Are you looking for a guide on Snowflake interview questions and answers to prepare for Snowflake interviews? Do not look further! This interview question guide is specially designed to help individuals like you. Nowadays, data is empowering businesses to reach new heights, and organizations also face significant challenges in managing large volumes of data.
This is why the demand for Snowflake professionals has emerged, as it is one of the leading data warehousing platforms. This interview guide covers various key topics like architecture, data storage, caching types, data sharing, and many more. Let's get started.
Read Also - Snowflake Tutorial - A Guide For Beginners
This section includes the top Snowflake interview questions for beginners. It covers some of the most important fundamental concepts, terms and definitions.
Snowflake is a software-as-a-service (SaaS) and cloud-based data warehousing (DWH) platform. It stores and manages large amounts of information by using the scalability and performance of the cloud. Snowflake is a cloud-native data platform that runs on major cloud providers, including AWS, Microsoft Azure, and Google Cloud Platform. It was initially designed as a cloud data warehouse but has now evolved into a complete data platform supporting data engineering, analytics, AI/ML workloads, and application development.
It can now store, process and analyze large data sets with ease. This DWH platform is unlike the other traditional ones as it separates the computing and storage. It unlocks a feature to manipulate storage and computing power according to their requirements. This feature reduces the additional hardware cost and improves the performance of the system.
Listed below are some of the best features of this cloud-based platform -
Following are the caching types of this DWH platform -
Listed below are the available ELT tools of this DWH solution -
Columnar databases store information in columns instead of rows. This makes them entirely different from the conventional ones. It simplifies query processing and data analytics. This leads to more incredible performance of data banks. These data banks are the future of business intelligence.
Snowflake computing refers to the compute layer of the Snowflake architecture, which uses virtual warehouses to process SQL queries, perform transformations, and run workloads independently from storage. This separation of compute and storage allows workloads to scale independently and improves concurrency. It does not use a big database like other software platforms. Hence, it combines a completely new SQL query engine with a cloud-based architecture.
Here is a list of the top Snowflake interview questions for intermediates that can be asked during interview rounds. These are suitable for individuals who have decent experience in this field.
This SaaS solution automatically organizes data into compressed columnar micro-partitions stored in cloud storage. These micro-partitions contain metadata such as min/max values and statistics, which help Snowflake perform automatic query pruning and optimization. This data will be stored in the form of columns in cloud storage and is not accessible for the users. They will have to run SQL query operations to access them.
A stage is a location used for loading or unloading data files into Snowflake tables. It acts as an intermediate storage location between Snowflake and external storage systems. This ELT platform has two types of stages, including internal and external. As their name suggests, they are responsible for uploading and downloading files in internal and external locations. Snowflake supports three types of stages:
• User Stage
• Table Stage
• Named Stage
Mentioned below are some of the common drivers and connectors available on this tool:
The database storage layer is responsible for organizing the columnar, compressed and optimized information. It deals with data storage, which comprises data statistics, data management, data compression, file size and many more. Each of these information is inaccessible and invisible for the users.
Virtual warehouses are a cluster of compute resources and are responsible to perform the data management tasks. This would be an MPP (Massively Parallel Processing) server on a traditional on-site database. These clusters extract the minimal data required to perform a query from the storage layer. These resources are temporary storage, CPU and memory which perform SQL execution and DML operations.
Cloud data warehouses can be accessed in different ways. Listed below are some of these methods -
Related Article - Databricks vs Snowflake: Similarities and Differences
These Snowflake interview questions for experienced professionals are most suitable for higher posts. These can assist individuals to land a high-paying job in a reputed organization. Let's start!
Time travel is a feature of this platform that gives access to the modified information. It might be deleted or simply changed for a particular time. This feature is often used for backup, duplication and analysis of old data and restoring schemas, tables, etc. Here are some of its instances -
The resource monitors are the feature of this DWH tool that control costs and avoid unwanted credit usage. These track and manage the use of compute resources while ensuring costs remain in budget. Resource monitors are very useful for the multi-team environment and can be used for a particular warehouse or entire account.
One can use them by -
Metadata service is a part of the cloud service layer. It handles data, optimizes queries, traces data location and accesses metadata and patterns for columns, tables, etc. This retrieving method enables data pruning while executing a query. The metadata service also maintains micro-partition metadata, which allows Snowflake to skip scanning irrelevant data blocks during query execution.
