Arthur Samuel first explained 'Machine Learning' in 1959, calling it a 'Field of study which provides the computer system with the capability to learn without being explicitly programmed.' And no one could have said it better.
When I first came across this definition, it felt theoretical. But as I started working with real datasets and simple models, the meaning became very real. Watching a model improve its predictions without hard-coded rules was the moment ML truly clicked for me.
Machine learning is a growing career skill that includes computer science, data analysis to allow computers to learn from data and statistics. While stepping in 2026, the seriousness of ML keeps rising. And this is what makes it an important skill for the ones seeking to stay relevant in the tech industry.
The demand for machine learning skills has reached the sky. Even The World Economic Forum's Future Jobs Report shows that by 2030, 77% of the employers are planning to emphasize reskilling and upskilling their workforce to improve collaboration with AI systems.
In this blog, I am going to direct my focus towards understanding how to learn machine learning in 2026. Being a leading technology today, the future prospects look great and exploring the field today will ensure a good tomorrow. This article will explain in depth on how to learn machine learning, from essential skills to technologies needed to be understood. Before I go forward, let's dissect - what is machine learning?
Machine learning is the field that works with data analytics techniques to train computer systems to take actions, learn, and change in a natural flow, similar to humans. Machine Learning algorithms employ computational methods for directly learning information from the data in hand. Hence, there is no dependency on a predetermined equation.
Machine learning is a fragment of artificial intelligence with specks of computer science. It places direct focus on using algorithms and data to make the computer imitate the way humans learn. It also includes identifying patterns in data and making predictions without being directly programmed to perform particular tasks.
Explore igmGuru's Machine Learning Course program to learn Artificial Intelligence with industry experts.
Before I move to how to learn machine learning in 2026, you must understand why to learn machine learning. Here are some of the top reasons to learn machine learning in 2026 -
In my journey, this became clear when I worked on small projects that turned raw data into actionable insights. Even simple models helped me understand how ML quietly drives decisions behind dashboards and automation tools.
Leveraging machine learning enables organizations to make better decisions without the need to have any human intervention. It facilitates organizations to gain a better understanding and view of the trends going on business operations and customer behavior. This also aids in bringing forth new products and services.
I personally noticed this demand while exploring job descriptions and learning paths. Almost every data-related role I reviewed had machine learning listed as either a core or preferred skill.
The demand for machine learning skills is reaching the sky day by day all over different sectors. Its desire is rising in sectors like finance, healthcare, technology and e-commerce. Understanding this industry and developing the related capabilities will improve and give more exposure in the knowledge base and one can become a great asset to any company.
The demand for ML experts is rising at a steady pace. Many big names like Google, Facebook, Twitter, Uber, etc. have moved towards it. The salary packages for ML professionals are highly competitive. The opportunities are not limited to any one area or sector. You will benefit from global opportunities in all top industries.
As the ML field is pretty powerful especially with continuous developments and latest techniques. Learning this will provide you with the skills to stay up to date and adapt to the coming technological changes.
Also Read- Reasons Why Python is Good for AI and Machine Learning
From my own experience, progress was not linear. Some concepts took weeks to settle, while others made sense instantly once I applied them in a project. Consistency mattered more than speed.
The path for mastering machine learning depends mainly on one's approach. The timeframe can depend vastly according to the existing knowledge, resources and commitment level for self-learners.
To learn machine learning, it may take a few months to more than a year to get a strong grip of ML principles, programming (specifically Python), mathematics and a number of algorithms. With the aid of self-directed online courses, tutorials and active projects, one can speed up the process of understanding machine learning more.
Choosing a formal education like a university degree in computer science, data science or related areas includes a three to four year commitment. These online programs provide detailed and thorough training in ML along with the associated subjects. Here are the levels one must understand to learn machine learning-
Nevertheless, the chosen path, the main principle to success in machine learning is the constant learning, practical implementation and staying updated with the latest field developments. Must remember that machine learning is a career of lifelong learning, with new technologies and methods that are constantly being created.
Related Article - Machine Learning Tutorial: A Guide For Beginners
Having an understanding of how ML works includes a step-by-step procedure that changes the raw data into valuable insights. Here is a breakdown of this procedure -
I learned very early that poor data leads to poor models. Some of my initial projects failed not because of algorithms, but because the data itself was incomplete or biased.
Collecting data is the first and foremost step in the machine learning procedure. Data is the whole soul of ML, the quality and quantity of the data can directly impact the model's performance. Data can be derived from multiple sources like databases, text files, images, audio files or even from the web.
