Working in the field of data paints a clearer picture about the amount of data that gets generated on a daily basis. A shared platform further integrates and stores this data so that different departments can use it. This common platform is a data warehouse where data transformation happens for extracting meaningful information. This data warehousing tutorial is a guide for beginners to understand this platform and process in depth.
This data warehousing tutorial covers a detailed insight into this process. That means learning about data warehouses, their architecture, components, characteristics, advantages and disadvantages. It is a process that is at the core of the business intelligence system and leads to making better decisions.
Explore igmGuru's Data Warehousing Training Course Online.
The first question to uncover here is what is a data warehouse. DWH is a central storage of data that can be easily analyzable for making great business decisions. Data regularly accumulates here from relational databases, transactional systems and other sources. Business analysts, data scientists, data engineers and decision makers access this data by using different business intelligence and data analysis tools.
Before diving into the concepts and technicalities of data warehousing, it is important to have a foundational understanding of certain topics and skills. These prerequisites will help you grasp the concepts more easily and effectively apply them in real-world scenarios.
There are certain characteristics of a data warehouse that make it such a valuable tool. These key characteristics mold the way different companies use it for their benefit. These four aspects are the most important ones.
Related Article - Top Five Data Visualization Tools
The data warehousing architecture is three-tiered for efficiently and quickly processing data. The three tiers are bottom, middle and top. Each of these have a distinct function to serve and is used by skilled developers. This section explores each of these in brief.
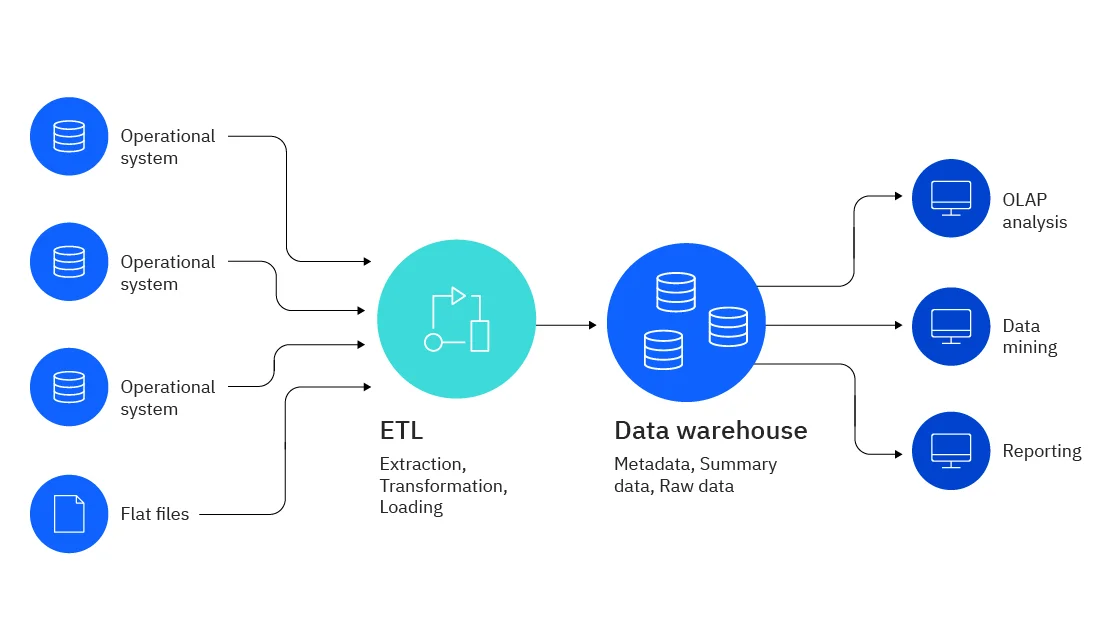
Data flows here from different data sources into a DWH server for storage. This data usually goes through the ETL (extract, transform, load) or ELT (extract, load, transform) process. They are executed differently but still use automation for moving the data into a warehouse and preparing it for analytic use.
