Scikit-learn is one of the most popular and open-source Python libraries for machine learning (ML). It is a well-stocked toolbox for data scientists to pick the best tools for data analysis and modeling. It's not only the data scientists who must question 'what is scikit-learn', anyone who wants to leverage Machine Learning to solve real-world problems must question the same. I have created this detailed blog to give you a solid foundation to start your ML journey. Let's see how to harness the power of Scikit-learn in your projects.
Are you looking for simple tools to perform data analysis and modeling? Scikit-learn is an open-source Python library to get those tools. All you have to do is pick the right tool from the toolbox for machine learning. It integrates nicely with other scientific Python tools like NumPy, Matplotlib, and SciPy. This makes it a powerful tool and allows you to treat data like numbers, matrices and arrays.
You must note that this library relies on NymPy for quick linear algebra and array manipulation tasks. It is written in Python to a great extent and some important algorithms are written in Cython for better functioning. It has the necessary modules for regression, classification, and clustering.

Let's take a quick look at the history of Scikit-learn through its past, present and future-
Scikit-learn is the creation of David Cournapeau, a proficient data scientist. It was initially named scikits.learn.and was created as GSoC (Google Summer of Code) project in 2007. Several volunteers contributed to its success and took this project to an advanced level-
scikit-learn grew popular in the Python science community after the public release. It became a community-driven project with new algorithms and features getting added to it from time to time. Today, it is still actively maintained by developers worldwide and supported by a number of organizations. This includes some big names like INRIA, Microsoft, Intel, and NVIDIA. It has turned into a full library for tasks like classification, regression, clustering, reducing data size, choosing models and preparing data.
As Scikit-learn grows, new work is being done to add more powerful ensemble methods and meta-learning strategies. By combining neural networks with classic algorithms, Scikit-learn aims to be a versatile toolbox for all kinds of machine learning tasks. These improvements should make it even easier for people to use the latest techniques in their projects.
As a popular Python library, it makes machine learning practical and accessible. Here's what it does-
Before building models, real data often needs cleaning. Scikit-learn provides tools to handle missing values, scale or normalize numerical features, and convert categorical variables into numerical formats (like one-hot encoding). It also offers "feature extraction" methods, for example converting text or dictionaries into numeric features usable by machine learning algorithms.
Once data is prepared, Scikit-learn includes a wide variety of supervised learning algorithms (for tasks where you have labeled data), such as logistic regression, support vector machines (SVMs), decision trees, random forests, and gradient boosting. It also supports unsupervised learning like clustering (K-means, DBSCAN) and dimensionality reduction (e.g. PCA) to simplify data or find underlying structure.
Scikit-learn helps you not only build models but also assess how well they're doing. It lets you split data into training and testing sets, use cross-validation to avoid overfitting, compute performance metrics (accuracy, precision, recall, mean squared error, etc.), and compare different models. Hyperparameter tuning tools (grid search or randomized search) allow you to optimize model parameters.
Scikit-learn provides Pipeline utilities that let you chain preprocessing steps, feature transformers, and the final estimator (model) into one object. That way, you ensure that data transformations are applied consistently in training and testing, and your code is cleaner.
Many core algorithms are implemented in efficiently compiled code (via Cython), especially for computation-heavy operations. It integrates smoothly with the broader Python ecosystem: NumPy for arrays, Pandas for data frames, Matplotlib for plotting, etc.
