To better understand the latest advancements in Generative AI, imagine a traveler exploring a new city.
Imagine a traveler exploring a new city. They know the basics- how to navigate streets, read signs, and communicate- but when they want the best café or a hidden landmark, they don't rely on memory alone. They quickly check a trusted local guide or map before making a decision.
That's how Retrieval-Augmented Generation (RAG) works in modern AI. Large language models already carry vast knowledge, much like the traveler's experience. But instead of depending only on what they've learned, RAG connects them to external data sources in real time. It retrieves the most relevant information and feeds it into the response process.
This approach helps AI move beyond generic answers. It delivers responses that are grounded, up-to-date, and context-aware. In fast-changing domains, RAG ensures AI doesn't just respond- it responds with precision and relevance.
In this article, I will explain what RAG is, how it works, its components, use cases, and more.
RAG (aka Retrieval-Augmented Generation) is an advanced technique in the field of artificial intelligence (AI) that combines the power of information retrieval with natural language generation. Instead of relying solely on pre-trained knowledge, a RAG-based model searches external data sources like documents or databases to find relevant, accurate, and original information before generating a response.
This makes it particularly useful for answering questions, summarizing content, or generating detailed, up-to-date outputs. By pulling in accurate and current data from any source, RAG models improve the relevance, accuracy, and depth of AI responses. It's like giving AI access to a research assistant that can look things up before answering. This technique bridges the gap between static knowledge and dynamic, real-world information, making it a valuable approach in areas like customer support, chatbots, and search engines.

This technique has been around since at least the early 1970s. Back then, researchers created what they called question-answering systems, which used natural language processing to sift through text, starting with focused topics like baseball. The core ideas of text mining haven't changed much over the years, but the machine learning engines that power them have really improved, making them more useful and popular.
In the mid-1990s, Ask Jeeves, now known as Ask.com, made a question answering thing with its well-dressed valet mascot. Then in 2011, IBM's Watson stole the spotlight by beating two human champs on the game show Jeopardy!
An example will be a good way to better understand it.
You are the executive at an electronics enterprise selling smartphones and laptops. The need of the hour is to create a customer support chatbot to answer user queries round the clock. These could be related to product specifications, warranty information, troubleshooting, and much more. Using the capabilities of LLMs (like GPT-3 or GPT-4) can be a good way to power the chatbot.
Large language models come with their own set of limitations that can lead to inefficient customer experience. Some common problems that arise while using these are -
Language models are limited in the sense that they provide generic answers according to training data. It might not be able to provide accurate answers to questions around the software or model you sell. They haven't been trained on organization-specific data. These models' training data have a cutoff date that limits their ability to present updated responses.
They often hallucinate and confidently generate false responses according to imagined facts. Responses can also be off-topic if no accurate answer is available in line with the user's query.
These models usually give generic responses that are not tailored or customized to specific contexts. It's a big drawback in the case of customer support as individual user preferences and queries are needed for a personalized customer experience.