After the data collection, data is required for the preparation for machine learning. This procedure includes organizing the data in a well-suited format like a CSV file or a database. It is ensured that the data is relevant to the problem we are trying to solve or not.
Overfitting was one of my biggest early mistakes. Models looked great on training data but failed badly in real scenarios, which taught me the importance of validation and testing.
This step is an important step in the machine learning procedure. It includes cleaning the data (removing duplicates, correcting errors), managing missing data (by removing or filling it) and normalizing the data (scaling it to standard format).
Data preprocessing makes the quality of the data better and ensures that the ML model can interpret correctly. This step is basically for improving the accuracy of the model.
After the data preparation, the next stage is to choose a machine learning model. There are many kinds of models to pick from, involving linear regression, decision trees and neural networks. One's choice varies depending on the nature of the data and its problem that needs to be solved.
Things to keep in mind while picking the right model involve the size and the type of data, the depth of the problem and the computational resources that are available.
After picking up the model, the next stage is to train it with the prepared data. Training includes feeding the data into the model and letting it adjust its internal parameters for a better prediction of the output.
While training, it is important to avoid overfitting (the model performs well on the training data but badly on new data). And underfitting must also be avoided as this is where the model performs badly on both the training and new data.
After the model is trained, evaluating its performance on unseen data is important before deploying. Through MLOps, monitoring won't stop at the initial stage, it includes ongoing evaluation for detecting model drift and managing model quality with time. Constant monitoring and retraining workflows aid companies in making sure that their models stay effective and reliable in production environments.
The common metrics for the evaluation of a model's performance involve accuracy for differentiating problems, precision and recall for binary classification issues and the mean squared error for regression problems.
Even beyond the tuning for accuracy, hyperparameter optimization in an MLOps pipeline involves tools. These tools are for automated hyperparameter searches, making sure of efficiency and reproducibility. A lot of teams employ MLOps platforms, which support hyperparameter tuning so that experiments can be repeated and well documented. This leads to consistent optimization with time.
The techniques for hyperparameter tuning involve grid search, in which we try out different combinations of parameters and cross-validation is when we divide the data into subsets and train the model on every subset to make sure it does well on different data.
Deployment of a machine learning model includes integrating it in a production environment, here it can give real predictions and insights. MLOps has come as a standard practice for smoothing this procedure. It is surrounded by version control, monitoring and automated testing to make sure models are reliable, reproducible and powerful. MLOps frameworks such as MLflow, Kubeflow support these aims by giving smooth workflows for deployment, retraining and model rollback if problems arise.
Read Also- 10 Best Python Libraries for Machine Learning
Working hands-on with ML helped me realize it’s not about replacing humans, but about amplifying human decision-making with speed and scale.
In the century we are in today, data is the new gold and ML is the engine that gives strength to this digital world. It is an essential technology in this digital era and its importance can never be exaggerated and here is why it is important.
This is among the major reasons why machine learning is important, as it is capable of handling and making sense of massive volumes of data. Through the explosion of digital data from social media, sensors and other resources, traditional data analysis methodologies have become insufficient.
Machine learning algorithms can run large amounts of data, exposing hidden patterns and giving essential insights that aid in the decision-making process.
This field is driving innovation and efficiency all over multiple sectors, some of them are -
Healthcare - Algorithms are for predicting disease outbreaks, customizing patient treatment plans and improving medical imaging accuracy.
Finance - This is used for credit scoring, algorithmic trading and fraud detection.
Retail - With machine learning, recommendation systems, supply chains and customer service can be very beneficial.
These techniques can also find applications in diverse sectors like agriculture, entertainment and education.
This field is a main enabler of automation. Through learning from data and getting better with time, machine learning algorithms can do previous manual tasks. This lets humans work freely and concentrate more on complex and creative tasks. It not only increases efficiency but opens the door for new opportunities and possibilities for innovation.
Read Also- 10 Real-Life Machine Learning Examples
ML jobs come with big fat paychecks, but the salary depends on the location, industry, experience level and job responsibilities. As we know, this is a highly sorted skill in today's tech field. Professionals in this field who possess expertise are very much in demand nowadays. The salaries for this job are usually higher than the other software development or data analysis roles. The average salary for jobs in this field vary from $110k to $171k. Even the job market for ML is pretty competitive and the demand for these roles can vary according to the industry's trends and technological developments. Some of the jobs in machine learning and their respective average salaries are -
As we can see on the above report, how rapidly machine learning jobs are rising in number way better than any other job.
