Do you ever think about what separates great candidates from others in data structure interviews? With my years of experience in conducting and taking part in several technical interviews, I have noticed very similar patterns that the best candidates use when approaching a problem. From this experience I have gained some useful tips on how to answer these types of questions successfully, so you will know not only the concept but also have an idea of how to present them when you get the actual interview.
This blog post compiles answers to Data Structure Interview Questions to help you prepare for your interviews, regardless of experience.
Following are some interview questions for freshers that are asked to check how strong a candidate’s basic knowledge is:
A data structure is a way of organizing and storing data in a computer so that it can be accessed and used efficiently. It refers to the logical or mathematical representation of data and the implementation in a computer program.
We create data structures to ensure that each line of code performs its function correctly and efficiently. They also help the programmer identify and fix problems with their code and they help to create a clear and organized code base.
There are numerous applications of data structures, but the most common ones are:
Basic operations performed on data structures include:
File structure focuses on how data is arranged in files for user level access and storage structure deals with how data is physically stored in memory or storage devices.
| Features | File Structure | Storage Structure |
| Definition | It organises your data in files for easy access and management by users or applications. | It refers to how your data is physically stored in memory or storage devices. |
| Level | Logical level (user view). | Physical level (system view). |
| Purpose | Helps in efficient data retrieval and file organization. | Ensures efficient memory utilization and data storage. |
| Example | Sequential file, indexed file and heap file. | Arrays, linked lists and trees in memory. |
| Focus Area | Focuses on file handling and access methods. | Focuses on memory allocation and data representation. |
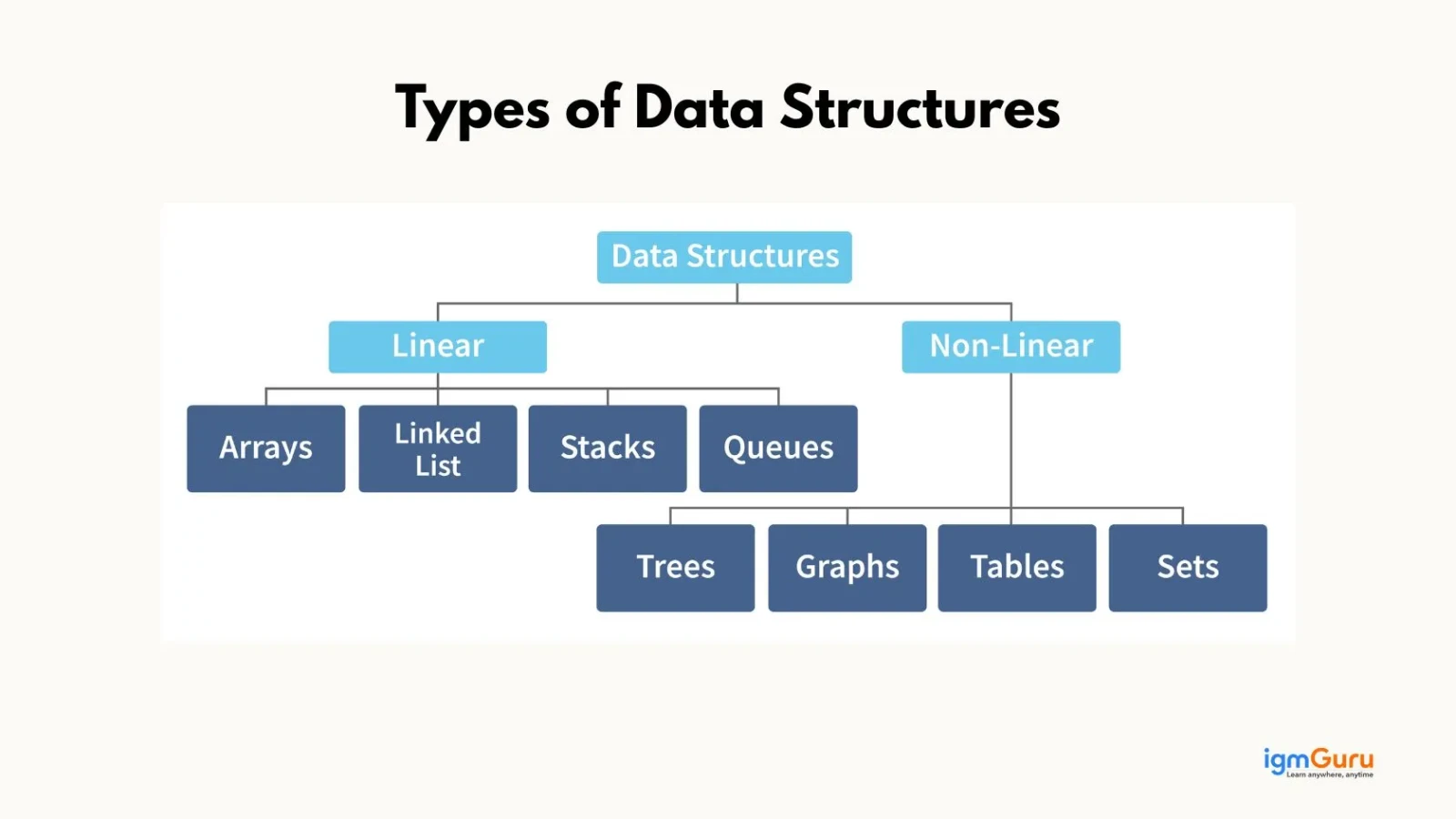
Data structures have following two types:
A stack is a linear data structure that works on the LIFO principle last in, first out. So the last element added is the first one removed. We mainly perform operations like push, pop and peek.
