Pandas is one of the most popular Python frameworks that can be a compass or survival kit for professionals like Python developers, data scientists, data analysts, machine learning engineers and other data-centric roles. It is a go-to tool for data-related tasks like cleansing, transforming, analysis and more. Therefore, professionals with this skill are in high demand across industries.
Are you preparing for a Pandas role? Well, I have created a guide of the most asked Pandas interview questions and answers to help you prepare for your next interview rounds.
Enroll in igmGuru's Pandas training program to accelerate your career growth.
Let's begin.
Let's begin with the most basic Pandas interview questions for beginners. These are designed for the fresher.
Pandas is an open-source Python library used to perform data manipulation and analysis. It provides different structures like Series (1D) and DataFrame (2D) that make it easy to work with structured data. Its applications are data cleansing, transforming, aggregations and more. It can also integrate with files like CSV, Excel or SQL databases.
A DataFrame is a two-dimensional, tabular data structure with labeled rows and columns. Think of it as an Excel spreadsheet or SQL table. Each column can hold a different data type like numeric, string, datetime, etc. This makes it flexible for real-world data. DataFrames are central to Pandas because they allow easy filtering, aggregation and manipulation of data.
A Series is a one-dimensional labeled array that can store any data type, including integers, strings, floats or objects. Think of it as a single column of data from a spreadsheet. Each value in a Series is associated with an index, which makes accessing and slicing data very efficient.
There are many ways to create a DataFrame -
The simplest way is to use-
import pandas as pd |
I would use the following code to view the number of missing values in each column -
df.isnull().sum() |
I would select a single column by using the column name inside square brackets-
df["column_name"] |
Lists and dictionaries can store data, but they don't have built-in tools for filtering, grouping, aggregating or cleaning. Pandas combines speed with convenience, making data manipulation much simpler.
NumPy mainly deals with numerical arrays and mathematical operations. Pandas builds on NumPy to handle structured/tabular data with labels. This makes it easier to work with real-world datasets.
Some of my favourite traits of Pandas include -
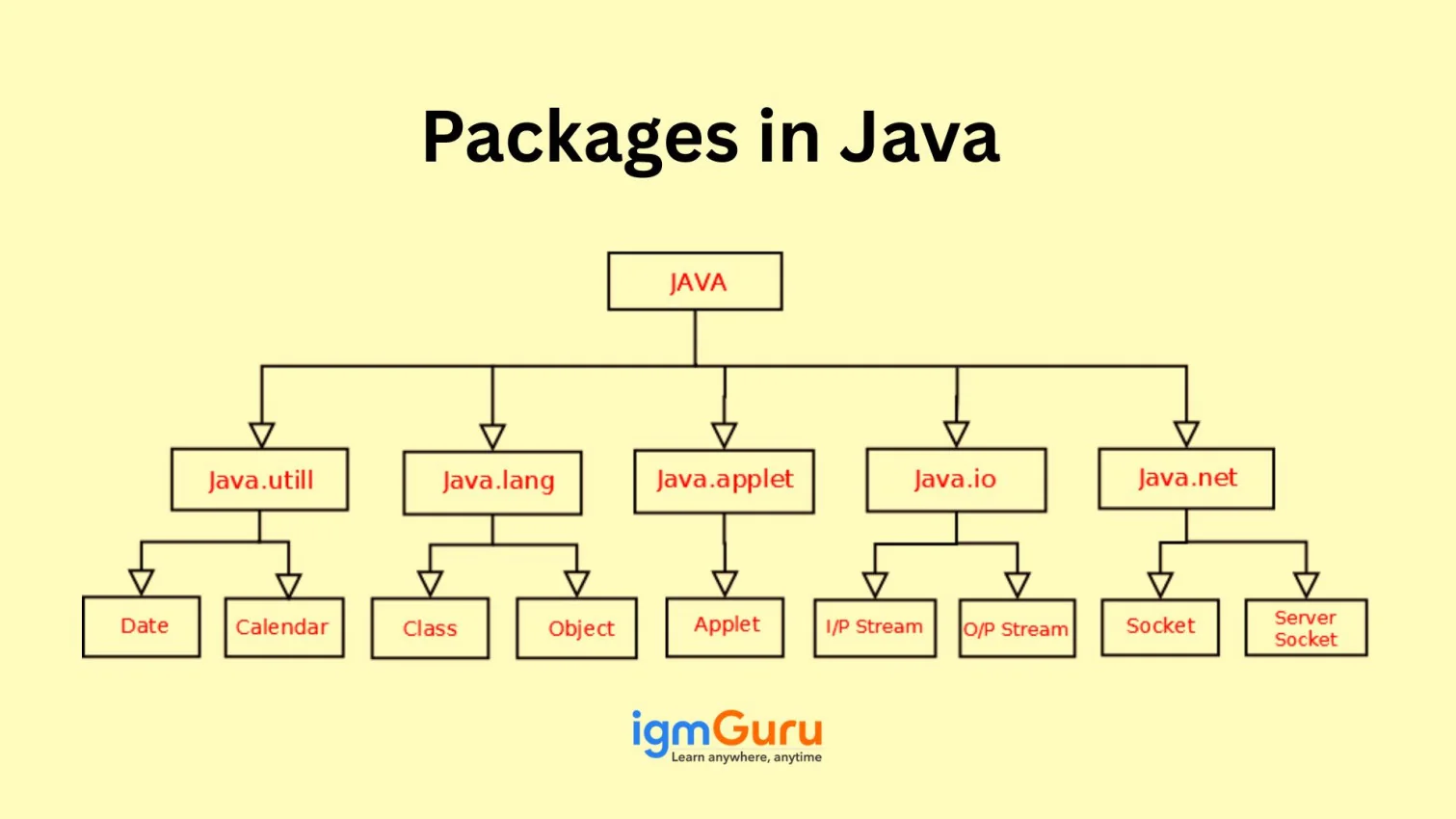
Related Article- NumPy Interview Questions and Answers
Now we will discuss the most asked Pandas interview questions for intermediates. These are designed for the professional with three to four years of experience.
I would use-
| COMMAND | WHAT IT DOES |
| df.dropana() | Remove rows/columns with missing values. |
| df.fillna (value) | Replace with a constant |
| df.fillna (df.mean()) | Replace with calculated values |
loc [] | It uses row/column names (label-based indexing) |
iloc [] | It uses integer positions (position-based indexing) |
pivot() works when the index/columns combination is unique. pivot_table() allows combination of numerical values (sum, mean, etc.) and handles duplicates.