Read Also: Machine Learning Tutorial- A Complete Guide For Beginners
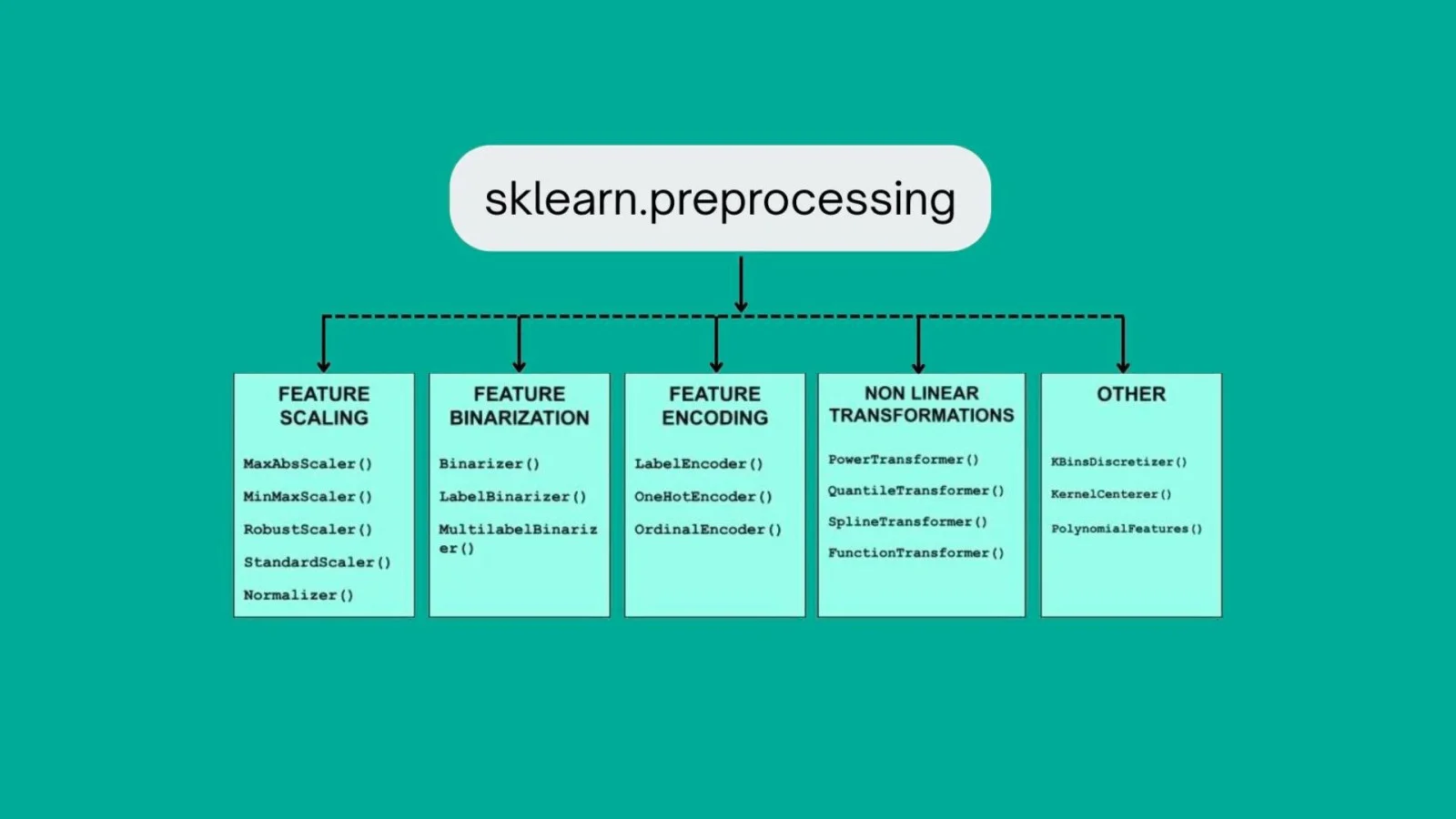
Preprocessing is an important step in getting ready raw data for ML models. Raw data comes with many errors, including missing values, categorical variables, etc. These errors must be handled as they can cause issues in ML algorithms performance. Scikit-learn's sklearn.preprocessing modules give you a number of tools to treat these issues. Here are some more examples of such modules offered by Scikit-learn-
Let's take a look at Scikit-learn's features to understand what this library has to offer in the world of data-