The solution to these issues is RAG. It effectively mends these gaps with ways to integrate the LLMs' general knowledge base and their prowess at accessing specific information. This includes the data in the product database or even in user manuals. Highly reliable and accurate responses are received that are also tailored according to the company's needs.
Related Article- ChatGPT Tutorial For Beginners
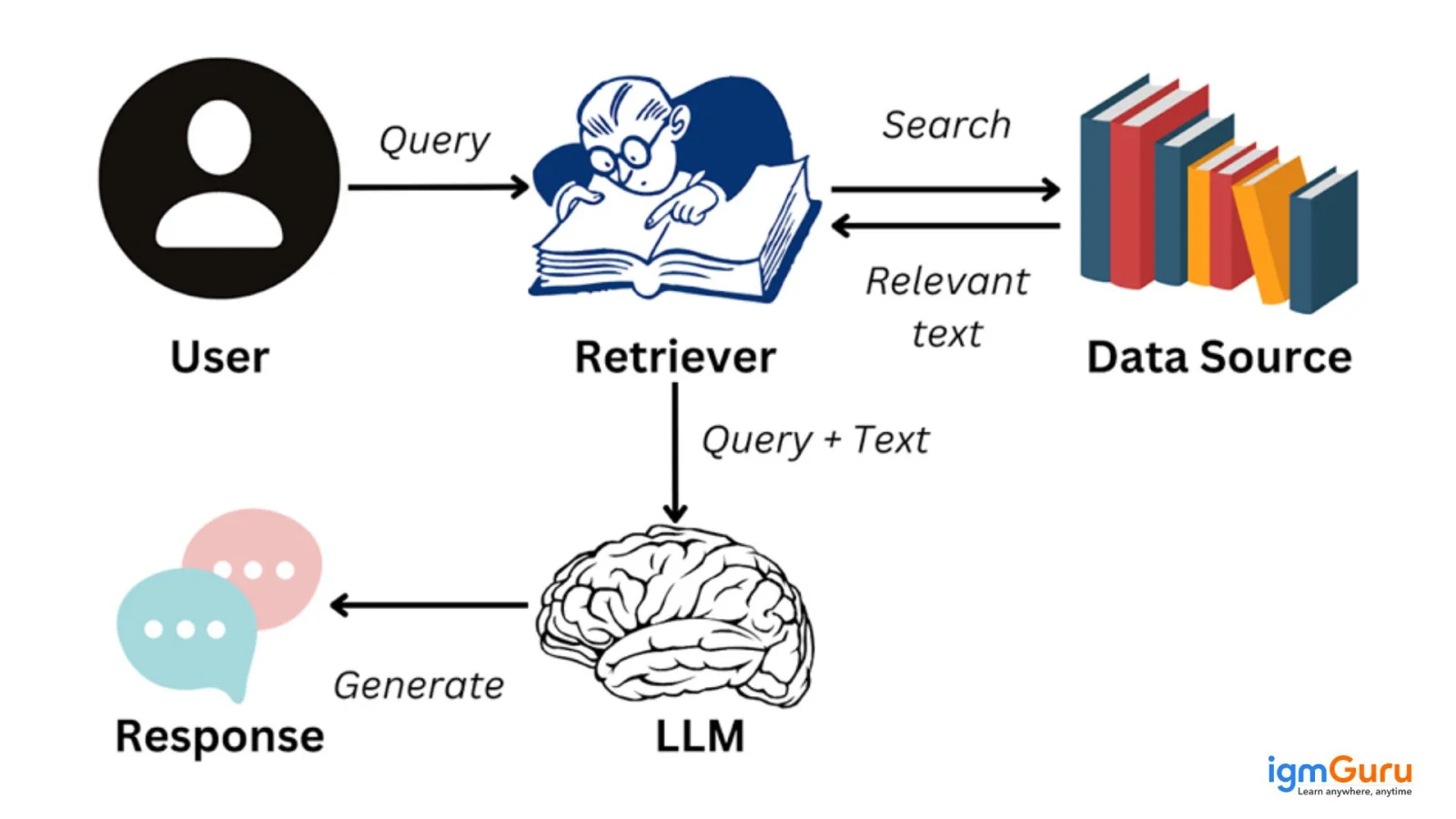
One question that's often asked in addition to 'what is RAG' is how Retrieval-Augmented Generation (RAG) works. Setting up this framework involves these steps and a lot of expertise. These steps must be followed for the best results.
Gather all the needed data for the application. This usually includes a product database, a list of FAQs and user manuals for a customer support chatbot as in the above given example.
It is the process of breaking down the data into smaller and more manageable pieces. A lengthy user manual can be broken down into different sections that each answer different questions posed by the customer. Each chunk becomes a more specific topic-focused. Retrieving a piece of information from the source dataset will more likely be applicable to the user's query. Efficiency gets better as the system quickly obtains the most linked information instead of processing the complete documents.
The source data is converted into a vector representation after it's broken down into smaller parts. This encompasses converting text data into embeddings that are numeric representations capturing the semantic meaning behind text. Document embeddings make the system understand user queries and then match them with associated information in the source dataset. It's matched according to the text's meaning rather than a word-to-word comparison. The responses are hence more relevant and align with the user's query.
The user query must be converted into a vector representation or embedding after it enters the system. The same model should be used for the query embedding and document for uniformity between the two. The query embedding is compared with the document embeddings as the query converts into an embedding. It targets and extracts chunks whose embeddings are akin to the query embedding by using measures like Euclidean distance and cosine similarity.
The initial user query and the retrieved text chunks are fed into a language model. This information is used by the algorithm for generating a coherent answer to the user's query through a chat interface.
Related Article- Best ChatGPT Prompts
Understanding 'what is RAG' is only possible with an answer to 'what are the use cases for RAG'. These three are the most common ones and a must-know for everyone -
Informational queries can be better answered by incorporating LLMs having search engines for augmenting search results with answers generated through LLM. Users can find the information in an easier way that is needed to do their jobs.
LLMs' incorporation with chatbots automatically derives highly accurate answers from the company documents. Chatbots automate website lead follow-up and customer support to quickly resolve issues and answer questions.
Company data becomes the context for LLMs for employees to easily get answers to their queries. HR questions (around policies and benefits), security and compliance questions are answered with ease.
The answer to 'what are the benefits of RAG' is as important as 'what is RAG' for moving ahead. Its benefits are a reflection of its features. More perks are a testament to the impressiveness of this framework.
It is because of this framework that an LLM's response is not only based on static and stale training data. Up-to-date external data sources are used by this framework for providing responses.
LLM uses RAG for contextually relevant responses that are tailored as per the company's proprietary or domain-specific data.
RAG mitigates the risk related to responding with fabricated or incorrect information, which is also called hallucinations. It does so by grounding its output on relevant and external knowledge. Outputs may encompass citations of original sources for human verification.
