
The demand for big data is rising day by day, and more businesses are turning to cloud data warehouses. The only way to manage today's massive data volumes is through the cloud platform. Snowflake falls in one of the most well-known cloud data solutions in today's market. More than 5774 organizations make use of this platform. This blog will provide an in-depth understanding of the Snowflake architecture, Snowflake data warehouse, components of data warehouse architecture and more.
A central information warehouse that authorizes Data analytics and business intelligence activities is called a data warehouse. It can store massive amounts of data from multiple sources in one location. It runs queries and does analyses for businesses to improve their operations. Data warehouse skills let businesses profit from similar insights from their data and help them in better decision-making. So what is Snowflake Data Warehouse? It is a solution that helps ANSI SQL and is obtainable as a SaaS (Software-as-a-Service). Snowflake data warehouse offers its users the ability to build tables faster and start querying data with less administration. This has a very distinctive architecture.
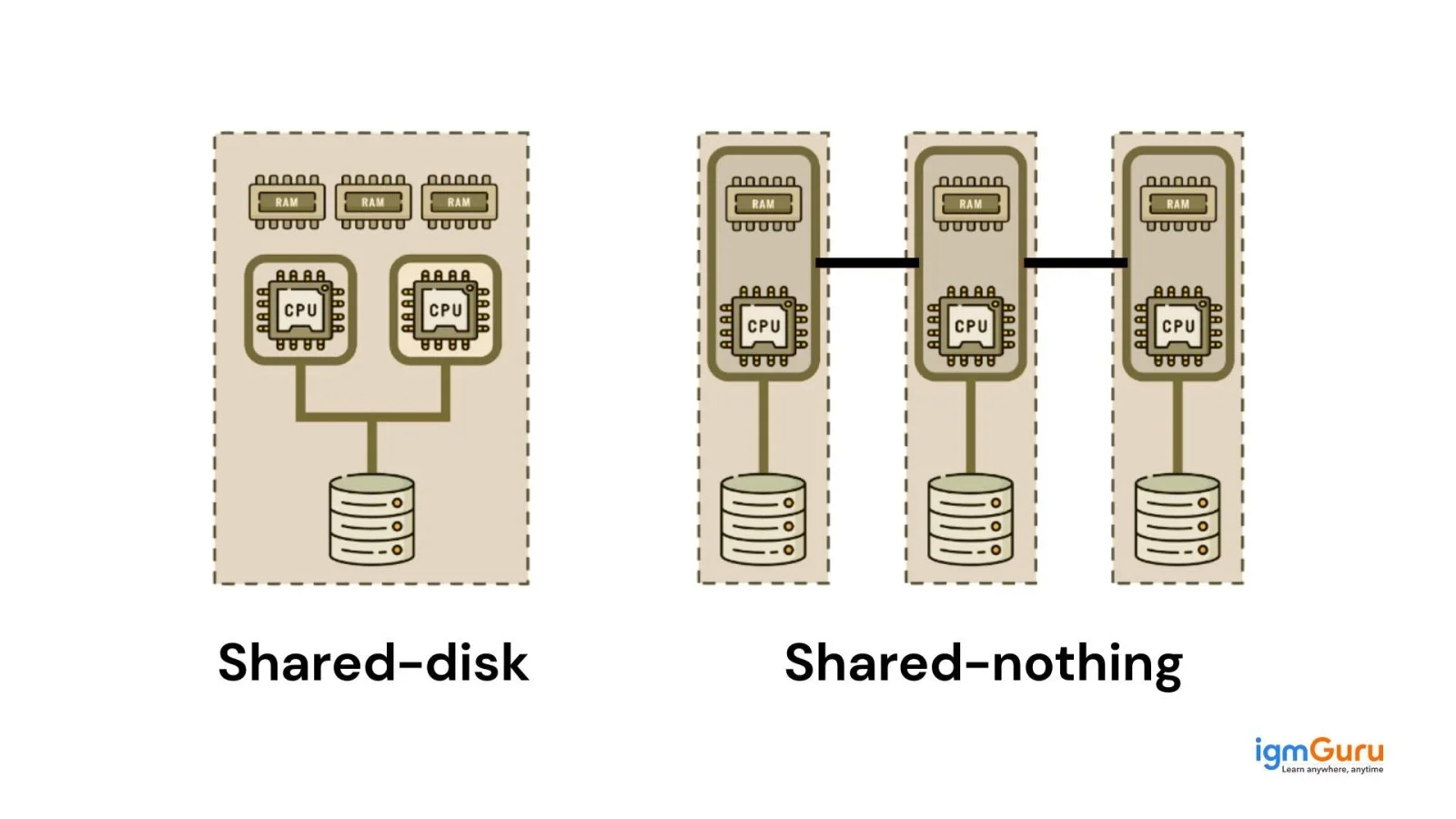
To understand the Snowflake architecture, we first need to understand the Snowflake data warehouse architecture. Let us take a look at the share disk and shared-nothing architectures.
