When you ask ChatGPT to summarize a report, write an email, or explain a complex concept in simple terms- you're using a Large Language Model (LLM) in action. These large language models are the backbone of today's generative AI revolution, enabling machines to understand and generate impressive outputs with surprising fluency.
As someone who's spent years exploring the evolving world of AI, I can confidently say that LLMs are among the biggest breakthroughs we've witnessed in machine learning today. They don't just "process" text- they understand it, contextualize it, and even respond creatively.
Let's take a friendly deep dive into what makes these models so special, how they work, and why they matter.
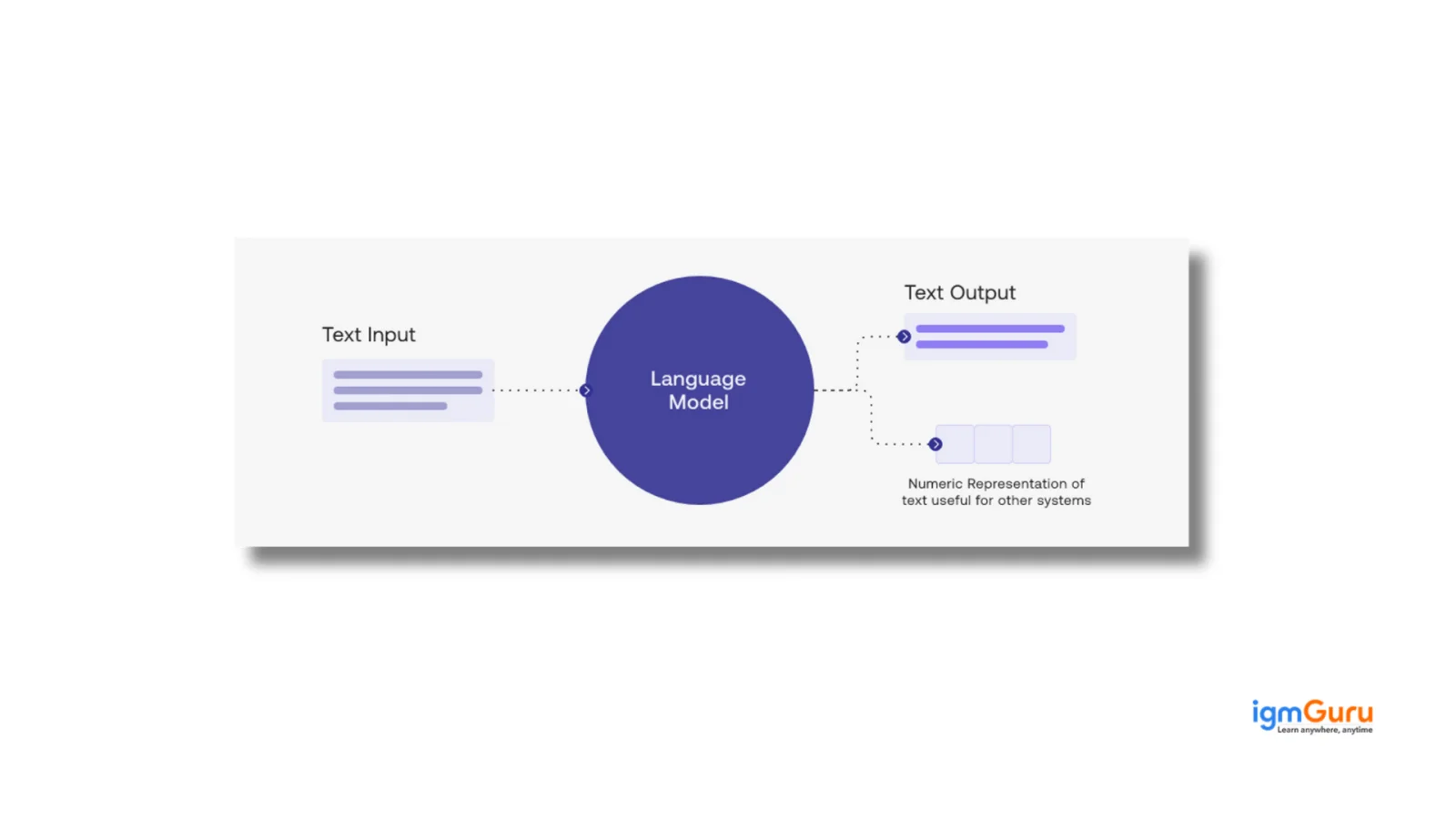
A Large Language Model (LLM) is an artificial intelligence system trained to understand, generate, and manipulate human language.
