Machine learning algorithms are actively changing the way of creating models with automation capabilities. These models are used in many industries including finance, marketing, retail and many more. Many individuals misunderstand that data is the sole driver of this process, but it is not, as we have hyperparameter tuning in machine learning. Do you know how ML algorithms are trained to create these models?
In this article, we will explore everything around the hyperparameters from their basic understanding to different methods and best practices. Hyperparameter tuning focuses on optimizing the internal settings that control the learning process. It follows a completely different approach in model training than the traditional way.
Let's start with understanding what hyperparameters in machine learning are. The ML algorithms typically have their settings or configurations known as hyperparameters. These settings do not learn from the data but are set by the users before model training starts. Hyperparameters have a crucial role in optimizing the performance and nature of models.
Hyperparameter tuning in machine learning is the way to detect all the values of the hyperparameters that can combine and optimize model performance. It improves the accuracy, convergence speed and generalization capabilities of the model. It is not a direct approach and involves many factors to consider. These factors are the dataset, the architecture of the model and the problem we are addressing.
You may also want to know why tuning is essential. We have only mentioned the main objective in the above section, but there is more. This method not only improves the performance of the model but also helps to achieve more efficient and dependable findings. It also controls the learning rate of models, the number of neurons in a neural network and the kernel size in vector machines.
Explore igmGuru's Machine Learning Training program to start your career in Machine Learning.
Model parameters and hyperparameters are the most confusing elements in machine learning. It is important to have a clear view of these two elements to create efficient models. So, let's discuss some of the main differences between them. The table given gives a clear view of these two elements -
| Model Parameters | Hyperparameters |
| It makes predictions. | It estimates the model parameters. |
| Optimization algorithms like Gradient descent, Adam or Adagard find these parameters. | Hyperparameter tuning detects these parameters. |
| One can not set them manually. | One can set them manually. |
| These are created after the model training starts. | These are created before model training starts. |
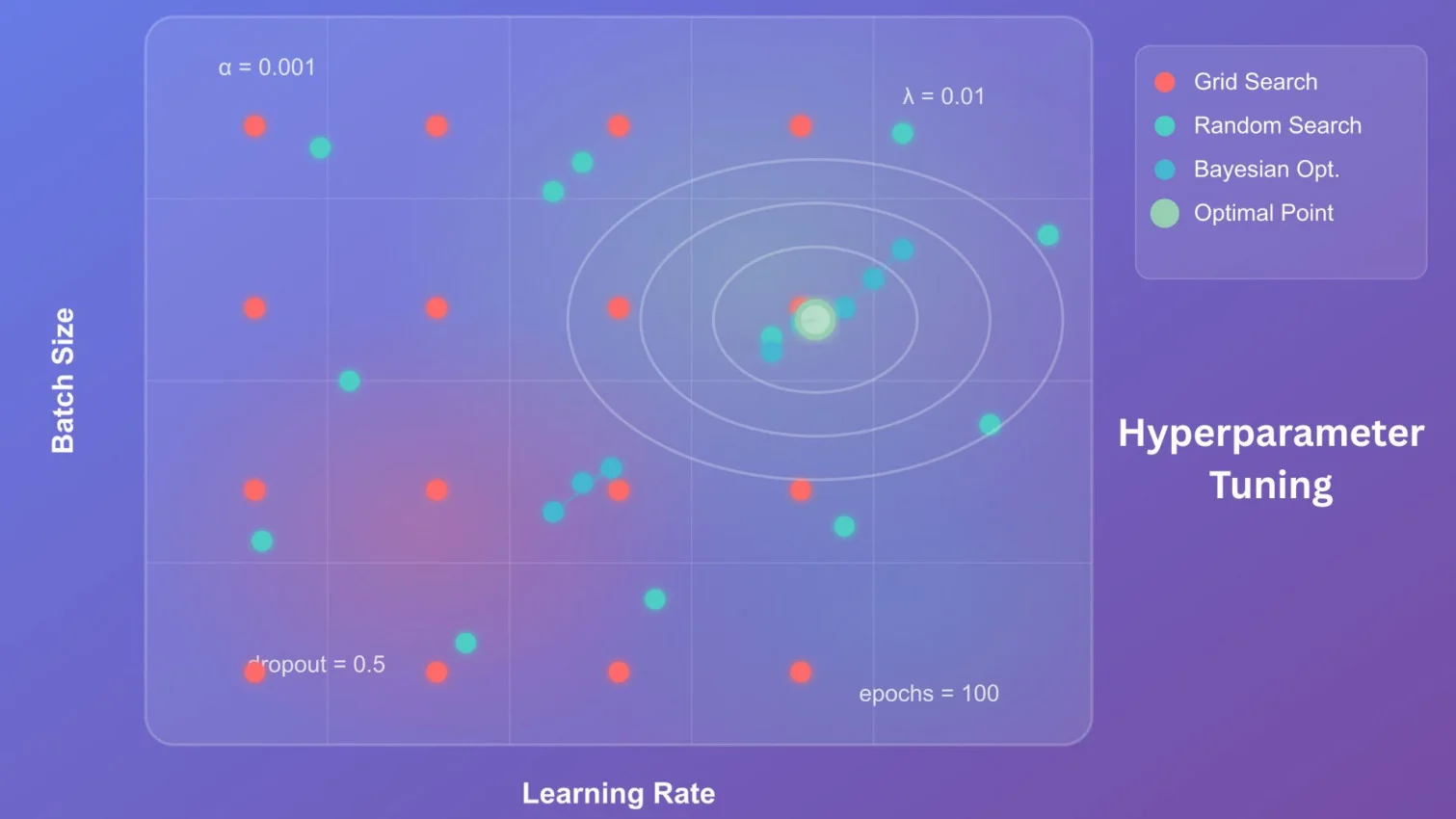
There are many types of hyperparameter tuning in machine learning. These are grid search, random search, Bayesian optimization, manual search, hyperband and genetic algorithms. We are discussing the top 3 types, which are the most used and preferred by experts.