Entire processing units in this system share the same disk or storage device. Even though each processor has its memory, all nodes have gained access to all the disks. As all the nodes have the access to the same data, cluster control software is required for monitoring and controlling data processes. Every node has a copy of the data when modified or deleted. Editing more than two processors simultaneously should not be allowed.
This is basically suitable for vast computing that needs ACID compliance. Services and applications that need limited shared access to data and applications are tougher to split and are well-suited for a shared disk. An example of a shared disk architecture is Oracle Real Database Clusters.
In a shared-nothing architecture, every processor has its own memory and storage or disk space. The nodes can communicate with one another because of the interconnected network connections. After getting a processing request, a router paves the way to the proper computing node for accomplishment. Particular business rules are usually used at the routing layer for routing obstacles to every cluster node. When a computer node fails, it shifts the processing rights to different cluster nodes.
There won't be any interruption in the user's requests anymore since the change of ownership. A shared-nothing architecture offers the application with scalability and high availability. Among the first web-scale technology companies to deploy shared-nothing architectures, Google runs shared-nothing clusters with thousands of computing units. Because of this, a shared-nothing architecture is the perfect approach for a complicated analytical data processing system similar to a data warehouse.
There are many components of Data Warehouse architecture, let us take a look at its components and tasks.
It is a data source that includes Operational data and external data. The data may come from Relational DBMS such as Oracle, Informix.
It does all the operations related to the extraction of loading data in the data warehouse. These tasks involve the simple transformation of data for preparing data for entering in the warehouse.
A database is an important component of a data warehouse. It stores and gives accessibility to company data. Platforms like Azure SQL and Amazon Redshift come under a cloud-based database service.
All the operations related to the Extraction, Transformation and Loading (ETL) of the data in the warehouse fall under this component. The Traditional ETL tools are for extracting data from different sources, changing it to an edible format and finally loading in the data warehouse.
It gives a framework and descriptions of data, allowing the construction, handling, storage and usage of the data.
A warehouse manager is responsible for the warehouse management procedure. The operations done by the warehouse manager are analysis, aggregation, backup and collection of data, and denormalization of the data.
The access tools lets users access actionable and business-ready information from a Data Warehouse. These Warehouse tools involve data reporting tools, data querying tools, application development tools, data mining tools and OLAP tools.
A query manager does all the tasks related to the management of user queries. The difficulty of the query manager is regulated by the end-user access operations tool and the features given by the database.
Detailed data is used to store all the data in the database schema. It is loaded in the data warehouse to store the data collected.
It is a part of the data warehouse that stores prearranged aggregations. These groupings are generated by the warehouse manager.