This service also manages and updates the result cache for faster query retrievals when identical queries are executed. It improves the performance by reducing the amount of data that has to be scanned. This means it reduces resource consumption and enhances query efficiency.
Compression is used for obtaining the conveniences listed below -
ANSI SQL (American National Standards Institute Structured Query Language) is used in relational database management systems. These standards familiarize professionals with SQL operations and syntax for querying data. This data is like JOINs which makes it a great feature for experienced professionals in SQL.
Another advantage of this compatibility is the continuous integration of several data types. This gives professionals an advantage to query their data without requiring a load or transforming it into a predefined schema.
Snowpark lets developers use languages like Python, Java, and Scala to run data pipelines, transformations, and ML workloads directly in Snowflake.
Read Also- Snowflake Architecture And Its Components
This section consists of advanced Snowflake interview questions and answers that are frequently asked in senior-level technical interviews.
Cortex is Snowflake's AI platform for building and running AI/ML and LLM-based applications directly within Snowflake using SQL or Python.
Snowflake Horizon is the governance framework of Snowflake that helps organizations manage data security, compliance, and discovery. It provides tools for data lineage, access control, tagging, and policy enforcement across the Snowflake platform. This framework helps enterprises maintain better visibility and control over their data assets.
Snowpark Container Services allow developers to run containerized workloads directly inside Snowflake. It enables organizations to deploy machine learning models, data pipelines, and custom applications using technologies like Docker while keeping the data inside the Snowflake environment. This feature helps teams build advanced data applications without moving data outside the platform.
Iceberg Tables allow Snowflake to work with open table formats stored in external cloud storage. They are based on the Apache Iceberg table format and enable organizations to build open data lake architectures while still using Snowflake for analytics. This feature improves interoperability between Snowflake and other data platforms.
Dynamic Tables are used to automatically maintain the results of a query as the underlying data changes. They work similarly to materialized views but are designed for modern data pipelines. Dynamic Tables help simplify data transformation workflows and support near real-time data processing.
The Snowflake Native App Framework allows developers and organizations to build data applications that run directly inside Snowflake. These applications can be shared with other Snowflake accounts without copying the underlying data. This framework enables companies to build secure data products and distribute them through the Snowflake marketplace.
Snowflake Cortex is Snowflake’s built-in AI and machine learning service. It allows users to run large language models (LLMs), perform semantic search, text summarization, sentiment analysis, and other AI tasks directly inside Snowflake using SQL or Python — without moving data outside the platform. It is widely used for building generative AI applications and intelligent analytics.
Dynamic Tables are a declarative way to build and maintain data transformation pipelines. They automatically refresh the results of a query as source data changes. Unlike Materialized Views (which mainly improve query performance and have limitations on complex joins), Dynamic Tables support complex transformations, can depend on other Dynamic Tables, and are ideal for building reliable ETL/ELT pipelines with controlled refresh lags.
Snowpark is a developer framework that allows you to write data pipelines and transformations using Python, Java, or Scala directly in Snowflake. It pushes the computation to Snowflake’s engine instead of pulling data to the client side. Use Snowpark when you want to leverage familiar programming languages for complex data engineering, machine learning, or custom logic while keeping everything inside Snowflake for security and performance.
Iceberg Tables allow Snowflake to work with the open Apache Iceberg table format stored in external cloud storage (S3, Azure Blob, GCS). This feature enables organizations to build open data lake architectures while still using Snowflake’s powerful query engine for analytics. It improves interoperability, avoids vendor lock-in, and supports features like schema evolution and time travel on open tables.
Snowflake offers several tools for cost control: Virtual Warehouse sizing (scale up/out), Auto-suspend and Auto-resume, Resource Monitors (to set credit limits and trigger actions), Query Profile for identifying expensive queries, and Search Optimization Service. Experienced candidates are expected to explain how they balance performance with cost using multi-cluster warehouses and appropriate scaling strategies.
This section consists of Snowflake architect interview questions. These frequently asked questions can be a ladder to get an architect job role.