In simple terms, think of an LLM as a super-smart text engine that has read almost everything available on the internet- from books and research papers to blogs and code repositories- and learned how words relate to each other.
Unlike traditional programs that follow strict rules, LLMs use deep learning and neural networks to identify complex patterns in language. This allows them to predict the next word in a sentence, complete paragraphs, answer questions, write stories, translate languages, and even write code.
Some popular examples include OpenAI's GPT models, Google's Gemini, Anthropic's Claude, and Meta's LLaMA- all built on transformer-based architectures.
Want to gain in-depth knowledge of Gen AI? Explore our Generative AI course program today.
It's fascinating to see how far language models have come.
Let's rewind a little:
From rule-based systems to models with trillions of parameters, LLMs have evolved into something that almost feels conversationally human.
Let's unpack technical concepts while keeping it readable.
LLMs learn by example. During pretraining, models ingest massive corpora (books, web pages, code, articles) and optimize a simple objective: predict the next token (or mask/reconstruct tokens). This unsupervised learning teaches statistical patterns of language, syntax, semantics, and common knowledge embedded in the text.
The pretraining phase is computationally heavy, often requiring distributed GPU/TPU clusters and weeks to months of training time. The result is a foundation model that encodes general language understanding.
Transformers are the backbone of LLMs. Key parts:
This setup gives transformer-based LLMs an elegant trade-off: they model long sentences and documents well, and they parallelize efficiently on modern hardware.
At inference time, you provide a prompt- text that conveys the task, context, or examples. The LLM computes token probabilities and samples or selects tokens to generate output. Prompt style matters: a clear instruction + contextual examples yield better outcomes.
Common prompting strategies:
You can adapt a pretrained LLM for a specific domain via:
For current facts and private knowledge, LLMs often integrate external data via retrieval: query a knowledge base, retrieve top documents, and feed them as context to the LLM. This reduces hallucinations and keeps sensitive data off the model parameters.
Check our Generative AI Tutorial for in-depth knowledge on Gen AI concepts.
Large Language Models (LLMs) have become the backbone of modern artificial intelligence, transforming how humans interact with machines. Their importance lies in their ability to understand, interpret, and generate natural language- allowing computers to communicate the way we do. This human-like understanding bridges the gap between people and technology, making AI accessible to anyone, regardless of technical background.
LLMs power most of today's generative AI tools like ChatGPT, Claude, and Gemini. They enable a wide range of tasks such as text summarization, translation, report writing, and even code generation. Businesses use them to automate customer support, draft marketing content, and analyze massive data sets, boosting efficiency and reducing manual workload. In fact, global studies show that organizations adopting LLM-powered systems have seen productivity improvements of up to 40%.
Beyond efficiency, LLMs also unlock creativity. Writers, developers, researchers, and designers now use these models as collaborative partners to brainstorm ideas, refine concepts, or automate repetitive steps in their workflow. They free up time for innovation by handling tasks that once required extensive manual effort.
Importantly, LLMs form the foundation for next-generation AI systems- from multimodal models that combine text, images, and audio to intelligent agents capable of reasoning and decision-making. Their ability to personalize outputs at scale means they can craft customer experiences, educational materials, and content tailored to individual needs and preferences.
LLMs also play a role in inclusivity and accessibility by translating languages, simplifying complex topics, and generating assistive content for users with disabilities. In short, they are not just technological tools- they represent a new interface between humans and machines. By making communication with AI more natural and intuitive, LLMs are shaping the future of how we learn, work, and create.
LLMs find use across many scenarios- here are the most impactful ones with real-world flavor:
Commanding LLMs to generate text for all kinds of works. Such as:
LLMs play a major role in support and services. Many companies across the world have integrated LLMs in their business operations/models to make the customer journey smooth.
LLMs help developers write, debug, and document code faster by suggesting intelligent completions, generating boilerplate code, and explaining complex logic.
LLMs are also used to quickly analyze unstructured data, summarize insights, and automate reporting.
LLMs accelerate research by scanning vast datasets, summarizing studies, and generating hypotheses, making them invaluable in fields like healthcare, finance, and scientific innovation.