In terms of applications, stacks are used in recursion through the call stack, expression evaluation like infix to postfix, undo/redo features and backtracking problems. We can implement a stack using either arrays or linked lists
An array is a collection of elements stored in contiguous memory and you can access elements using an index. There are mainly three types:
A linked list is a linear data structure where elements are stored in nodes and each node points to the next one. Compared to arrays, they are not stored in contiguous memory.
There are different types:
Stack and queue are both linear data structures used to store and manage data, but they differ in how elements are added and removed.
| Features | Stack | Queue |
| Principle | Follows LIFO (Last In, First Out) | Follows FIFO (First In, First Out) |
| Insertion & Deletion | Both happen at the same end (top) | Insertion at rear, deletion from front |
| Main Operations | Push (insert), Pop (remove) | Enqueue (insert), Dequeue (remove) |
| Access Order | Most recently added element is accessed first | Oldest element is accessed first |
| Real-Life Example | Stack of plates | Queue at a ticket counter |
Read Also: DBMS Interview Questions and Answers
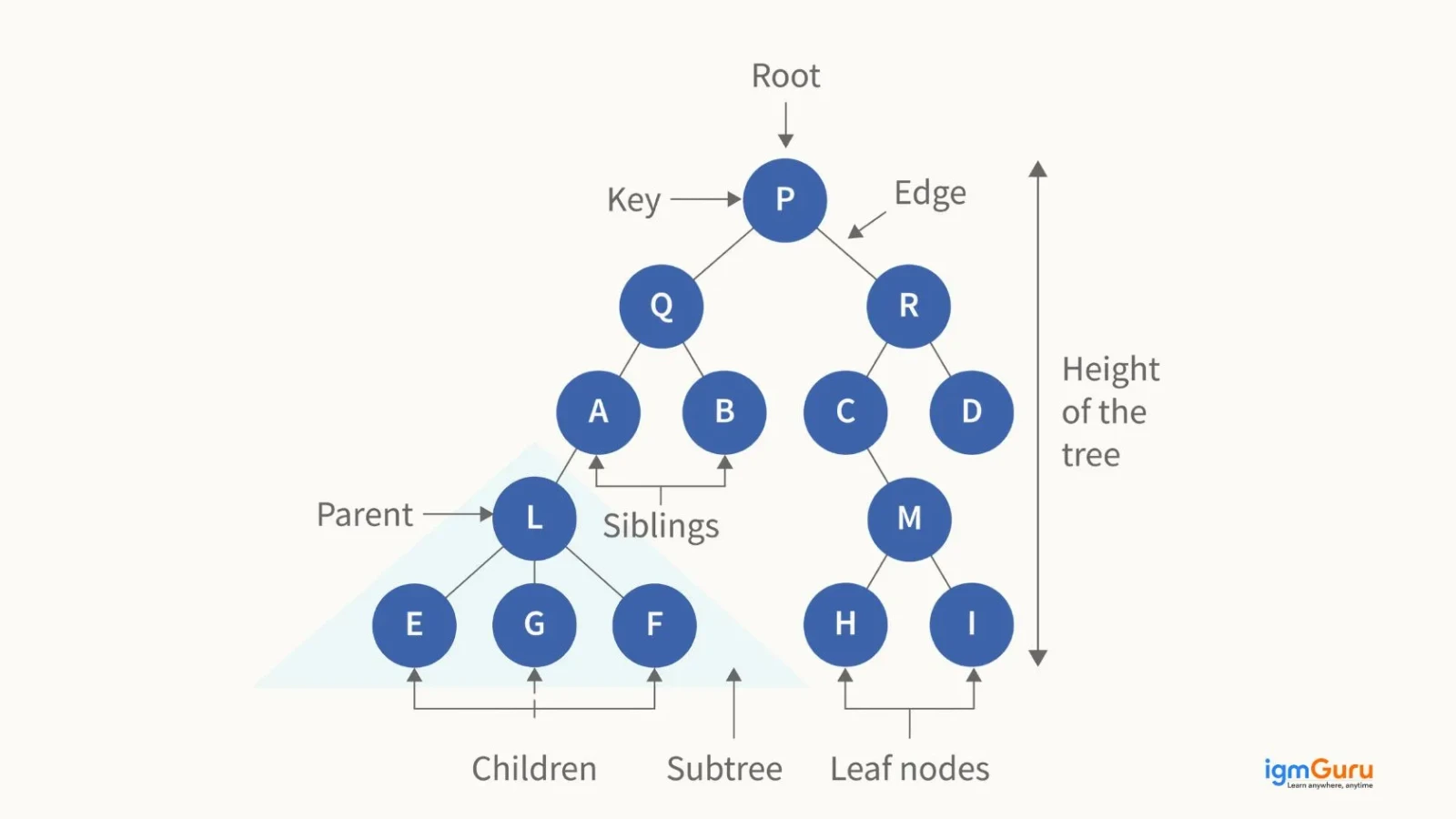
A binary tree is a hierarchical data structure in which each node can have at most two children, typically called the left child and the right child.
Following are some applications for binary tree data structure:
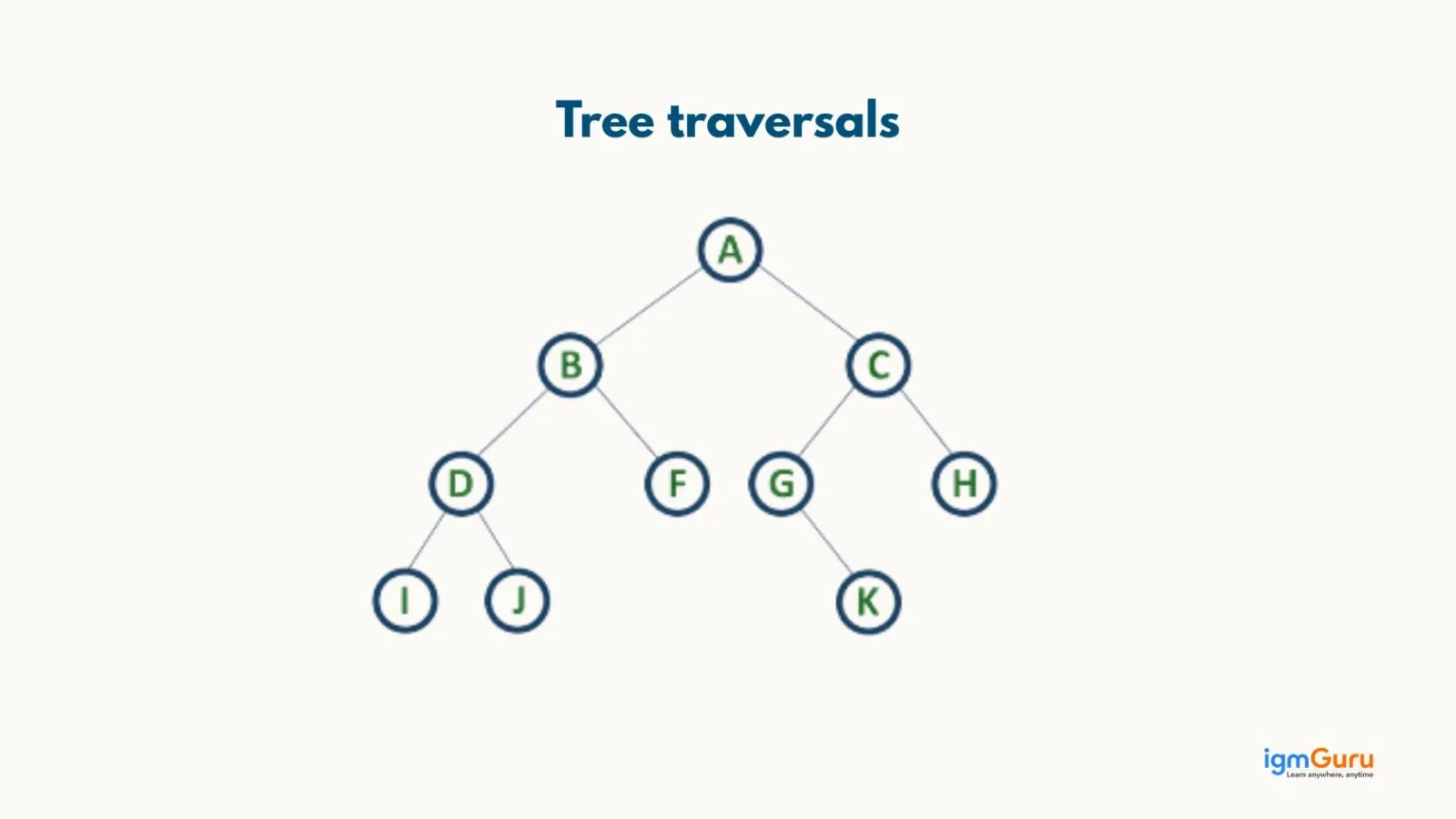
Tree traversals are the different ways of visiting or processing all the nodes in a tree data structure in a specific order.