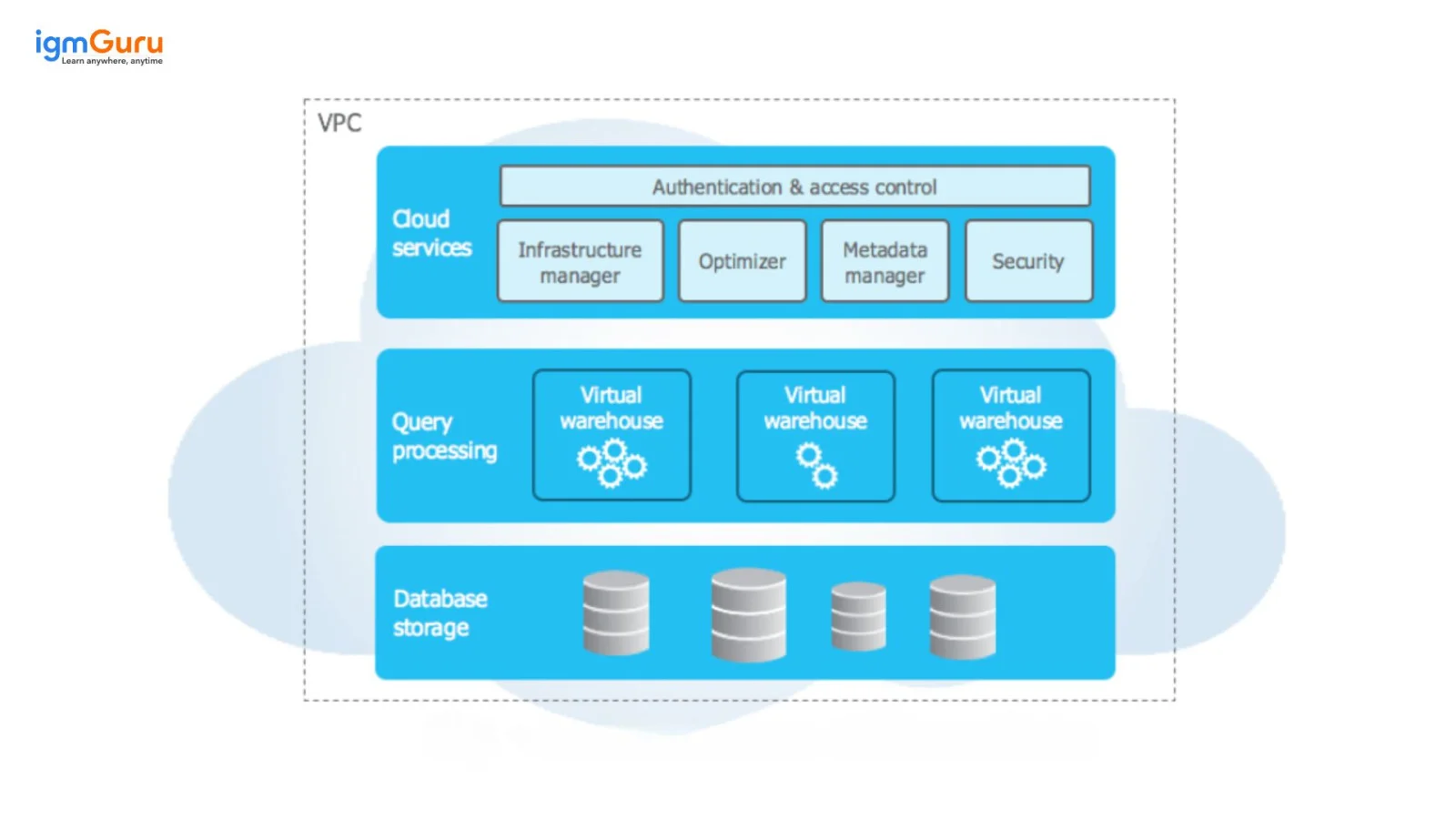
The architecture of this platform is a combination of shared-nothing and shared-disk architectures. It uses a central data repository to access data that is available to all compute nodes in the platform. This is the property of a shared-disk infrastructure.
It processes queries with massively parallel processing (MPP) compute clusters in which every node of a cluster saves a part of the entire data set. This is a property of shared-nothing infrastructure. The architectural design of this web tool is divided into three layers including -
It is a logical suite of database objects like views, tables, etc. This schema is built by fact tables that are linked and centralized in multiple dimensions. It is a multi-dimensional data architecture which is an extension of a Star Schema. The dimension tables are normalized, which splits data into additional tables.
Schemas are basically logical descriptions of the entire database. It indicates how information is stored in data stores.