Always apply domain constraints and human-in-the-loop verification when the stakes are high.
Read Also- Generative AI Interview Questions
LLMs come with many advanced features and some of them are given below.
LLMs model semantics, syntax, and pragmatics to interpret user intent. They detect sentiment, extract entities, and resolve context-dependent references. For product teams, this means less hand-crafted intent parsing and more robust, flexible conversation flows.
Practical tip: Use few-shot examples for domain-specific intent detection, and validate outputs using a small labeled test set.
Latest LLMs can process images, audio, and text. For example, you might give an image of a chart and ask for a caption, or feed a customer call recording and ask for a summary plus action items.
Practical tip: Multimodal chains often combine specialized vision or audio encoders with language decoders- treat them as pipelines and validate at each stage.
LLMs understand programming languages and patterns. They can scaffold new features, suggest fixes, and generate docstrings. This boosts developer onboarding and reduces context switching.
Practical tip: Always run generated code through static checks, linters, and unit tests. Use LLMs to assist, not to produce final production code without review.
By carefully crafting prompts (and optionally providing a few examples), you can get models to perform specific tasks reliably. This is the "prompt-as-a-program" approach.
Practical tip: Create standardized prompt templates for recurring tasks (e.g., summarization, email drafting), and version them for reproducibility.
LLMs can scale in capability with more data and compute. At the same time, methods like quantization, distillation, and adapter tuning enable practical deployments on constrained infrastructure.
Practical tip: For latency-sensitive applications, explore smaller distilled models or hybrid architectures (edge + cloud inference) to balance performance and cost.
Large Language Models (LLMs) are transforming how we work, create, and communicate. However, while they bring immense potential, they also come with notable challenges. Let's look at both sides clearly.
LLMs can handle multiple language-related tasks- from writing articles and summarizing text to generating code or translating languages- all without additional training.
They can process and produce information in seconds, drastically reducing the time needed for research, writing, or analysis.
LLMs act as brainstorming partners, helping users generate ideas, refine content, or even suggest new approaches to problem-solving.
Anyone can interact with LLMs using plain language, making AI tools accessible to non-technical professionals and students alike.
As models evolve with better training data, they become more accurate and context-aware, providing smarter and more reliable responses over time.
By automating repetitive tasks, LLMs free up time for humans to focus on creative and strategic work, improving overall productivity.
LLMs may generate false or misleading information, especially when asked about topics outside their training scope.
Since they learn from large online datasets, LLMs can unintentionally reflect societal or cultural biases present in that data.
It's difficult to trace how or why an LLM arrives at a specific response, making them less transparent for critical or regulated tasks.
Training and running LLMs require significant computational power and energy, making them costly to develop and maintain.
If sensitive or proprietary data is used during training, it may risk exposure or misuse, raising ethical and legal issues.
Despite their intelligence, LLMs still require human supervision to verify facts, ensure fairness, and apply ethical judgment.
Read Also: Claude vs. ChatGPT: What's the difference?
Here's a clear, point-by-point comparison showing how Large Language Models (LLMs) differ from other traditional AI models in terms of structure, function, and use cases:
| Feature / Aspect | Large Language Models (LLMs) | Traditional AI / Machine Learning Models |
| Core Purpose | Understand and generate human-like language; perform diverse language-based tasks. | Designed for specific, pre-defined tasks like classification, prediction, or detection. |
| Architecture | Based on transformer neural networks using self-attention mechanisms. | Often use simpler algorithms like regression, decision trees, SVMs, or CNNs (for images). |
| Data Type | Primarily unstructured text data; can also handle multimodal inputs (text, image, audio). | Usually structured or domain-specific data (numerical, categorical, or image-based). |
| Learning Approach | Unsupervised / self-supervised learning using massive text datasets. | Often supervised learning- trained with labeled data for each task. |
| Flexibility | Extremely flexible- a single LLM can perform multiple tasks (translation, summarization, Q&A). | Task-specific- each model is trained separately for a particular purpose. |
| Context Understanding | Deep contextual and semantic understanding of human language. | Limited to pattern recognition; lacks broader language comprehension. |
| Output Type | Natural language text, code, summaries, answers, or even multimodal content. | Usually structured outputs like numeric values, labels, or probabilities. |
| Human Interaction | Conversational and interactive; understands prompts written in plain English. | Requires predefined inputs or features; less intuitive for non-technical users. |
| Adaptability | Can adapt to new tasks through prompting or light fine-tuning. | Needs full retraining or new models for every new task. |
| Transparency / Explainability | Often considered a "black box"- difficult to interpret internal reasoning. | Easier to interpret (especially rule-based or smaller models). |
| Accuracy & Reliability | High linguistic fluency, but can produce factual errors (hallucinations). | Generally more predictable but less creative or flexible. |
| Ethical & Privacy Risks | Higher- due to data bias, hallucinations, and potential data leakage. | Lower- typically limited to their specific dataset and function. |
Explore our detailed guide on Generative AI vs. Large Language Models
Large Language Models (LLMs) are transforming industries by automating tasks, enhancing creativity, and improving decision-making. Here are four practical use cases that show how these models are being applied in the real world:
LLMs are powering intelligent chatbots and virtual assistants that can handle customer inquiries in natural language.