Read Also- Top 10 Machine Learning Frameworks to Use In 2026
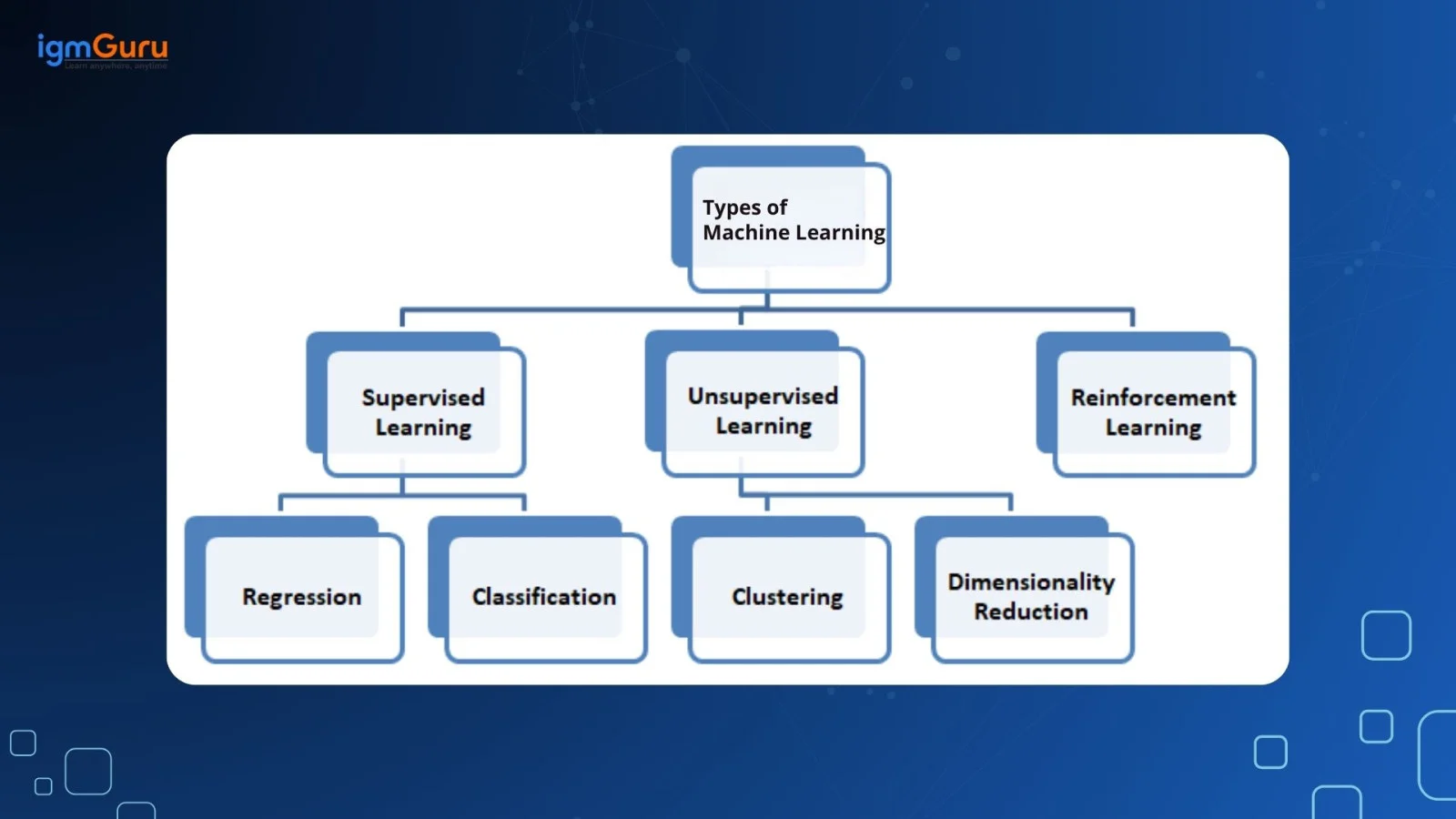
Understanding these types became easier once I implemented at least one small project for each. Theory alone wasn't enough- practice made the differences obvious.
There are four types of machine learning. Having knowledge about these before you begin to explore this field will help you understand things faster. Let us look at the types of machine learning to understand them better.
Supervised learning means that data scientists provide the algorithm with labeled training data, and then define the variables. The goal is to allow the algorithm to assess correlations and learn accordingly.
Unsupervised learning means that the algorithm is trained on unlabeled data. This ML algorithm scans through datasets to search for any meaningful connections. The data, which the algorithms are trained on and offer predictions on, are predetermined.