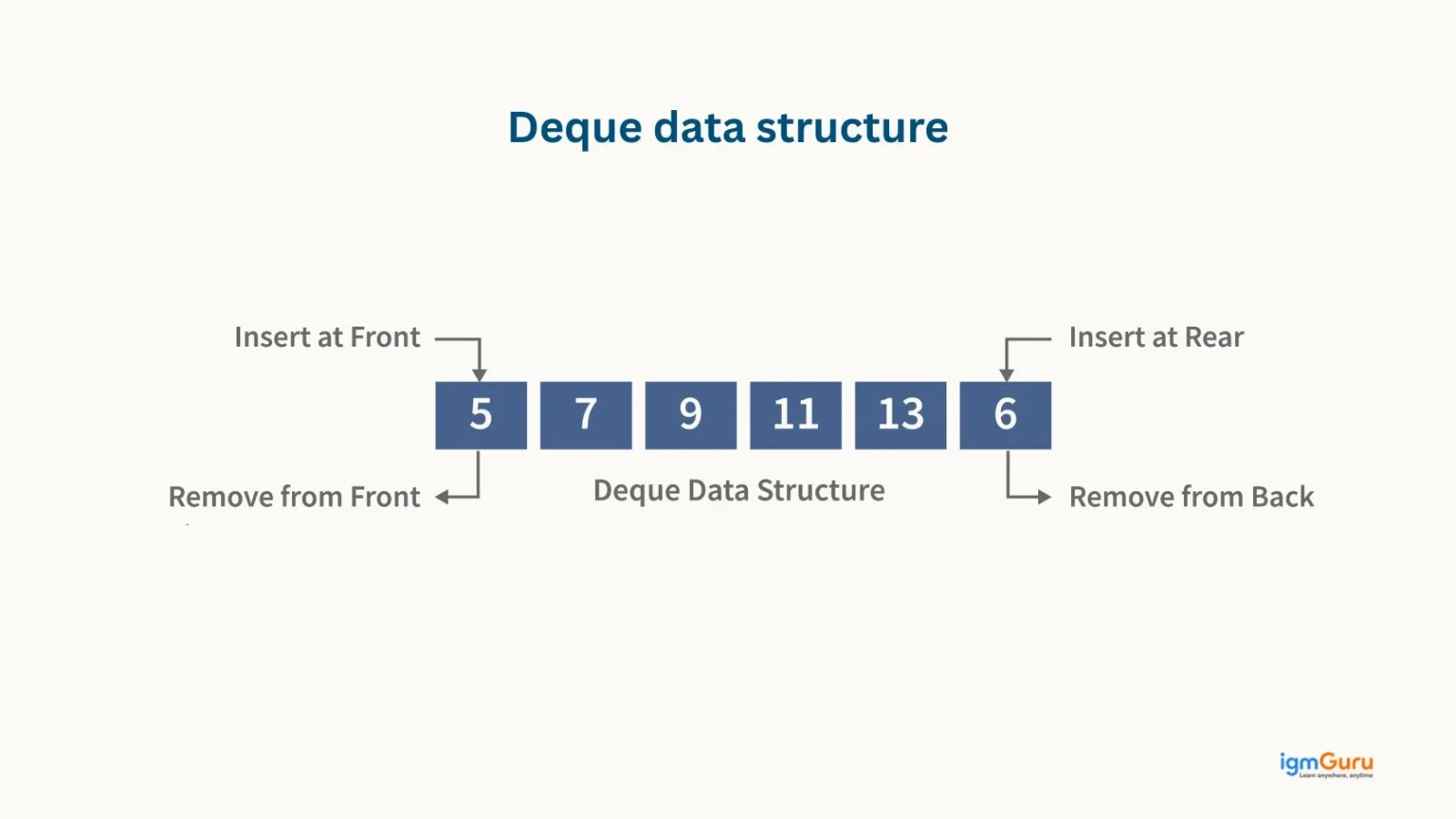
A deque stands for double ended queue. It is a data structure that allows you to add or remove elements from both ends, the front and the back. Deques are useful when you need flexible access at both ends, such as:
A Deque (Double-Ended Queue) allows insertion and deletion from both ends. Because of this flexibility, it supports several important operations:
A heap is a complete binary tree that satisfies the heap property. In a min-heap, the root is the smallest element, while in a max-heap, it is the largest. Operations like insertion and deletion take O(log n) time. Heaps are widely used in priority queues, heap sort, scheduling and graph algorithms like Dijkstra’s.