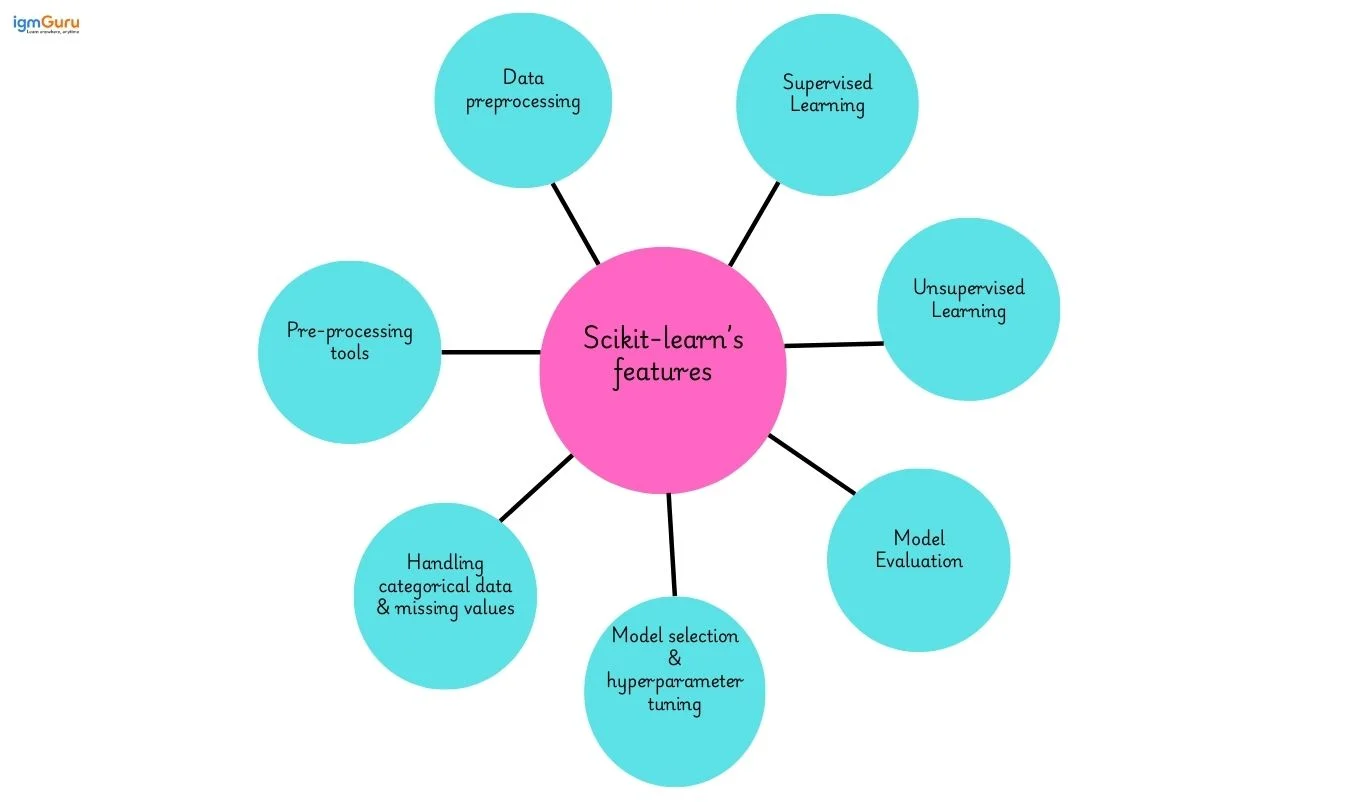
This feature ensures your data is clean, consistent, and ready for modeling.
Here, the model learns from labeled data to make predictions.
Here, the model works with unlabeled data to find patterns and structure.
This step checks how well your model performs and helps you fine-tune it.
It helps pick the best models and settings via cross-validation, grid search, random search and various performance metrics.
Newer versions add better support for categorical features (for example in HistGradientBoosting), the ability to treat missing values explicitly, etc.
