocks of this technology. Start with mastering them and it will make your further journey easier.
Coding is also an essential skill of machine learning professionals like engineers and developers. Programming proficiency can help to get an upper hand in the vast commission of the current job market. Start with focusing on the most used programming languages like Python or R.
Then continue to learn about core Python libraries like NumPy, pandas, scikit-learn, TensorFlow, and PyTorch. Interviewers can also ask you to write code for model training or data preprocessing during technical interviews. This means you should also practice coding examples for better learning.
The next step is to dive into deep learning and neural networks. Mastery in these areas is essential for roles involving computer vision or natural language processing. You can start with studying neural network architectures like convolutional neural networks (CNNs), recurrent neural networks (RNNs), LSTMs and transformers. Then move to backpropagation, activation functions and optimization techniques like Adam or RMSprop.
Many machine learning interviews include system design questions to evaluate your ability to build scalable ML systems. This is why it is important to learn how to design end-to-end machine learning pipelines. It includes mastering data ingestion, preprocessing, model training, deployment and monitoring. Also understand concepts like batch processing, real-time inference, A/B testing and model versioning.
You also need to familiarize yourself with tools like Docker, Kubernetes and cloud platforms (AWS, GCP, Azure) for deploying models. They are an important part of model deployment.
Getting the technical skills will not be enough if you don’t know how to showcase it. This is where you need to prepare for the most asked machine learning interview questions and answers. They include different questions on important topics that can be asked during any interview, with comprehensive answers. These answers are designed to impress the interviewers that will help you secure the job.
Q1. What is the primary goal of Machine Learning's supervised learning?
Q2. Which 2026 ML trend involves training models across decentralized devices?
Q3. What is a key feature of Large Language Models (LLMs) in 2026?
Q4. Which technique helps prevent overfitting in Machine Learning?
Q5. What is the purpose of AutoML in 2026?
Q6. Which ML trend supports on-device processing for IoT in 2026?
Q7. What is the role of the F1-score in Machine Learning?
Q8. How does transfer learning benefit ML model development in 2026?
Q9. Which Python library is commonly used for ML model development?
Q10. What is a benefit of explainable AI (XAI) in 2026?
Also Explore: Top Machine Learning MCQs
As technology continues to change, more jobs in the domain of artificial intelligence and data science are bound to emerge. This is the right time to upskill yourself to become at par with the current job trends. Gaining a right skill set will give your career a boost in the right direction, and for this, you can take the aid of online resources and tutorial. These machine learning interview questions will help you get a little closer to your dream of being a part of the expanding field.
Yes, Machine Learning is a good career choice for freshers in 2026. It offers strong demand, growth opportunities and high-paying roles.
Python is the most popular and beginner-friendly language for Machine Learning.
Yes, software developers can move into machine learning roles. Strong programming skills and basic ML knowledge make the transition easier.
Course Schedule
| Course Name | Batch Type | Details |
| AI and ML Certification Courses | Every Weekday | View Details |
| AI and ML Certification Courses | Every Weekend | View Details |
Fdeep-lear