A hash table stores key-value pairs using a hash function to map keys to indices, enabling O(1) average access. Collisions occur when multiple keys map to the same index. They are handled using techniques like chaining (linked lists) or open addressing (linear probing, quadratic probing, double hashing). Used in caching, indexing and fast lookups.
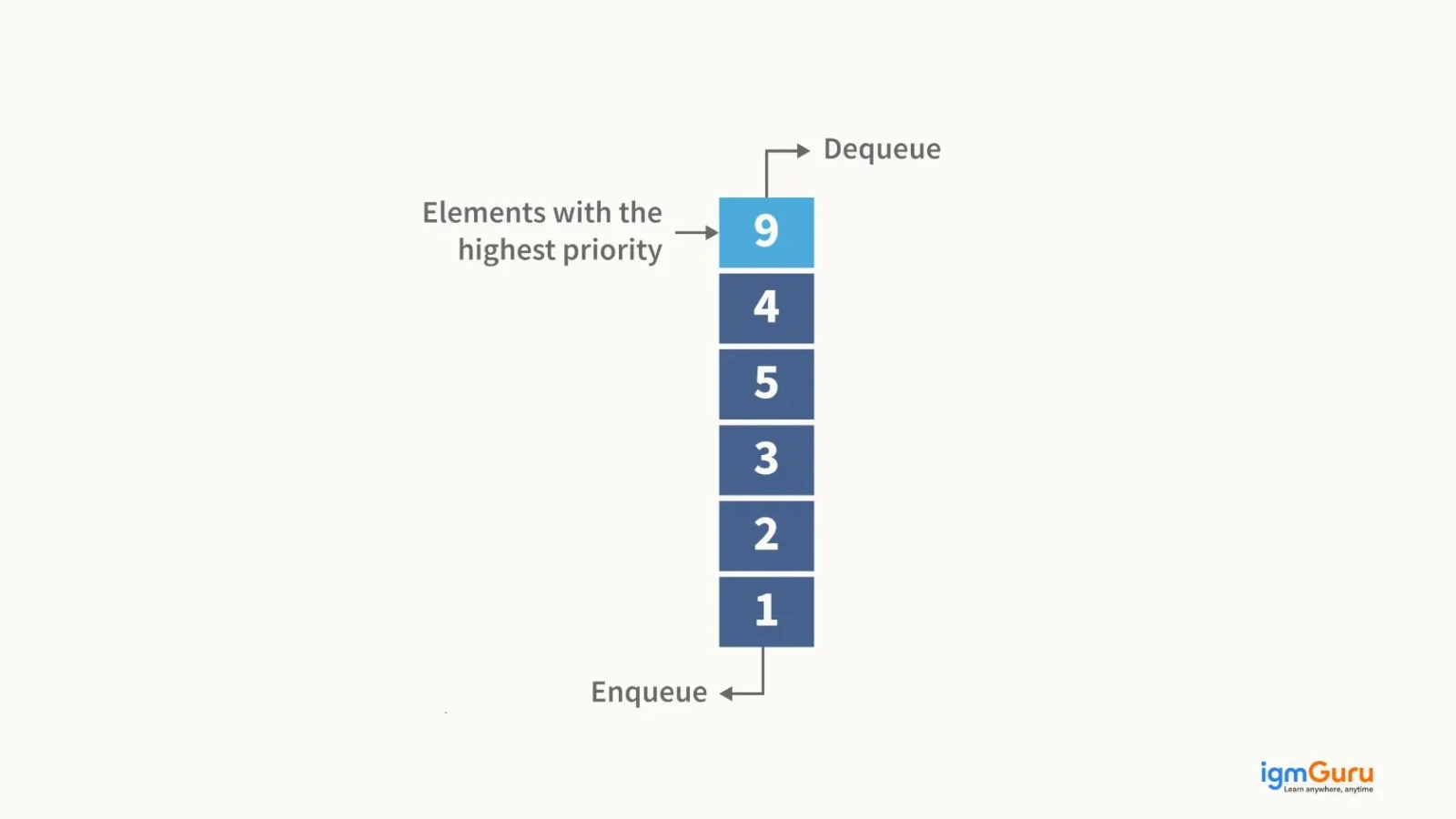
A priority queue is a data structure where elements are processed based on priority rather than insertion order. It is commonly implemented using a heap, ensuring O(log n) insertion and deletion. It is used in CPU scheduling, shortest path algorithms like Dijkstra’s, event-driven simulations and systems requiring efficient priority-based processing of tasks.