The middle tier is usually built around an analytics engine that is an online analytical processing (OLAP) system in most cases. This system delivers rapid analytics and query speeds. This tier may use these three types of OLAP models according to the type of DB system in use -
The top tier has a frontend user interface (UI) or reporting tool for conducting ad hoc data analysis on business data. Self service BI has many different uses like identifying new opportunities or process bottlenecks. It also generates reports according to the historical data.
Related Article - A Guide To Data Science Learning Path
Most of the DWHs are built atop relational database systems in the cloud or on premises. Data storing and processing happens here. There are different data warehouse components to learn about for a complete understanding of these electronic platforms.
Data layer is also called the central database and is at the heart of the DWH. All other components support it with data being inserted from email lists, websites, business apps and other RDBs. It divides data segments so that users are able to access only the needed data.
ETL tools move data from the source to the DWH through all processes of extraction, transformation and loading. They convert data into a consistent format for efficient querying and analysis. Apache Spark is a data processing tool that manages this transformation.
There are a few DWHs with a walled off sandbox from live data. This sandbox is useful as a testing environment that contains relevant data analysis and visualization tools. Data professionals experiment with different new analytical techniques since the impact does not reach other users.
These tools connect with a DWH for a business user friendly frontend. It may encompass reporting, dashboards and data visualization tools so that business users and data analysts can interact with data for bringing out useful insights. Tableau, Qlik and Looker are three of the most widely used access tools.
Metadata is basically data about the data that is stored in the system. It has characteristics like dates, locations, authors, file sizes and much more.
Warehouse pulls data from different organizational sources with this connectivity layer for APIs.
Learning key data warehousing terminology is crucial for understanding how businesses store, manage and analyze large datasets. It will make you capable of performing better decision-making and driving business growth.
Business intelligence is the process of collecting, storing, analyzing and presenting business data in a way that improves the growth of organizations. Data warehousing is the foundation of BI that provides a centralized and structured repository of data. This information is then visualized on intuitive reports and dashboards through different BI tools.
ER modeling is a method of representing data objects and their relationships in a graphical format. It is a foundational technique of designing databases for understanding complex systems and defining logical database structures. It involves using ER diagrams with symbols like rectangles for entities, ovals for attributes and diamonds to illustrate relationships between them.
Data analysts and software engineers use ER models to understand and organize information before creating the actual database. These models define the schema of the data warehouse by identifying the key entities and their relationships. There are various types of ER models available including:
Dimensional modeling is a technique that organizes data into Facts (quantifiable data) and Dimensions (descriptive data). This technique optimizes data storage and retrieval for analytical purposes, making it easier for experts to query and understand the data.