This framework is simpler and more cost-effective than other approaches used for customizing large language models with domain-specific data. This framework is deployed without any customization to the model. It is beneficial when the models are in need of frequent updates with new data.
LLMs, or Large Language Models, are a big part of AI tech that powers smart chatbots and various natural language tools. The goal is to build bots that can answer questions in different situations by pulling info from reliable sources. But, LLMs have a tendency to be unpredictable in their responses. Plus, they rely on old training data, which means their info can be out of date.
Some common issues with LLMs include:
You can think of an LLM like an overly eager new employee who isn't up to date on current events but answers everything with complete confidence. This can hurt user trust, which is not what you want in your chatbots!
One way to tackle these challenges is with RAG, which helps the LLM grab relevant info from trusted sources. This gives organizations more control over what gets generated, while users can see how the LLM came up with its answers.
Related Article- How To Become A Generative AI Engineer
There are many practical applications of this framework in addition to the customer chatbot example that was discussed earlier in the article. LLMs form coherent responses according to information outside their training data with this framework. This section discusses the top applications of Retrieval-Augmented Generation (RAG) since this aspect is important to get an answer to 'what is RAG'.
Content from external sources is used for producing accurate summaries for considerable time savings. High-level executives and managers are busy people with not enough time to sift through detailed reports. Text data's critical findings are easily pointed at with an RAG-powered app for more efficient decision-making.
RAG systems generate product recommendations by analyzing customer data like past reviews and purchases. User's overall experience gets better and generates more revenue. LLMs are great at decoding the semantics behind text data. RAG systems use these LLMs to give users personalized suggestions that are more refined.
Company's business decisions are influenced by the competitor behavior and market trend analysis. Data present in financial statements, market research documents and business reports is meticulously analyzed. Trends don't have to be manually analyzed and identified with a RAG application. LLMs derive meaningful insight to improve the complete market research process.
Related Article- Skills Required To Become A Prompt Engineer
The architecture for RAG applications is segregated into three primary types. Learning these types is important for understanding 'what is RAG' in depth. These types have their own unique set of characteristics that are also mentioned here.
This is the foundational approach towards this framework. It works on a simple mechanism wherein the system extracts associated pieces of information from a trusted knowledge base according to the user query. These chunks of information become the context for generating an answer through a language model.
Characteristics
Advanced RAG is built upon the key principles of the type mentioned above by adding more sophisticated techniques to better contextual relevance and retrieval accuracy. Integration of advanced mechanisms addresses some main limitations of the former one by improving the way context is handled and used.
Characteristics
It is the most customizable and flexible approach in the entire RAG range. It deconstructs the complete retrieval and generation process into distinct and specialized modules. These modules can be tailored and even interchanged according to the application's specific needs.
Characteristics
RAG systems have four main parts:
1. The knowledge base, which is where all the external data is stored.
2. The retriever, an AI model that looks through the knowledge base for the information you need.
3. The integration layer that keeps everything running smoothly together.
4. The generator, which is another AI model that creates a response using your question and the data it finds.
There can be other parts too, like a ranker that sorts the data by how relevant it is, and an output handler that formats the final response for you.
Explore our Generative AI interview questions with answers to clear all the rounds confidently.
The future of RAGs and LLMs seems to be quite strong. A lot of development and evolution is happening in both these fields. Many new trends are coming forth and a lot of research areas are being discovered too. Here are the emerging trends and the potential improvements that might happen.
Related Article - RAG Tutorial For Beginners
RAG is a practical solution for bettering the capabilities of large language models. Integrating real-time and external knowledge into LLM responses gives this framework the space to address the static training-data challenge. Only current and contextually relevant information is provided by the incorporation of this framework.
Understanding 'what is RAG' is only possible by understanding its different applications, architecture, benefits and use cases. There is a need to learn about its use in improving LLMs for its future scope. Staying up-to-date is extremely important in this time and era and this framework gives reliable means to keep LLMs effective and informed.
Explore Our Trending Articles:
What is Data Warehousing? Everything you need to know
What is Exploratory Data Analysis?
What is Microsoft Azure and How Does it Work?
RAG, or Retrieval-Augmented Generation, can save you money compared to fine-tuning big language models. But the cost for RAG can change based on things like how large and complex the data is, which language model you pick, and what kind of setup you have.
GPT is a big language model that helps with various text tasks. RAG, on the other hand, takes GPT or similar models and adds an external knowledge base to pull in the right info, which makes its answers more accurate and timely.
RAG chain stands for Retrieval, Augmentation, and Generation. It's basically a process to tackle a user's question. First, it figures out what the question is, then it grabs the relevant data, and finally, it uses a language model to come up with a response based on the question and the data.
Course Schedule
| Course Name | Batch Type | Details |
| Generative AI Training | Every Weekday | View Details |
| Generative AI Training | Every Weekend | View Details |

