The grid search method trains the model in every possible combination of predefined hyperparameters. This process starts by defining many different sets of feasible values for every hyperparameter. Then, ML algorithms automatically create all the possible combinations of these values. Think of hyperparameters consisting of the learning rate and the number of hidden layers in a neural network.
In this case, the algorithms will attempt all the feasible combinations such as one hidden layer with a 0.1 learning rate, two hidden layers with a 0.2 learning rate and so on. This way, the system can train and evaluate the model with each possible combination. Now, individuals can choose the one that is the best for model optimization.
There are a few limitations of this method. It is computationally intensive due to its approach of using individual models for every combination. It is limited to predefined values and can not use optimal values. However, the simplicity and effectiveness of this method surpass all these cons. This is why many experts in data analysis and machine learning prefer to use it.
Deciding where to use a tuning method is also an important factor. The grid search method is mostly useful in smaller and less complicated model training. Its use can be expensive if the space of parameters is humongous due to its computationally intensive nature.
The random search method selects a combination of hyperparameters from a predefined suite to train the model. This method defines many different possible values for each hyperparameter. Then, the ML algorithms randomly select any of them and use them in model training. Let's take the same instance to understand the workings of this method.
In this case, the random search algorithm will randomly choose a combination of values. These values and a specific metric will train the model and evaluate its performance. The algorithm will repeat this process for a predefined number of times. At last, the combination that gives the best performance result will be your optimal set.
This method is less systematic due to its random nature. It can not be effective in detecting the best optimal set. It also lacks the insights of hyperparameters as it does not explore all the possible combinations. Despite these limitations, this method is preferred by many experts due to its simplicity in implementation.
This method is mostly useful when dealing with humongous and high-dimensional hyperparameters as it is impractical to test each combination in this case. It is a good solution for models like deep neural networks with many hyperparameters. It can be very beneficial for experts who do not have a strong understanding of parameter values.
We have seen some insufficiencies in the above two methods due to the use of unwanted hyperparameters. The Bayesian optimization method does not have this issue. It follows a completely different approach in which results are used to find the next combination. It uses existing results of model evaluation and a probabilistic function to find the best combination for model training.
The probabilistic model predicts the result of the objective function by evaluating recent results. This way one can discover the best parameter with a few iterations. This probabilistic model is very useful when the objective of a function is unknown.
This method is way more complicated than grid search or random search. It requires many computational resources to run. On the other hand, it is also more effective at detecting the feasible combination of hyperparameters, especially for complicated models. It can also handle situations where the objective function is expensive or complicated to evaluate.
Bayesian optimization is mostly useful in optimizing the black-box function. It reduces the need to evaluate each hyperparameter combination. This decreases the resource expenses. Most experts prefer to use it when model training is significantly expensive and time-consuming.
Related Article- Machine Learning Tutorial- A Complete Guide For Beginners
Learning about the methods of hyperparameter tuning in machine learning is not enough to train ML models efficiently. The inaccurate use of these methods can raise many issues like poor performance, resource wastage and unreliable results. Here are some of the best practices one should know before training any ML model:
Always choose a sensible range for hyperparameters. It prevents all the unnecessary trial and error that might occur due to their extensive use. One can search for values that are most suitable for the model type and use domain knowledge or previous experiments to set meaningful boundaries. Avoiding this practice means you are just wasting your time on irrelevant tests.
Cross-validation ensures that the performance of your model does not depend on a specific dataset split. This practice involves training and testing multiple subsets of data, which can achieve a more accurate measure of model generalization. Avoiding this practice may cause overfitting or misinterpreting performance results.
Monitoring training and validating metrics (e.g. accuracy and loss) helps to detect overfitting and underfitting issues. Overfitting means the model performs well during training data, but not on data validation. On the other hand, if both scores are low, it is underfitting. Ignoring these metrics can result in deploying an unreliable or inefficient model.
Hyperparameter tuning methods like grid search are resource-intensive, which can be expensive in some cases. This is why it is important to use only relevant combinations instead of all of them. Methods like random search, Bayesian optimization or Hyperband can find optimal parameters faster. These are the best options in these instances.
Documentation of the tuning process is also essential. There are chances when you will have to work on the same type of task which is already been done. In this case, these documents can suggest the optimized hyperparameters. This means you do not have to waste your valuable time and money on irrelevant testing.
Hyperparameter tuning in machine learning makes the best use of available data to train ML models. It can detect the most suitable optimized combination. Mastering it alongside other essential skills like data preparation and algorithm selection is the key to building more efficient ML models. Additionally, effective use of different tuning methods enhances the accuracy, speed, and generalization of these models.
The following are the common hyperparameters in machine learning:
Bayesian optimization is preferred as one of the best tuning methods by many experts. It has the capability to find the most suitable combination of hyperparameters with a few iterations.
The total duration of this process depends on the complexity of the model, the dataset size and the tuning method. Grid search can take hours or days due to its hit-and-try approach, whereas Bayesian optimization is way faster.
Course Schedule
| Course Name | Batch Type | Details |
| AI and ML Certification Courses | Every Weekday | View Details |
| AI and ML Certification Courses | Every Weekend | View Details |