A graph consists of vertices and edges representing relationships. It can be directed or undirected, weighted or unweighted, cyclic or acyclic. Graphs are represented using adjacency matrices or lists. They are widely used in social networks, routing algorithms, navigation systems, recommendation engines and dependency resolution in software systems.
A trie is a tree-like data structure used to store strings, where each node represents a character. Words sharing common prefixes share the same path, making operations like search, insert and prefix lookup efficient, typically O(L) where L is the word length.
You can use it for:
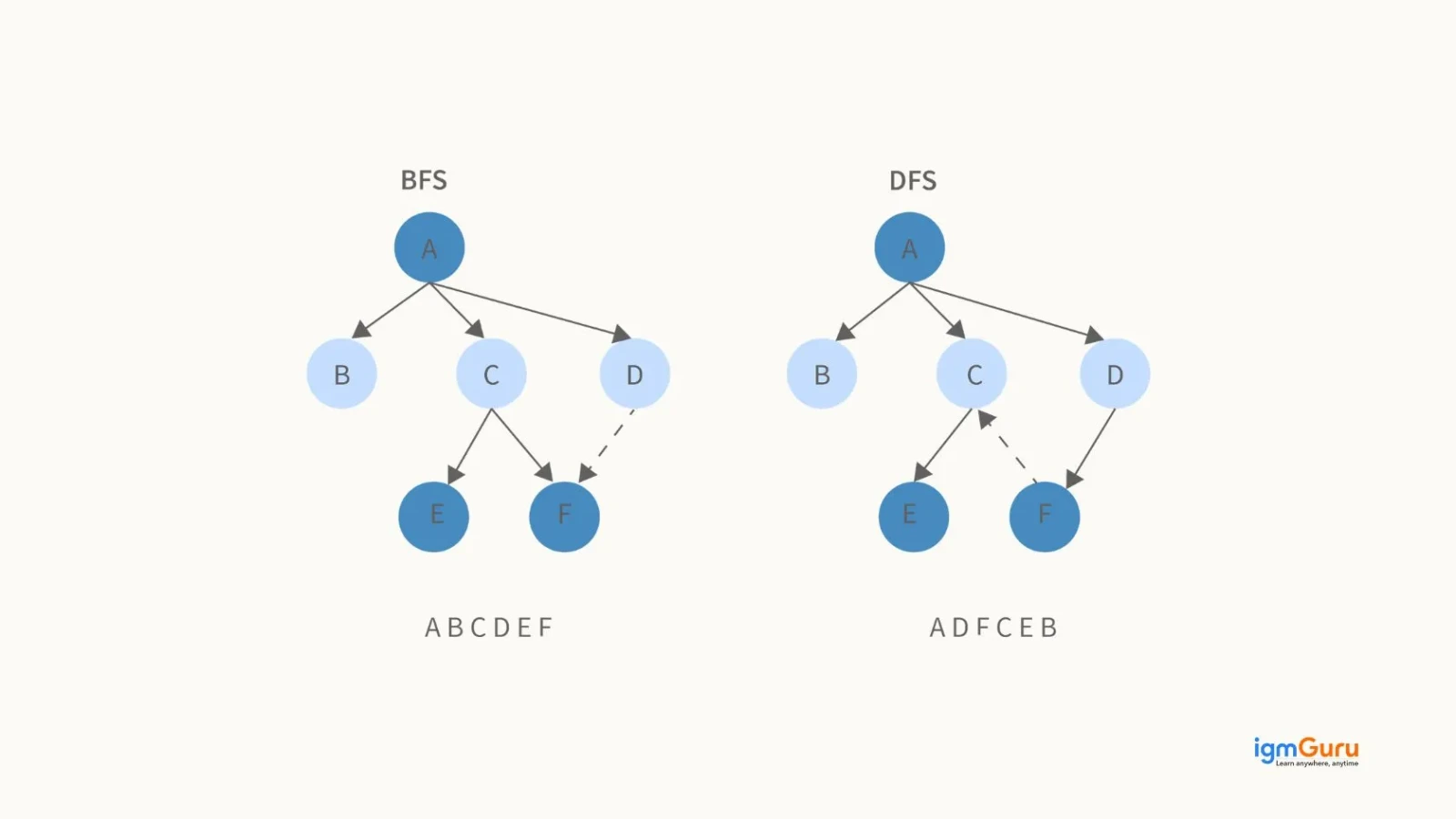
Breadth First Search and Depth First Search are graph traversal algorithms used to explore nodes and edges. The main difference lies in how they visit nodes, BFS explores level by level and DFS goes deep into a branch before backtracking.