They can answer FAQs, process refund requests, provide product recommendations, and even understand customer emotions through sentiment analysis.
This not only reduces response time but also frees human agents to focus on complex issues that require empathy and critical thinking.
Many companies now rely on LLM-driven bots for 24/7 multilingual support, making customer service faster and more cost-effective.
Marketers and writers use LLMs to create blogs, product descriptions, ad copies, and social media posts in seconds.
These models understand tone, style, and context- helping teams produce high-quality content that matches brand voice and audience needs.
They can also optimize existing content for SEO, generate personalized emails, or brainstorm creative ideas.
With the right prompts, LLMs can act as content co-writers, saving time while boosting creativity and consistency across campaigns.
Developers are using LLMs to write, debug, and explain code across multiple programming languages.
Models like GitHub Copilot and ChatGPT can generate function templates, suggest logic corrections, and document complex code segments instantly.
This improves developer productivity and reduces manual workload, especially for repetitive tasks like unit testing or code formatting.
In short, LLMs serve as AI-powered coding assistants, making software development faster and more efficient.
LLMs help professionals analyze large volumes of text data from research papers and reports to customer feedback.
They can summarize findings, extract patterns, and even generate insights in natural language.
Researchers use them to scan academic literature, generate hypotheses, or translate complex technical material into simple summaries.
This makes LLMs powerful tools for data-driven decision-making and knowledge discovery, particularly in sectors like healthcare, finance, and education.
The future of Large Language Models (LLMs) looks incredibly promising as they continue to evolve beyond text-based tasks. We're already seeing a shift toward multimodal models that can understand and generate not just text, but also images, audio, and even video. This means future LLMs will be able to interpret visuals, listen to speech, and respond intelligently in real time- creating more natural and human-like interactions. We can also expect smaller, faster, and more efficient models that run on personal devices or private servers, allowing organizations to use AI safely without sharing sensitive data.
In the coming years, LLMs will move from being just assistants to becoming autonomous AI agents capable of planning, reasoning, and performing actions independently. They'll integrate deeply with tools, databases, and APIs to carry out complex workflows- like managing projects, analyzing reports, or handling customer requests end-to-end. At the same time, there will be a stronger focus on ethics, transparency, and regulation to ensure these systems remain trustworthy. Overall, the future of LLMs will revolve around making AI more intelligent, efficient, and human-aligned, shaping how we work, learn, and connect with technology.
Large Language Models (LLMs) have reshaped how humans interact with technology. They understand, generate, and respond to language naturally, helping automate tasks, boost creativity, and improve decision-making. As LLMs evolve, they'll become more efficient, ethical, and capable of reasoning across multiple domains. With responsible use, these models will continue to enhance productivity, bridge human-machine communication, and power the next wave of intelligent innovation.
A Large Language Model is an AI system trained on massive text data to understand and generate human-like language.
LLMs learn using deep learning and transformer architectures that identify patterns, meanings, and relationships between words in large datasets.
They’re used in chatbots, content creation, coding assistance, customer support, translation, and data analysis across industries.
Not always. While they're highly advanced, LLMs can produce incorrect or biased information, so human review and verification remain essential.
Course Schedule
| Course Name | Batch Type | Details |
| Generative AI Training | Every Weekday | View Details |
| Generative AI Training | Every Weekend | View Details |