Want to know what RAG (Retrieval-Augmented Generation) is and how it can help you? You have come to the right place. I have designed this comprehensive RAG tutorial that will help you understand how this AI approach is used to improve machine understanding and response accuracy. It aslo explain how to combine a retrieval system with a large language model (LLM) and get more accurate and up-to-date responses.
You will learn the complete process on how it retrieves relevant information from an external knowledge source before generating a response and more. This way, your AI systems will provide specific, verifiable answers instead of relying solely on the data they were originally trained on. Then why wait? Let’s begin!
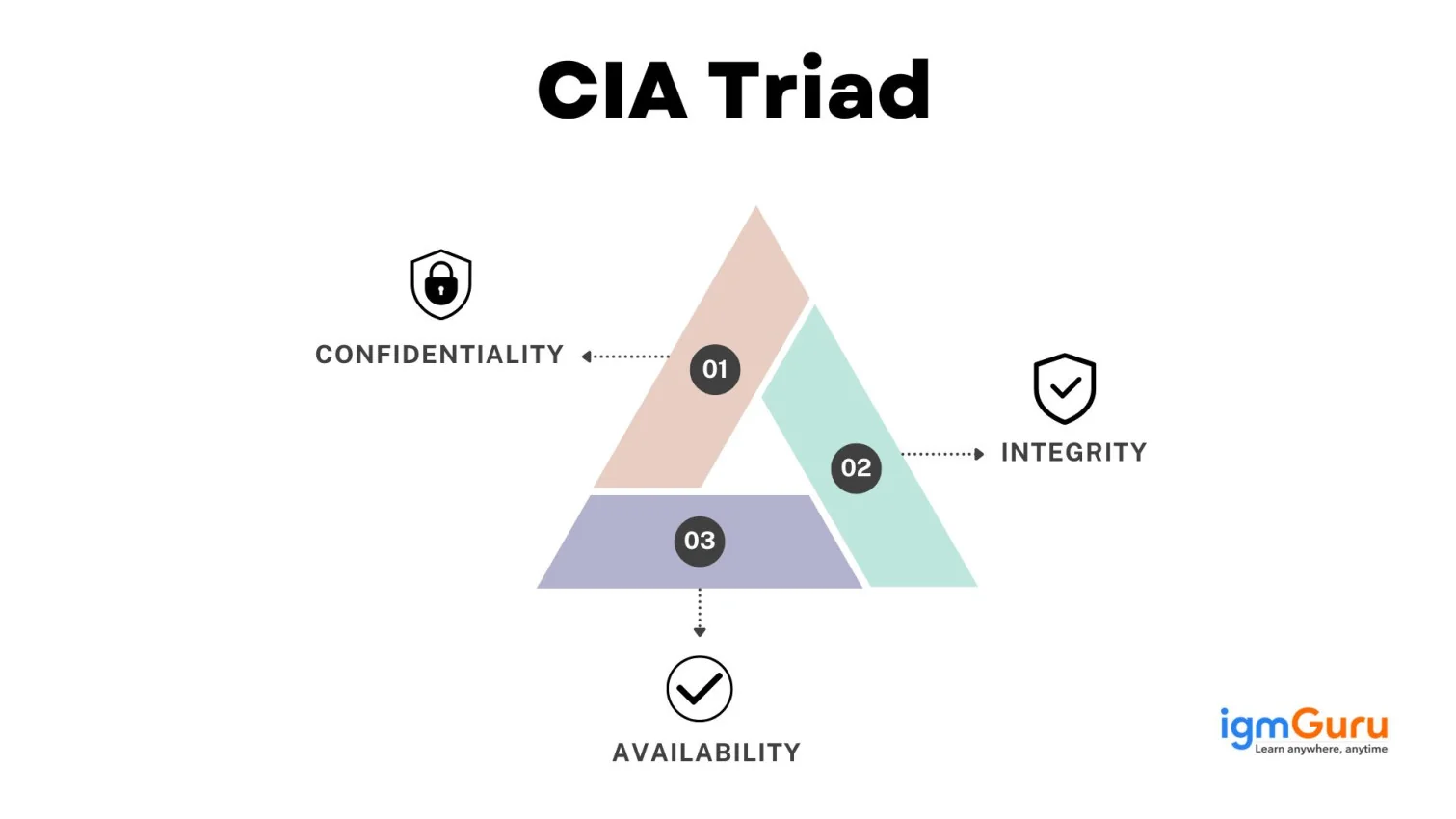
RAG is a technique that combines a pre-trained large language model's (LLM) capabilities with an external data source. The generative power of LLMs (like GPT-3 or GPT-4) is combined with the expertise of specialized data search mechanisms. The outcome is a system that offers nuanced responses.