The detailed and summarized data are stored for the purpose of archiving and backup. That data is relocated to the storage archives like magnetic tapes or optical disks.
Related Article- Databricks vs Snowflake: Similarities and Differences
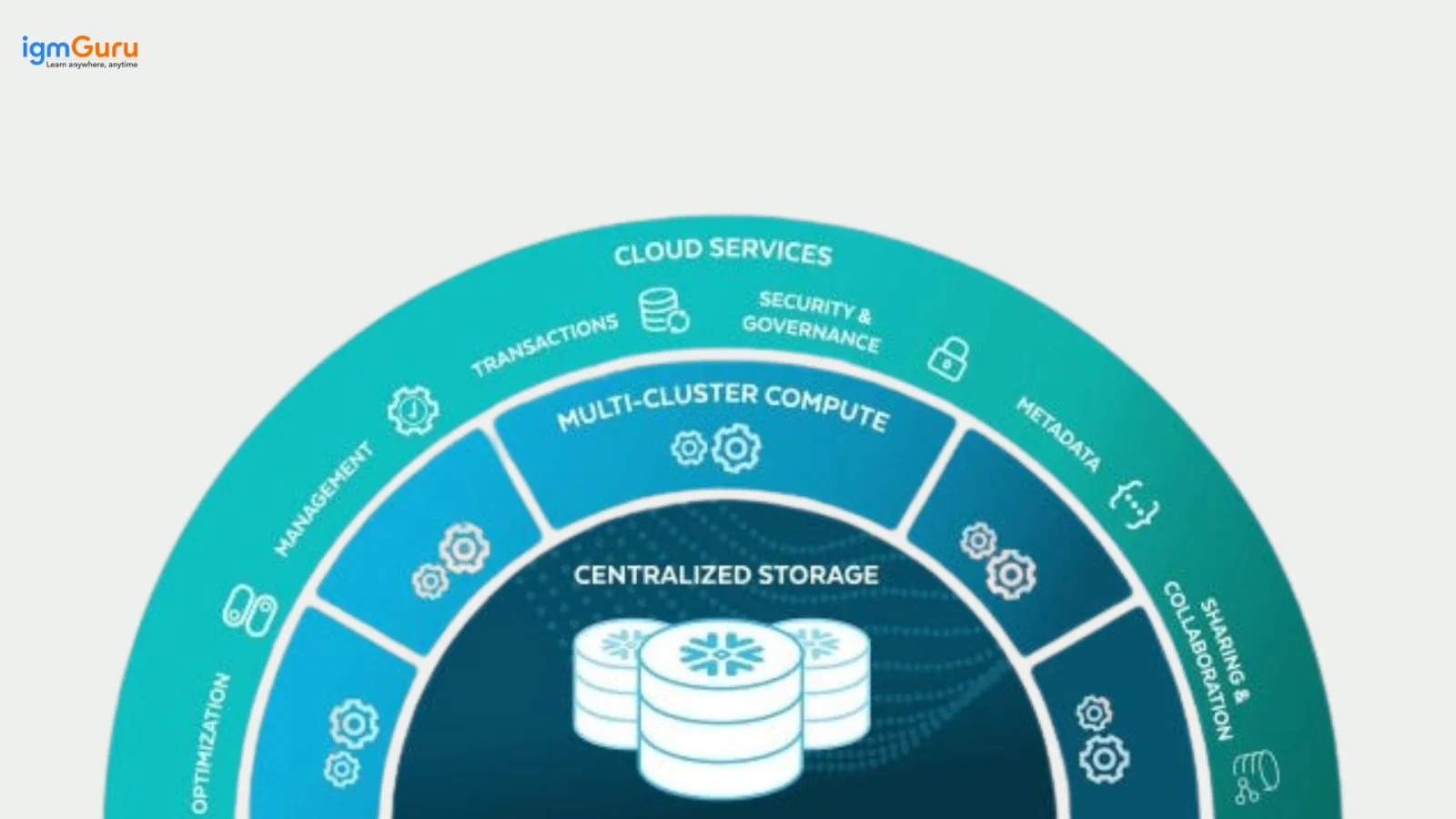
The Snowflake architecture has a hybrid of traditional shared-disk and shared-nothing architectures for providing the best of both worlds. It is a hybrid of traditional shared-disk and shared-nothing database architectures. It's similar to shared-disk architectures as it uses a central data repository for persevere data which is accessible from all compute nodes in the platform. Now, have a look at the Snowflake's architecture which has three layers - Database Storage, Query Processing and Cloud Services.
After the data is stored in the Snowflake, it reorganizes the data in its internal upgraded, columnar and compressed format. This platform preserves this optimized data in the cloud storage.
This platform handles all the features of how the data is preserved. The company, file size, structure, statistics, metadata and other features of data storage are managed by this platform. The data objects which are stored in the Snowflake aren't visible directly nor accessible by the clients. They are only accessible via SQL query operations done through Snowflake.
The query execution is done in the processing layer. This platform operates queries through 'virtual warehouses'. Every single virtual warehouse is an MPP compute cluster collected by many compute nodes assigned by this platform from a cloud provider.
Every virtual warehouse is a powerful compute cluster which doesn't share the resources accompanied by other virtual warehouses. Every virtual warehouse does not have any impact on the performance of different virtual warehouses.
This layer is a bunch of services which coordinate activities all over this platform. These services get together with all of the different features of Snowflake in order to perform client requests, from login to query dispatch. This layer also performs on compute instances supplied by this platform from the cloud provider. The services handled in this layer involve -
Related Article- Snowflake Tutorial - A Complete Guide For Beginners
The three layers of architecture include a compute layer, storage layer, and cloud services layer. Compute layer manages query processing, storage layer handles statistics storage and the cloud services layer vows to metadata control and cooperation. This allows scalability, flexibility and green facts processing in a cloud based statistics warehouse.
The architecture gives power to businesses to tackle the power of data to stay ahead in the competition industry. All these features make it essential for an individual to launch their Snowflake learning journey.
Unlike traditional databases, Snowflake separates storage and computation that allows them to scale independently. It also runs entirely on cloud infrastructure.
The architecture has three layers, which are Database Storage Layer, Cloud Services Layer and Query Processing Layer.
A virtual warehouse is a compute cluster that processes queries. Each warehouse operates independently and can be resized or paused as needed.
Yes. Snowflake supports concurrent usage through multi-cluster compute. This ensures the workload of one user does not impact another.
The Snowflake Schema is preferred in MicroStrategy architecture for managing parent-child attribute relationships.
Yes, it is a multi-cluster architecture that lets one support as many separate workloads as one can dream of. One can provide every workload its own compute engine and rest peacefully.





