| Features | BFS (Breadth First Search) | DFS (Depth First Search) |
| Traversal Method | Visits nodes level by level | Explores nodes depth-wise before backtracking |
| Data Structure Used | Queue | Stack (or recursion) |
| Path Finding | Finds shortest path in unweighted graphs | Does not guarantee shortest path |
| Memory Usage | Uses more memory (stores all levels) | Uses less memory (stores current path) |
| Use Case | Shortest path, level-order traversal | Cycle detection, topological sorting |
Read Also: Top Data Science Interview Questions and Answers
In a system that needs to handle millions of real-time updates, I would focus on both performance and scalability. I would start by using in-memory data structures such as concurrent hash maps to support fast read and write operations.
To efficiently handle high write throughput, I would incorporate log-based storage, specifically append-only logs, which allow sequential writes and reduce disk overhead. I would also use batching techniques to group multiple updates together, improving overall efficiency.
For scalability, I would partition or shard the data across multiple machines so that the workload is distributed. Additionally, I would consider using data structures like Log-Structured Merge Trees, which are specifically optimized for write-heavy workloads.
Optimizing for both time and space complexity requires understanding the system’s usage patterns. I would first analyze whether the system is read-heavy or write-heavy.
To optimize for time, I would use techniques such as hashing for constant-time lookups, indexing structures like trees for ordered data and caching for frequently accessed data.
To optimize for space, I would use compact data structures such as bit arrays or bloom filters and avoid storing redundant data. Compression techniques can also be applied where appropriate.
In a production environment, I would rely heavily on profiling and monitoring to understand real-world performance. Often, the best solution is a hybrid approach that efficiently balances time and space.
Self-balancing trees are binary search trees that automatically maintain their height to ensure that operations such as search, insertion and deletion remain efficient.
An AVL tree maintains strict balance by ensuring that the height difference between left and right subtrees is minimal. This results in faster lookups but requires more rotations during insertions and deletions.
A Red-Black tree, on the other hand, allows a slightly relaxed balance. This reduces the number of rotations and makes insertions and deletions faster, although lookups may be slightly slower compared to AVL trees.
In real-world applications, AVL trees are better suited for systems where reads are more frequent, while Red-Black trees are commonly used in systems like standard libraries where insertions and deletions happen more frequently.
A distributed hash table is a decentralized system that stores key-value pairs across multiple nodes. Each node and each key is assigned a hash value and data is distributed based on these hash values.
The system uses consistent hashing to ensure that when nodes are added or removed, only a small portion of the data needs to be redistributed.
When a lookup is performed, the system uses routing information to locate the node responsible for the key efficiently, typically in logarithmic time relative to the number of nodes.
Distributed hash tables are widely used in peer-to-peer systems, distributed storage systems and large-scale databases because they provide scalability, fault tolerance and efficient data distribution.
To design a Least Recently Used cache, I would use a combination of a hash map and a doubly linked list.
The hash map allows constant-time access to cache elements by storing keys and references to nodes in the linked list. The doubly linked list maintains the order of usage, where a recently used item is at the front and the least recently used item is at the end.
Whenever an item is accessed, I would move it to the front of the list. When the cache reaches its capacity, I would remove the item at the end of the list, since it is the least recently used.
This design ensures that both retrieval and update operations are performed in constant time.
Graph data structures are very useful for modeling relationships between entities.
In routing systems, such as navigation applications, locations are represented as nodes and roads as edges. Algorithms like Dijkstra’s algorithm or A-star search are used to find the shortest or fastest path between two points.
In recommendation systems, graphs are used to represent relationships between users and items. For example, edges can represent user interactions like clicks or purchases. Algorithms can then analyze these connections to recommend similar items or users.
Graphs are powerful because they allow us to model complex relationships and efficiently traverse them.