Enrol in igmGuru's Generative AI course program to accelerate your career growth.
The next stop in this RAG tutorial is to learn about the importance of RAG in AI and machine learning. LLMs are the base of AI technology and power intelligent chatbots and other NLP applications. Bots that are able to revert to user questions in different contexts by cross-referencing trusted knowledge sources are created.
LLM technology's nature introduces unpredictability in the responses. Its training data is static with a cut-off date on its current knowledge. Many challenges are faced including -
RAG can be a big help in solving some of these challenges. The LLM is redirected to fetch relevant information from trusted and predetermined knowledge sources. This gives companies more control over the generated text output.
There are a few core concepts of RAG that must be learned for optimally using this technology. This RAG tutorial covers the basic concepts and aspects that are central to it and a must know.
| CONCEPT | DESCRIPTION |
| Understanding RAG | It represents an important advancement in AI language models as it integrates static pre-trained knowledge and dynamic external data retrieval together. It includes two key processes - retrieving information (by carrying out concentrated searches in a huge database) and generating responses (by integrating the extracted info with current knowledge). |
| The benefits | The system's ability to offer context-relevant, updated and coherent answers for different tasks is improved. These include article writing, chatbot dialogue and answering questions. It makes the system adaptable to many different applications. |
| Comparison of RAG and model fine-tuning while building own model | Both processes include evaluation of factors like resource requirements, adaptability and complexity. Retrieval Augmented Generation is great at real-time data integration and using fine-tuning for a balance between ease of use & adaptability. Building custom models is better for highly concentrated tasks and extensive research. |
| The reasons behind model hallucination | Model hallucination occurs in language models when artificial intelligence generates fabricated or inaccurate information. It could be due to incomplete or biased training data, hefty level of specialization in training data, insufficient real-world understanding, inability to fact check in real-time or difficulties in understanding complicated language structures. |
| Use cases/ applications for retrieval-augmented generation. | It improves chatbot accuracy in customer service, tailors e-commerce experiences and aids in content creation. Finer decision making is seen in education, legal research and healthcare. |
| Challenges | There are certain technical challenges in - - Managing complicated datasets. - Integrating retrieval and generation components. - Operational challenges in system maintenance and scalability. - Ethical challenges related to data privacy and biases. |
| Best practices | Sustainable and successful implementation of this technique is possible with - - Regular diversification & updation of data sources. - Continuous performance & training monitoring. - Robust infrastructure for high scalability. - Ethical considerations with respect to regulations and data privacy. - User friendly design for better interaction. - Collaboration with experts. - User feedback. |
Retrieval Augmented Generation framework combines the strengths of information retrieval and generative language models. It does not solely rely on the knowledge embedded within their parameters. It retrieves relevant information from an external knowledge source to generate more accurate, informative and grounded responses. Here are the core components -
At the heart of this framework lies an external knowledge source. This can be a vast collection of documents, a knowledge graph, a structured database or any repository of information relevant to the tasks the LLM will handle. The key is that this knowledge is separate from the LLM's training data and can be updated or expanded independently.