A semi-supervised learning algorithm involves a mixture of the two preceding types. Here, data scientists might feed an algorithm, which is usually labeled training data. However, the model is free to explore the data on its own and develop its own understanding of the data set.
Reinforcement learning consists of data scientists using well-defined rules to train a machine on how to complete a multi-step process. Data scientists program an algorithm to complete a task and insert it with positive or negative cues, leaving it to work out how to complete the task. The goal of reinforcement learning is to learn the best policy.
Also Read- Top 40 Machine Learning Interview Questions and Answers
Plunging into ML is an exciting journey with many complexities on the way too. But through a clear plan, steps, relevant resources and an orderly approach. To reach the desired end goal, one must diligently set out to learn everything that is important in this sector.
According to The World Economic Forum, it predicts a 40% rise in the demand for machine learning and artificial intelligence professionals between 2023 to 2027. The growth is rising because of the increased integration of AI and ML technologies all over multiple industries. The steps given below will give a detailed understanding on how to learn machine learning.
I didn’t master all prerequisites at once. I learned statistics, math, and programming side by side with ML concepts, revisiting fundamentals whenever I felt stuck.
Before getting into the field of machine learning, then these are some of the prerequisites you need to know about. These are essential to get started with the applications and theories of ML.
Having a hold of the principles of statistics improves the grip of machine learning. The capability to analyze data and derive meaningful insights is indispensable in this area. Being familiar with concepts like statistical significance, distributions, regression analysis and probability predictions is the main answer to applying multiple ML techniques successfully.
All of the machine learning algorithms are applied with code. So, having programming skills in Python, Java, R or Bash are a must for anyone who wants to become a machine learning engineer. Through these years, Python has become one of the most famous programming languages especially for freshers. This has a simple syntax, broadly built-in functions, well-supported libraries and a vast package support.
Calculus and linear algebra are both combined to machine learning. ML is rooted deeply in math principles. One doesn't need to be a math prodigy to excel in machine learning. Like, having a basic knowledge about matrix operations and linear transformations in linear algebra is important for looking through ML and deep learning algorithms.
You do not need to have a PhD in any of the above-mentioned topics, but a good understanding to get started with machine learning. The requirement of working with large volumes of data is vital to get more experience. Before designing or choosing a model for data analysis, the need for cleaning one's data (data wrangling) and the structure of the whole set is essential.
The data structures are pretty much important for skillfully storing, accessing and manipulating data in ML. A strong hold of arrays, lists, trees and graphs with their algorithms can remarkably improve and refine the performance of ML models.
This includes cleaning, changing and preparing data for analysis. This is an important skill for ML due to the quality and format of data directly impacts the performance of models.
This is a subset of machine learning that includes training deep neural networks. Deep learning skills are basically relevant for complicated tasks such as image and speech recognition, natural language processing and more.
These skills are necessary, especially when it comes to the deployment of ML models in a production environment. This involves having knowledge about control systems like Git, continuous integration and delivery (CI/CD) practices, containerization technologies like Docker and orchestration tools such as Kubernetes. Being familiar with cloud services like AWS, GCP or Azure for deploying and scaling applications and understanding of APIs and web services is also important for the integration of ML models in the existing software systems.
Having knowledge of business implications of ML solutions is important for delivering value. This includes having a good grip on how ML can solve real business problems, improving efficiencies, and driving innovation.
Once you are done with the prerequisites, you can move on to actually learning ML, by beginning with the theories. It's better to start with the basics and then further move to more complex things.
While starting any ML/AI project, start with planning for the type of events that are being detected and the metadata that will be captured. This procedure usually begins with collecting a small amount of training data which can be used for validating the results as a proof of the concept. Both the continuous (status) events and trigger events should be explicitly defined before data collection and validation take place.
Model interpretation in this field looks for understanding the model's procedure of decision-making. This orderly evaluates the fairness, reliability, trust and causality of the model results. Basically, it helps answer questions like ‘how reliable are the model's predictions?' or ‘are they honest enough to shape major policies and decisions?' The two major paths for interpreting ML models are model-specific/model-agnostic methods and local/global scope methodologies.
All the ML models make use of particular guesses to make predictions. Linear regression, logistic regression, decision tree, random forest, KNN (K-Nearest Neighbors), support vector machines (SVM) and other models are based on a few fundamental axioms or assumptions about the behavior and nature of the data. These usually cover the relations between the independent and dependent variables, distribution, autocorrelation, multicollinearity and outliers.