I would get rid of duplicate rows by using the drop_duplicates() method. For example-
import pandas as pd |
I would check for correlation between numerical variables by using the .corr() method. Here is an example-
import pandas as pd |
Pandas is preferred over Excel for the following reasons -
Here are a number of limitations of Pandas -
Vectorization helps to perform operations on whole arrays all at once instead of going through them one by one. This speeds up Pandas and makes it work better.
NumPy is best for numerical arrays and matrices. Pandas is built on NumPy but adds labels, indexes and tabular structures. Pandas is more suited for real-world datasets with mixed datatypes.
Indexes provide fast lookups and alignment during operations. They help in filtering, joining and grouping data. These can be customized (numeric, string, multi-index).
Related Article- Top Python Interview Questions And Answers (2026)
Time for some Pandas interview questions for advanced to boost our knowledge. These are designed for the professional with significant years of experience in the industry.
Here are the difference between each four-
| Method | Access Type | Accepts | Returns | Use case |
| .loc[] | Label based | Labels, slices | Series/dataframe | General label-based access |
| .iloc[] | Integer based | Integers, slices | Series/dataframe | Position-based access |
| .at[] | Label based | Single label pair | Scalar | Fast access to a single value by label |
| .iat[] | Integer based | Single integer pair | Scalar | Fast access to a single value by position |
I would take the following measures to improve the performance of large DataFrame operations -
Difference between merge(), join(), and concat().
This is how I would replace the outliers -
Q1 = df['score'].quantile(0.25) |
I would find that out by performing the following example -
df['login_time'] = pd.to_datetime(df['login_time']) |
df['value'] = df.groupby('sensor_id')['value'].ffill() |
df.groupby('category').apply(lambda g: g.loc[g['discount'].mean().idxmax()]) |
This is how i would do it -
df['week'] = df['date'].dt.to_period('W') |
Here is how I would calculate and rest the cumulative sum of sales -
df['month'] = df['date'].dt.to_period('M') |
This is how I would filter it-
df[df.groupby('customer_id')['order_id'].transform('count') >= 5] |
Learning Pandas is about developing the skill to manage messy datasets and turn them into information. This blog, pandas interview questions and answers, is your practice ground to play with this magic library and master it with ease. You must not only know Pandas but also know how to think with it.
Related Guide:
Start with the basics like DataFrames, Series, indexing, filtering and simple aggregations. It's also good to practice by working with real datasets like CSVs from Kaggle.
Do quick coding drills, review common mistakes and brush up on real-world scenarios.
Jobs like Data Analyst, Data Scientist, Python Developer and Business Analyst often require Pandas skills.
The two main data structures are:
Couse Schedule
| Course Name | Batch Type | Details |
| Python Pandas Courses | Every Weekday | View Details |
| Python Pandas Courses | Every Weekend | View Details |