Tools for preparing data before modelling: scaling/normalizing, encoding categorical variables, imputing missing values, and feature extraction (e.g. from text or images).
You simply create a Scikit-learn pipeline that applies a sequence of transformers to prepare and extract features from the data. It then builds the model using an estimator and tests the model's predictions to check its accuracy. Still confused? Let's understand Scikit-learn's architecture through the following concepts-
- Pipelines: chain multiple steps (transformers + final estimator) so that you can preprocess + train in one object. Helps avoid mistakes (e.g. data leakage) and makes workflow simpler.
- ColumnTransformer / FeatureUnion: Apply different transformations to different features / combine features.
- Hyperparameter search (GridSearchCV, RandomizedSearchCV): wrap around an estimator to try many parameter settings using cross-validation.
Let's learn about the most important components of Scikit-learn-
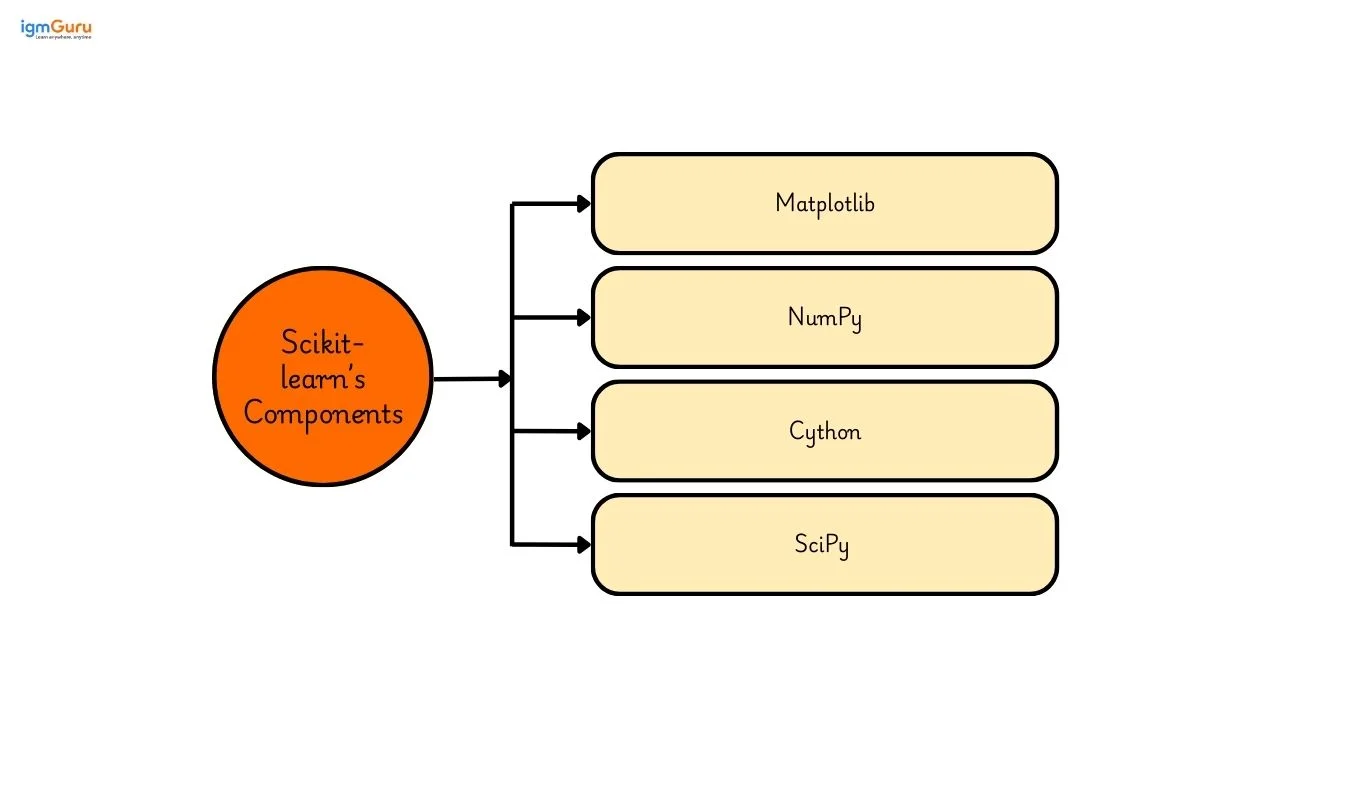
Matplotlib is a Python library for creating a number of visualizations from animated to interactive. Users can make plots ranging from simple histogram graphs to complicated 3D plots. Its flexibility lets you customize anything you want like styles and fonts. Multiple outputs are supported by this library which allows you to save visualizations like PNG, PDF, etc.