Implementing dimensional modeling includes the following steps:
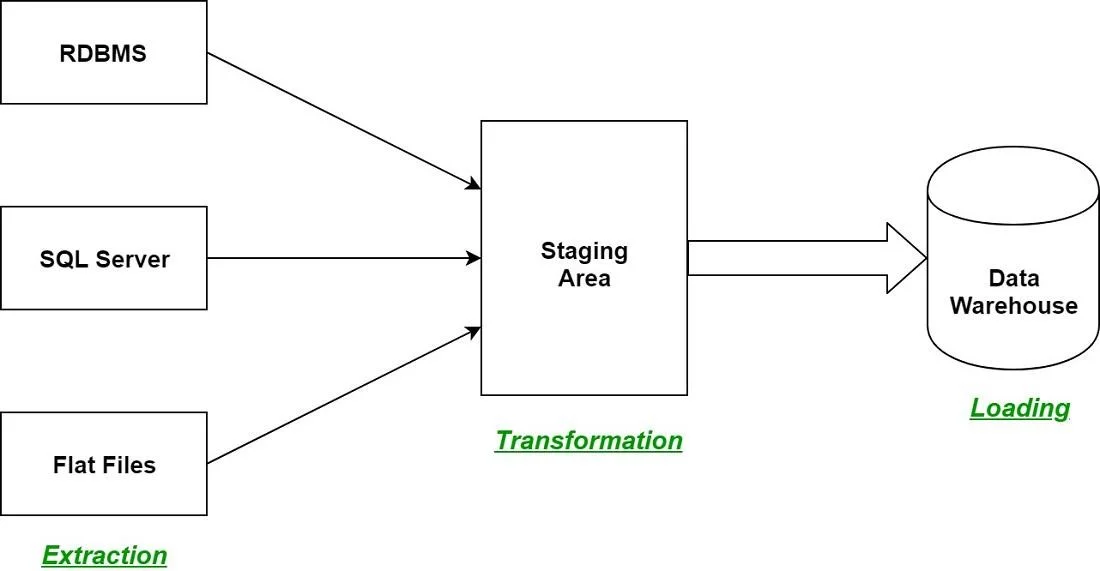
The term ETL is derived from the three phases it involves; Extract, Transform and Load. Each of these phases works on different tasks including extracting information from a variety of sources, transforming it into a usable format and loading it into the centralized store. It can even consolidate vast amounts of data for organizations, enhancing decision-making processes and enabling accurate business insights.
Cloud and on-premises are two different types of data storage systems. The distinct in the following aspects
| Aspects | On-Premises Data Warehouse | Cloud Data Warehouse |
| Definition | Hosted on in-house hardware | Hosted on cloud provider's infrastructure |
| Control | Full control | Shared control with the provider. |
| Scalability | Limited; requires hardware purchase. | Elastic; scales on demand. |
| Cost | High CAPEX (upfront) | OPEX (pay-as-you-go) |
| Management | In-house IT management. | Provider manages infrastructure. |
| Security | In-house security management. | Shared responsibility |
| Latency | Potentially lower (local) | Varies; depends on network |
| Flexibility | Less flexible | Highly flexible and agile |
| Deployment | Slower, complex deployment | Faster, simpler deployment |
| Maintenance | In-house maintenance and updates | Provider handles maintenance and updates |
| Pros | 1. Local processing potential 2. Full control over security 3. Leverage existing infrastructure | 1. High scalability 2. Lower upfront costs 3. Simplified management 4. Access to advanced analytics |
| Cons | 1. High upfront costs 2. Limited scalability 3. Significant IT resources 4. Slower deployment | 1. Potential latency 2. Less infrastructure control 3. Shared security responsibility 4. Possible increase in cost over time |
Advanced SQL queries go beyond basic database manipulation techniques by optimizing them for efficiency and reliability. It includes different SQL concepts, such as recursive queries, common table expressions (CTEs), pivoting, subqueries, self-joins and more. The following are the common types of advanced SQL queries:
Data visualization principles define the criteria of how a visualization should be. Effective visualization helps to convey the information effectively and accurately. Some common principles are clarity, simplicity, purposefulness, consistency, contextualization, accuracy, visual encoding, intuitiveness, interactivity, aesthetics, accessibility and hierarchy.
Integrating Hadoop and Spark with DWH is a crucial aspect of modern data architecture. It allows organizations to use the strengths of each technology. Hadoop provides data ingestion and staging capabilities, whereas Spark provides data transformation and processing capabilities.
In this integration, Hadoop acts as the initial landing zone for raw data, Spark transforms and prepares the data and DWHs provides the optimized environment for analysis and reporting. Performing this integration involves the following steps:
Predictive analytics is the process of finding underlying patterns from historical data using machine learning and data warehousing. It aims to give insights into potential future actions, enabling organizations to make more informed decisions. DWH supports predictive analysis with the following features and techniques -
It stores and manages large volumes of data from different datasets. This means users will access information whenever they want.
It integrates different data sources to provide a comprehensive view of the business.
This technique ensures information is clean, reliable and ready for making predictions.