A virtual warehouse is a cluster of compute resources that runs your SQL queries. It is the "compute" part of the separation of storage and compute. You can scale it up for more power or out for more concurrency to handle different workloads and you only pay for the time it is running. It executes various operations including -
This data warehousing platform has three layers of mechanism to protect the data. These security layers are as follows -
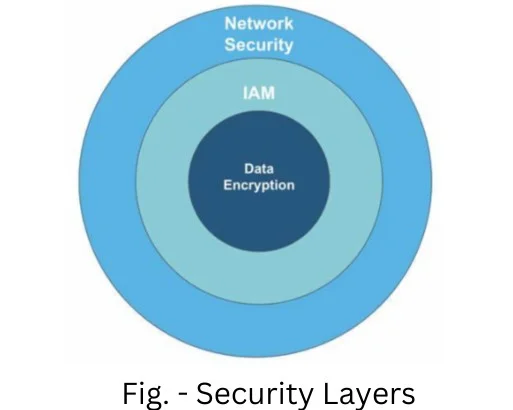
Network Security - It is the first line of defense which secures the data using the following practices-
i) Network policies
ii) Private connectivity
iii) Firewall for client applications
iv) Access control of data storage locations
These policies only allow the known client to access the information and block other ones.
Identity and Access Management - This is the next layer of defense that authenticates users for connecting with data banks. These users are created in the Snowflake prior to any access. This layer includes the following practices -
i) User and role management
ii) SSO and authentication
iii) Sessions
iv) Row, object & column level access control.
Snowflake also supports Row Access Policies, Dynamic Data Masking, Object Tagging, and Governance policies to enforce data security and compliance.
Data Encryption - The information stored in data stores are in the form of encrypted key hierarchy to give enhanced security. The system will encrypt information in different sections with particular keys for each one in this layer. These keys are rotated every 30 days with new hierarchies. The following are the best practices of this layer -
i) Tri-secret & review
ii) CMK (Customer Managed Key)
iii) Periodic Rekeying
iv) Built-in Encryption Functions
You May Also Read- Python Interview Questions
Experience is not the only aspect of job requirements. Some jobs are specified for particular roles. Here are the top Snowflake admin interview questions that are frequently asked in admin interviews.
Data sharing is a feature of this platform by which organizations can share their information securely. They can share real-time data with users and their partners without copying it. This feature is achieved using multi-cluster shared data architecture and secure data sharing functionality. It has various advantages including -
Zero copy cloning is a method to build duplicate tables, schemas and databases without copying underlying storage. The clone data will point to the original data and only store the changes made in this process. This means clone data will not require major data storage. This method is very useful during development, testing and building historical snapshots.
Fail safe is a method to recover the data that has been modified or deleted during time travel. Time Travel allows users to access historical data for 1 to 90 days depending on the Snowflake edition and configuration. After the Time Travel period ends, the data enters Fail-safe, a 7-day recovery window managed by Snowflake support for disaster recovery purposes. Where fail safe is a seven-day procedure that recovers the information slowly for disaster recovery. This restored information is highly secured and can not be accessed by every individual.
OLAP (Online Analytical Processing) is a software tech that can analyze business data in various points of view. This tech caters complex queries, large-scale data tasks and many more. OLAP has various features that give efficient analytical processing including -
OLTP (Online Transaction Processing) are workloads that are useful when multiple changes are done by several users. These changes are called transactions that can be categorized as high volumes of short transactions like update and insert. OLTP is focused on operational databases rather than warehousing solutions.