NumPy is a Python library for scientific computing and serves as a pillar for handling data arrays or smooth integration with ML algorithms. You also get a number of mathematical functions like random number generation, linear algebra operations, etc. You must also be familiar with ndarray, a strong N-dimensional array object for storage and manipulating large datasets.
Cython blends C's speed and Python's simplicity for you to write easily compileable code into highly efficient C code. This programming language improves performance for numerical computations or tasks involving loops.
SciPy is an impressive Python library that gives you a number of mathematical algorithms to simplify complicated computations. These computations could be from fields of engineering, statistics, data analysis, physics and more. You can access SciPy through the GitHub repository and it is completely free to use under the BSD license.
Read Also: Top 55 Machine Learning Interview Questions
In this section, I will tell you how to install the Scikit-learn library in Python-
Install Scikit-learn using Python's package manager called pip with the given command-
| !pip install scikit-learn |
Use the import statement to import Scikit-learn modules into your Python environment or script-
| import sklearn |
Let's discuss the use cases of Scikit-learn-
The machine learning community welcomed major upgrades with the Scikit-Learn release in November 2025. It introduces faster training performance, better model interpretability, and closer integration with deep learning ecosystems. This release focuses heavily on speed, scalability, and automation, making it easier for developers to run experiments, tune models, and deploy large-scale pipelines.
The improvements expand Scikit-Learn beyond traditional ML workflows, giving data scientists more flexibility through GPU support, distributed training, and better visualization tools.
| Feature | What’s Improved or Added |
| GPU-Accelerated Algorithms | Core models like SVM, Logistic Regression, and KNN now support GPU computation. |
| Deep Learning Integration | TensorFlow and PyTorch models can be wrapped directly into Scikit-Learn pipelines and evaluated with familiar APIs. |
| AutoML Hyperparameter Tuning | Automated search and tuning reduce manual trial-and-error for faster prototype optimization. |
| Faster RandomForest | Speed improvement up to ~35% on large datasets with better sparse-data handling. |
| New Feature Engineering Tools | Smart encoders, improved scalers, and automatic missing-value treatment built-in. |
| Visualization Enhancements | Plotting utilities for feature importance, confusion matrix, ROC-AUC, clustering, and model comparison. |
| Distributed Training Support | Train models across clusters or cloud environments natively, improving scalability for enterprise workloads. |
In conclusion, what is Scikit-learn? You know it all now by the end of this blog. Let me still conclude that it is your trustworthy toolkit to get meaningful information by transforming raw data. It handles heavy lifting like model evaluation and preprocessing so you can ask the right questions. You are ready to turn data into decisions and ideas into impact.
You must keep in mind that Scikit-learn does not provide full GPU support for all its algorithms. Yet a growing number of estimators can work with GPU/accelerator-backed libraries via the experimental Array API.
The first step is to prepare data, pick an estimator, call fit() on your training data so it can learn patterns. The next step is to use predict() on new data. This consistent API makes it easy to dry different models without changing the complete setup.
It is used to build machine learning models like classification, regression and clustering.
Libraries like NumPy, Pandas and Matplotlib are often used with it.