Its capability to manage large datasets and complex queries makes it suitable for predictive analytics tasks.
Different types of data mining techniques including classification, clustering, regression and anomaly detection are used in DWH. It helps to find valuable insights and patterns from humongous datasets. Data scientists, analysts and business intelligence professionals use this technique to perform their tasks. It is mostly used for credit risk management, fraud detection and spam filtering.
Data warehousing is time variant, integrated and subject oriented. It has many different benefits for enterprises that use it for different business purposes. Let's uncover some of the top advantages of data warehouses for a better understanding.
Data is converted into a standard and common format. Different organizational departments produce well-formed and commensurate results with no discrepancy in any way.
Having all the data together in a place saves time during search and when making decisions. Executing a DWH doesn't need a lot of IT support or multiple channels. There is no time lag or any sort of reliance on any external sources.
Companies that invest in this process usually generate higher revenue and return on investment. The outcome is beneficial for everyone involved in the business.
Data is accessible and analyzable from different sources because of different data warehousing processes and techniques. Businesses make intelligent business decisions since data is not constrained to any particular section. They are directly implemented in financial management, marketing, inventory management and sales.
DWH stores historical data to keep the users and companies updated on the conventional trends and customs that change with time. Businesses track data from different time eras and proceed accordingly in the future.
Related Article - How To Become A Data Analyst
There are certain limitations or disadvantages of data warehouses that one should know about. Knowledge about these limitations will let the user know when to find an alternative or be extra cautious. The must know disadvantages are -
The similarity and standardization of data formats may make the data inflexible and homogeneous. The limits the data when forming relations during aggregation or when tuning it for query speed.
It demands different data resources for managing and handling data from different sources. This increases the costs and also affects the cost/benefit ratio. Companies can however, optimize this cost.
Data Warehousing works closely with OLAP (Online Analytical Processing), while business applications mostly rely on OLTP (Online Transaction Processing). Both may look similar at first, but they serve very different purposes. The simplest way to remember this is:
| Feature | OLAP | OLTP |
|---|---|---|
| Purpose | Data analysis & decision-making | Day-to-day transaction processing |
| Database Size | Very large (historical + aggregated) | Comparatively smaller & real-time |
| Query Complexity | Complex queries for reporting | Simple queries for quick execution |
| Speed Focus | Read-heavy, optimized for analysis | Write-heavy, optimized for transactions |
| Data Updated | Periodically (batch or scheduled) | Constantly and rapidly |
| Usage in Data Warehouse | Mainly used | Not common — but can feed the warehouse |
In short, OLTP is the operational engine, while OLAP is the analytical brain. Businesses usually start with OLTP systems to run activities smoothly, and as data grows, they bring in OLAP to generate insights, patterns, and strategic decisions. Both are essential, just used in different moments of the data journey.
Explore the differences and similarities between Data Science and Machine Learning.
This data warehousing tutorial is a complete guide for beginners with an interest in this process. This process is behind unprecedented industrial growth, with its ability to manage and work with gigantic data. Data warehouses have an integrated, high-performance and centralized data repository to push organizations towards great decisions.
The demand for warehouse automation is also on the rise. The global warehouse automation market was around $23 billion USD in 2023 but is forecast to reach $41 billion USD by 2027. It is expected to register a CAGR of approximately 15%. This is a huge growth percentage and directly reflects the growth potential and scope of this field.
This itself is a free data warehousing tutorial for beginners and a learning guide for a basic understanding of this process.
It is not a DWH but a programming language for managing and manipulating data in relational databases.
The three DWH models are data mart, virtual warehouse and enterprise warehouse.
It mainly helps businesses analyze historical data and make better decisions.
Common tools mainly include ETL tools, SQL databases and reporting tools.
Course Schedule
| Course Name | Batch Type | Details |
| Data Science Courses | Every Weekday | View Details |
| Data Science Courses | Every Weekend | View Details |