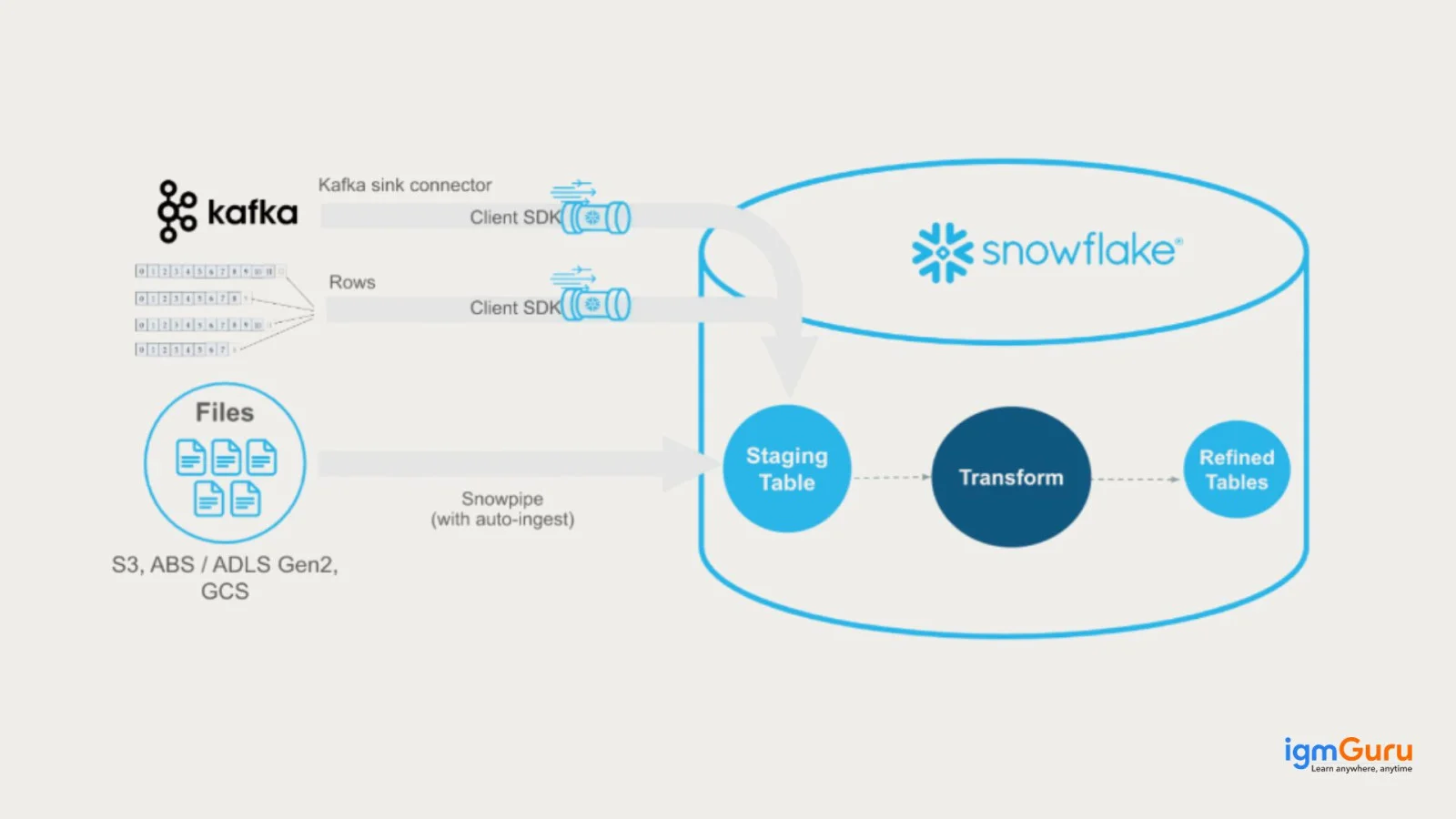
Snowpipe is a continuous data ingestion service that can load files within a few minutes. It loads data in micro-batches automatically when new files arrive in cloud storage by which all individuals within an organization can easily access the data. This simplifies the analysis process. Here professionals can specify data stores and tables where information has to be loaded.
It is an automated process where it detects freshly uploaded files and loads it into specific tables. This process ensures that data is available as soon as possible. Snowpipes are operated on serverless architecture where it streamlines the compute resources that are required for ingestions.
Read Also- Data Analytics Tutorial for Beginners
This section includes the top Snowflake data engineer interview questions that are commonly asked in modern data engineering interviews. These questions focus on ETL pipelines, data ingestion, transformations, orchestration, and real-time processing.
Streams are used to track changes made to tables including INSERT, UPDATE, and DELETE operations. They enable Change Data Capture (CDC) functionality in Snowflake and are commonly used with Tasks to build incremental data pipelines and automate ELT workflows.
Snowpipe is designed for continuous and automated data ingestion in near real-time, whereas bulk loading is generally used for loading large volumes of batch data manually or on schedules using the COPY INTO command. Snowpipe is serverless and event-driven while bulk loading typically uses virtual warehouses.
Data engineers optimize ETL pipelines in Snowflake by using clustering keys, query pruning, appropriate warehouse sizing, auto-suspend and auto-resume features, Streams and Tasks for incremental processing, and partition-aware query design. They also reduce unnecessary data scans and use caching wherever possible.
Tasks are used to schedule and automate SQL operations in Snowflake. They help data engineers build automated workflows for transformations, aggregations, and incremental data processing. Tasks can also be chained together to create complete pipeline orchestration workflows.