Refining the accuracy of the model is important to the overall project's success. The model's predictions require a low error range and perform well with multiple problem variables. Whereas, some methods trade with cleaning and filtering the data more effectively. Whereas others recommend varied strategies for improving the performance of the model with the latest, unused data. Methods like cross-validation, feature engineering and algorithm/hyperparameter tuning are well known choices for uplifting the model's precision.
This is the procedure of formatting raw data to be processed by a ML model. Data processing involves particular steps to change or encode the data for easy examination by the machine. This refines the accuracy and efficiency of the model through minimizing data noise, missing values and unstable formats or system handling errors. The preprocessing steps also define the suitable splitting of the dataset in training and test sets.
While building ML models for clients, the most complicated aspects are data collection, integration, cleaning, and preprocessing. So, it's really important to practice these as you will be working with a humongous amount of data.
Once you are aware of the key underlying concepts, you have come to the point where you should tap into the essential topics, reasoning, and capabilities. Here are a few things you must certainly begin with.
The ML pipeline begins with cleaning filtered data which has been used for parsing. Even machine learning engineers spend a substantial amount of time wrangling data to make sure that incomplete or noisy data does not damage the model's accuracy. Once the data is split into training and test sets, the preliminary code can be made. This involves model engineering, evaluation and wrapping.
One needs experience on real data to strengthen their skills. All the real data is somewhere flawed and so it gives an amazing opportunity to learn about the typical problems and solutions related with data manipulation.
It is important to keep the bigger picture in mind while learning ML from the basics. It is not enough to hold just the basics of a programming language. One needs to learn about the different tools and packages which are relevant to ML/data science. For instance, if someone is learning Python, then they will need to gain a strong understanding of data analysis, manipulation and visualization tools in pandas and NumPy.
After refining your portfolio and going deep in specializations, you must consider how your expertise can be of value in an organization. Get included in a community-driven learning system like competitive coding. This will keep you up to date with the in-demand skills and the current developments in the industry.
There are plenty of ML tools today that can be learned from. Whether you are searching for data preparation and collection, application deployment, or model building, there is a tool for it all. Some of the most trusted tools for machine learning/ artificial intelligence include -
There are plenty of free machine learning tutorials online, along with blogs and videos. However, nothing can match the training level of a structured machine learning course that is crafted and taught by industry experts.
Since there is a very high demand for ML professionals, it has become important to do something different to stand out among the crowd. Enrolling in a machine learning training offered by a trusted learning platform is certainly a good step. An online program is definitely a better option as it gives you unprecedented flexibility while saving you a lot of time.
This is the last step one must take before applying for machine learning jobs is a secure internship. Employers and hiring managers always go for candidates who have experience in this field. Getting an internship is an amazing opportunity to make connections via networking and getting the inside knowledge about this industry.
Try getting internships in the industry as per your choice. Applying indiscriminately for any or all open positions will lead to more rejections. Must make a professional resume and portfolio for the role being applied for.
Before giving out applications, take your time in going over the skills and qualifications given in the job descriptions. This will give a clearer picture of what employers in this industry are looking for. Make sure to demonstrate your grip of the theoretical and technical aspects of machine learning projects and big systems. Making a presence on community websites like GitHub and Kaggle will also aid in networking while you design an impressive portfolio. The expertise in converting a business problem into an ML system, then you are ready to be in contact with the ML recruiters.
Now that you know what machine learning is and how to learn it, it should not be a big deal to get started. All you need to do to begin your journey to success is to choose the right resources for learning, at the very beginning.
To keep growing, learning continuously and practical application is the main key. Must stay curious, love the challenges and leverage the community for support and inspiration. The path of machine learning is unique, keep working on your learning to fulfill your goals and interests. Whereas, the salary numbers of ML engineers itself is a testament to the kind of demand ML engineers and other related professionals can witness today and in the coming years. With consistency and dedication, you will find your place in this fluid industry of machine learning.
Absolutely, yes it can be possible to learn machine learning without Python.
The developments in natural language processing makes machine learning more user friendly than the traditional AI text chatbots.
There is absolutely no doubt in this, anybody can learn ML on their own. It might seem overwhelming but it's very much possible to self learn ML. With the help of a proper amount of free and paid resources available online, one can develop a proper knowledge of machine learning, all by themselves.
Course Schedule
| Course Name | Batch Type | Details |
| Machine Learning Training | Every Weekday | View Details |
| Machine Learning Training | Every Weekend | View Details |