When a user poses a query, the retrieval component is responsible for identifying and fetching the most relevant pieces of data from the knowledge source. This typically involves -
Once the relevant context is retrieved, it is then fed into a large language model along with the original user query. The LLM then uses both its pre-existing knowledge and the retrieved information to generate a response. The crucial aspect here is that the LLM's generation process is augmented by the retrieved context.
The way the retrieved information is presented to the LLM is critical. Effective RAG systems contextualize the retrieved documents with the original query. This might involve
While the retrieval and generation components can be trained separately, some of its advanced approaches involve end-to-end training. This means fine-tuning the entire system to optimize the quality of the generated responses based on the retrieval process. This can lead to better alignment between the retriever and the generator.
The number of steps to set up a RAG model can vary highly. A simple model can be set up with these steps -
Related Article- Generative AI Interview Questions
There are quite a lot of applications of RAG that have come forth in the recent years. This technology has gained a lot of momentum and is being used globally in different domains. Some common uses are:
RAG-powered systems are great in dealing with question answering scenarios. They give context related and detailed answers from their elaborate knowledge bases. They promote more engaging and informative interactions with users.
Professionals in the legal field can use these models for streamlining document review processes and conducting legal research in depth. It summarizes case law, statutes and other legal documents that leads to saved time and better accuracy.
Educational tools are improved as students are given access to explanations, answers and more context according to reference materials and textbooks. The outcome is more effective learning and understanding.
The context in knowledge bases is considered for improving language translation tasks. Translations are more accurate in relation to specific domain knowledge or terminology.
These models work as highly valuable tools for medical professionals and doctors in the healthcare domain. Access is given to the latest clinical guidelines and medical literature for more accurate diagnosis and even treatment recommendations.
While learning RAG, you may have heard of fine tuning. Fine-tuning and RAG are both techniques used to improve the performance of Large Language Models. Therefore, most of the individuals get confused in their learning journey. Let's understand their differences.
| Feature | Fine-Tuning | Retrieval-Augmented Generation (RAG) |
| Role | Modifies the model's internal weights using domain-specific training data | Uses external documents retrieved at runtime to inform the model's response |
| Use Case | Ideal when consistent, task-specific behavior is needed | Ideal for dynamic, up-to-date, or large knowledge bases |
| Data Dependency | Requires a large, curated dataset for training | Requires a robust search index or vector database |
| Update Flexibility | Inflexible - needs retraining for any updates | Highly flexible - update external data without retraining |
| Response Explainability | Less explainable - output comes from internal model knowledge | More explainable - responses often reference retrieved documents |
| Storage Requirements | High - needs resources to store and train updated models | Moderate - relies on document store and retrieval pipeline |
| Latency | Faster at inference once trained | Slightly slower due to retrieval step before generation |
| Cost to Implement | High - involves compute-intensive training | Lower - uses existing model and focuses on retrieval |
| Examples | Custom chatbot trained on internal company policies | Assistant that looks up real-time product specs or support docs |
| Maintenance | Complex - model must be re-tuned for changes | Simple - update the external knowledge source |
Retrieval Augmented Generation is at present the best technique to use LLMs' language capabilities alongside a specialized database. Some pressing challenges that arise while working with language models are addressed by these systems. They also give an innovative solution in the NLP field and it's all covered in this RAG tutorial.
These systems give the language model the capability to present updated and accurate info with source attribution.
Its purpose is to present the latest statistics, news and research to the generative models.
Answer - Of course you can. It is the best method to start learning this technique as a beginner. It starts from the very basics and covers all the practices of this technique.
Answer - Most of the RAG tutorials expect that the student has the basic understanding in programming, machine learning and NLP. This means individuals should be proficient in these fields before joining this type of training.
Yes, AI beginners with basic knowledge of machine learning and Python can learn RAG step by step.
Course Schedule
| Course Name | Batch Type | Details |
| Generative AI Training | Every Weekday | View Details |
| Generative AI Training | Every Weekend | View Details |