A bloom filter is a probabilistic data structure that is space efficient and can be used to determine whether or not an item exists in a set. In a bloom filter, multiple hashing functions are used to create set memberships for an item across various position locations in a bit array. When inserting an item, the corresponding bits in the bit array are set to 1. When checking for membership of an item, its membership is verified using the same hashing function that was originally used to create that membership.
If each of the bits corresponds to a 1, the item might exist. Otherwise, the item definitely does not exist. Thus, there is no way to have a false negative in a bloom filter, but there is a possibility of having false positives. Bloom filters are useful for applications that require high memory efficiency and a low tolerance of false positives, such as caching systems or databases.
Cycle detection varies by graph type. For directed graphs, I would use depth-first search along with a recursion stack. If I encounter a node that is already in the recursion stack, it indicates a cycle.
For undirected graphs, I would use the union-find data structure. If two nodes belong to the same set and are connected again, it indicates a cycle.
Another approach for directed graphs is Kahn’s algorithm, which uses topological sorting. If all nodes cannot be processed, it means a cycle exists.
Each method is efficient, with time complexity proportional to the number of vertices and edges, but the choice depends on the graph type and use case.
Collisions occur when multiple keys map to the same index in a hash table. One common method to handle this is chaining, where each index stores a list or another structure of elements. Another approach is open addressing, where collisions are resolved by probing for the next available slot using strategies like linear probing or quadratic probing.
In large-scale systems, I would also ensure the use of a strong hash function to evenly distribute keys, maintain a low load factor and resize the hash table when necessary.
Advanced techniques such as cuckoo hashing or tree-based buckets can further improve performance in high-load scenarios.
To design an efficient autocomplete system, I would primarily use a trie, also known as a prefix tree. This structure allows fast retrieval of all words that share a common prefix.
To optimize space, I could use a compressed trie, which reduces redundant nodes.
For ranking suggestions, I would maintain additional metadata such as frequency or relevance scores and use a priority queue to return the most relevant results.
In a production system, I would also integrate an inverted index for fast lookups, caching for frequently searched queries and possibly machine learning models to improve ranking quality. This combination ensures both fast retrieval and high-quality suggestions.
Read Also: Python Data Structures
In a recommendation or semantic search system, the first step is to convert items such as movies, products, or documents into vector embeddings using a machine learning model.
To efficiently retrieve similar items, I would use Approximate Nearest Neighbor (ANN) search instead of exact search because of the high dimensionality and scale. A strong choice here is HNSW, which provides fast query times with good accuracy. KD-Trees or Ball Trees can work for smaller or lower-dimensional datasets, but they don’t scale well.
For similarity comparison, cosine similarity or dot product is commonly used. In production, I would rely on optimized libraries like FAISS or vector databases like Milvus. The key idea is to slightly trade accuracy for significant performance gains
This system can be modeled as a graph where users or accounts are nodes and transactions are edges. Each edge can store attributes like transaction amount, timestamp, or location.
An adjacency list is suitable for efficient storage, or a graph database like Neo4j can be used for scalability and querying. To detect fraud patterns, several graph algorithms are useful:
To maintain a real-time dashboard for the last 5 minutes, a sliding window approach is required. A deque can be used to store events with timestamps. New events are added to the rear and outdated events are removed from the front when they fall outside the time window.
For better scalability, time based bucketing with a circular buffer can be used, where each bucket represents a small time interval like one second. This allows efficient aggregation. Maintaining rolling aggregates such as count or sum avoids recomputation and ensures constant-time updates.
In a high-concurrency environment, lock-free data structures can be used to avoid bottlenecks caused by locks. The core mechanism is Compare-And-Swap (CAS), which allows atomic updates only if the value has not changed. This enables the implementation of lock-free stacks or queues.
There are challenges to consider:
To count unique users at a very large scale with limited memory, HyperLogLog is an efficient choice. Instead of storing all user IDs like a HashSet, it uses probabilistic techniques to estimate the number of unique elements based on hashed values.
It requires only a small amount of memory while maintaining a low error rate, typically around 1–2%. This makes it highly suitable for large-scale systems where exact precision is less important than efficiency.
This blog contains 20+ fully detailed responder questions about the Data Structures Interview Guide. These data structure interview questions will help prepare you for your next interview. Keep practicing and learning new things about trending technology to improve your overall understanding of current technological advances.
Focus on knowing basics like: arrays, trees, graphs, etc. Then work on coding problems regularly, and practice explaining the solutions to these problems in an interview setting.
Arrays, linked lists, stacks, queues, trees, graphs, heaps/hashes are the most frequently asked about and necessary types of data structures for interviews.
Yes, they evaluate your real-life ability to solve problems and your ability and knowledge to be able to apply theory to real-world scenarios.