Snowflake supports semi-structured data formats like JSON, Avro, ORC, Parquet, and XML using the VARIANT data type. Data engineers can query nested structures directly using SQL functions without converting the data into relational formats before loading.
Listed below are the frequently asked Snowflake coding interview questions that can be asked by panel. This list is designed to cater individuals who want to land a job as a developer in this field.
Virtual warehouses are built with SQL or online interfaces. Developers have three different methods to create these warehouses including -
CREATE [ OR REPLACE ] WAREHOUSE [ IF NOT EXISTS ] [ [ WITH ] objectProperties ] [ [ WITH ] TAG ( = '' [ , = '' , ... ] ) ] [ objectParams ] |
Creating a stored procedure task is a process of few steps that are mentioned below -
CREATE TASK daily_sales_igmGuru WAREHOUSE = 'igmGuruwarehouse' SCHEDULE = 'USING CRON 0 1 * * * UTC' AS CALL daily_sales_igmGuru(); |
It can be done by using the 'TASK_HISTORY' table function. This gives detailed information of task execution history within a time period.
SELECT * FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY( TASK_NAME => '', START_TIME => '', END_TIME => '' )) ORDER BY SCHEDULED_TIME DESC; |
It can be done by using 'CREATE TEMPORARY TABLE' statement as shown below -
CREATE TEMPORARY TABLE table_name ( column_name1 data_type1, column_name2 data_type2, ... ); |
This section includes the top asked Snowflake SQL interview questions that can assist one to secure a job as an SQL expert. Let's start!
It is built and managed by a program with SQL. Professionals must consider some parameters during this process including schedule, warehouse, code, condition, etc. The program given below is an instance of creating this task. It refreshes dimensional model in every 24 hours -
create or replace task t_dim_station warehouse = compute_wh schedule = 'USING CRON 0 4 * * * UTC' as merge into dim_station t using (select distinct start_station_id station_id, start_station_name station_name, start_station_latitude station_latitude, start_station_longitude station_longitude from raw_trips union select distinct end_station_id station_id, end_station_name station_name, end_station_latitude station_latitude, end_station_longitude station_longitude from raw_trips) on t.station_id = s.station_id when matched then update set t.station_name = s.station_name when not matched then insert (station_id, station_name, station_longitude, station_latitude) values (s.station_id, s.station_name, s.station_longitude, s.station_latitude); |
There are a number of methods to optimize SQL queries on this ELT platform. Listed below are some of their instances -
select * from orders where order_date > current_date - 7 |
You will also need to prepare for the most asked Snowflake interview questions and answers on the trending topics to get a quick job. Here are the top ones:
They enable near-real-time data processing by automatically refreshing query results from streaming sources using Delayed View Semantics.
To enhance PostgreSQL support, improve hybrid workloads, and expand open-source database integration.
Through features like Row Access Policies, Column Masking, Object Tagging, and Access Control to ensure security and compliance.
Snowflake natively supports semi-structured data formats like JSON, Avro, Parquet, ORC, and XML using the VARIANT data type. It can store and query this data directly without a predefined schema, which simplifies the data loading process. You can use standard SQL functions to parse and query the nested data within the VARIANT column.
Snowflake Native App Framework allows developers to build and distribute data applications directly within Snowflake. These applications can run securely inside a customer’s Snowflake account without requiring data movement. It enables companies to build data products, analytics apps, and monetizable solutions on the Snowflake Data Cloud.
Iceberg Tables allow Snowflake to work with Apache Iceberg open table formats stored in external object storage. This enables organizations to use open data lake architectures while still leveraging Snowflake’s compute engine for analytics.
This article has covered frequently asked Snowflake interview questions on different levels of experience and job roles. This guide gives the complete information on what questions will be asked and how to answer them. It will assist you in beginning your preparation for the Snowflake interview.
The difficulty of an interview depends on the preparation and proficiency of the candidate. Preparing with the best Snowflake interview questions is the key to excel in these interviews.
Although SQL is the primary language used in this DWH platform, it can also support several other programming languages, including Python and JavaScript.
Yes. Snowflake runs on AWS, Microsoft Azure, and Google Cloud Platform, enabling organizations to build multi-cloud data architectures.
Snowflake mainly requires strong SQL knowledge and understanding of data warehousing concepts. Basic cloud platform knowledge and data modeling skills are also helpful.
Snowflake mainly offers scalability, high performance, automatic storage management and secure data sharing.