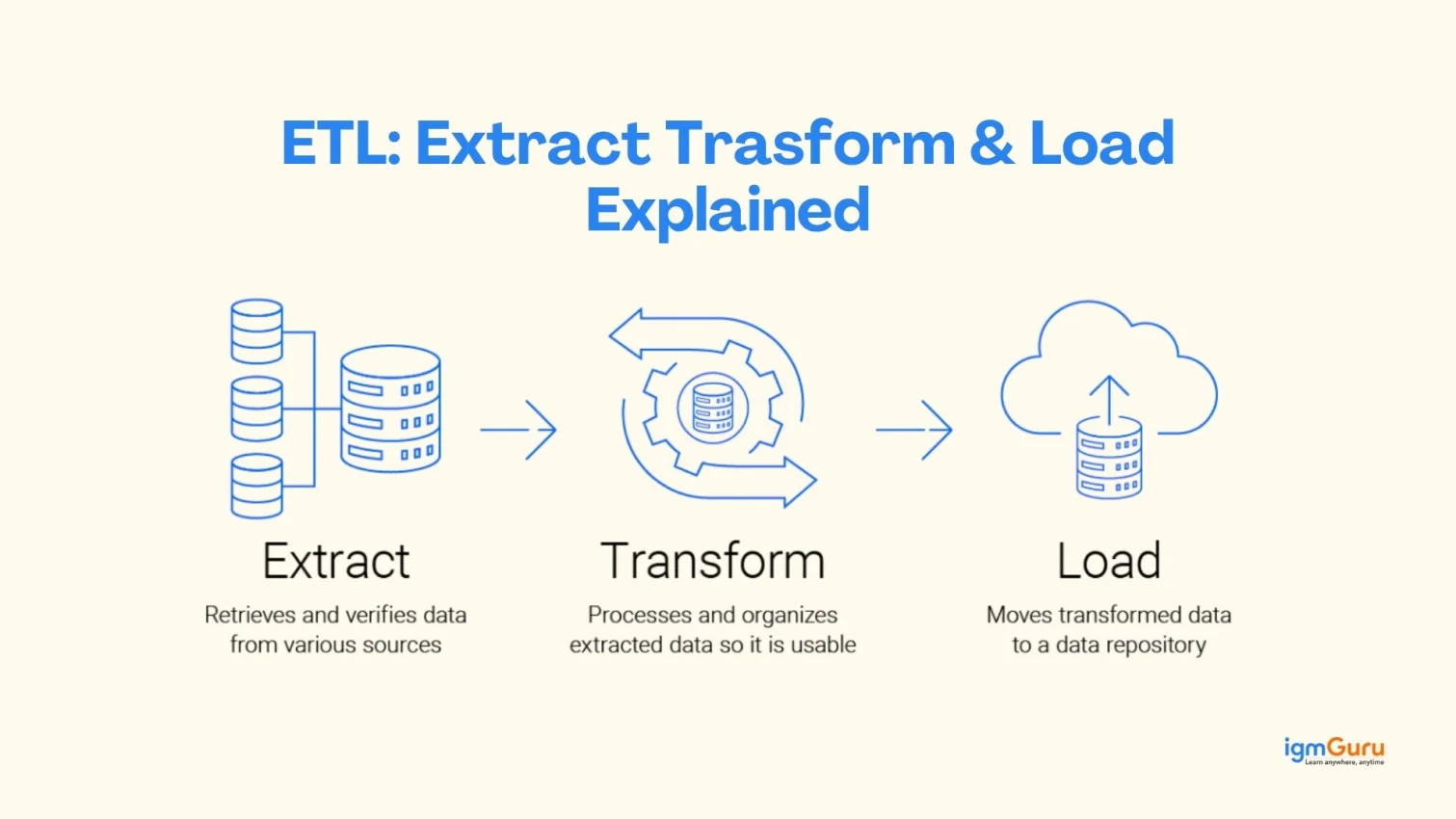
In today’s data-driven world, businesses generate a huge amount of data every second. This data comes from multiple sources like websites, applications, databases and cloud platforms. But raw data alone is not useful. It is often unstructured, inconsistent and difficult to analyze. This is where the ETL process (Extract, Transform, Load) plays an important role.
ETL helps collect data from different sources, clean and organize it and store it in a centralized data warehouse. It turns raw data into meaningful insights. These meaningful insights can be used by businesses for reporting, analytics and decision-making.
In this guide, you will learn what ETL is, ETL process, Data Extraction, Data Transformation, Data Loading, ETL vs ELT and many more. This will help you understand why ETL is important in modern data warehousing and data analytics. Let’s begin.
Learn what is ETL (Extract, Transform, and Load). Learn how this data integration process structures raw data for analytics and reporting for better insights.
ETL refers to the Extract, Transform, Load process. It is used to collect data from multiple sources, process it and store it in a centralized data warehouse.
In simple terms, ETL acts as a bridge between raw data and meaningful insights. Organizations generate data from various systems like databases, applications, websites and cloud platforms. Yet, this data is sometimes scattered, inconsistent and unstructured. ETL helps bring all this data together into one place in a structured and organized format.
The ETL process starts with extracting data from different sources, then transforming it by cleaning, filtering and standardizing it and finally loading it into a data warehouse. This ensures that the data stored is accurate, consistent and ready for analysis. Without ETL, a data warehouse would contain messy and unreliable data. This will make it difficult to generate useful reports or insights.
ETL plays a crucial role in data warehousing because it ensures that the data stored is reliable, organized and ready for analysis. Here are the main reasons why ETL is used:
1. Data Integration from Multiple Sources: Businesses use different tools and platforms. ETL brings data from all these sources into one unified system.
2. Improved Data Quality: ETL removes duplicates, fixes errors and handles missing values, ensuring high-quality data.
3. Consistent Data Format: It standardizes data into a common format and essential for accurate reporting and analysis.
4. Better Business Intelligence: Clean and structured data helps organizations make smarter decisions using analytics tools.
5. Faster Reporting and Analysis: Queries run faster and reports are generated quickly with processed data already stored in a data warehouse.
The evolution of ETL has changed how businesses handle data over time. Earlier, traditional ETL processes were slow and worked mainly with on-premise data warehouses using batch processing. As data grew and cloud technology improved, modern ETL evolved into faster and more scalable solutions. Today, ETL includes cloud-based ETL and even ELT, where data is processed after loading. This evolution has made ETL more flexible, efficient and capable of handling big data, real-time processing and advanced analytics.
The ETL process stands for Extract, Transform, Load. It is used to move data from different sources into a data warehouse. It is a step-by-step process that helps convert raw data into useful information. Businesses use the ETL process to collect data, clean it and store it in a structured format for analysis and reporting. This process ensures that the data is accurate, consistent and ready to use. The ETL process is important for data integration, business intelligence and data analytics.
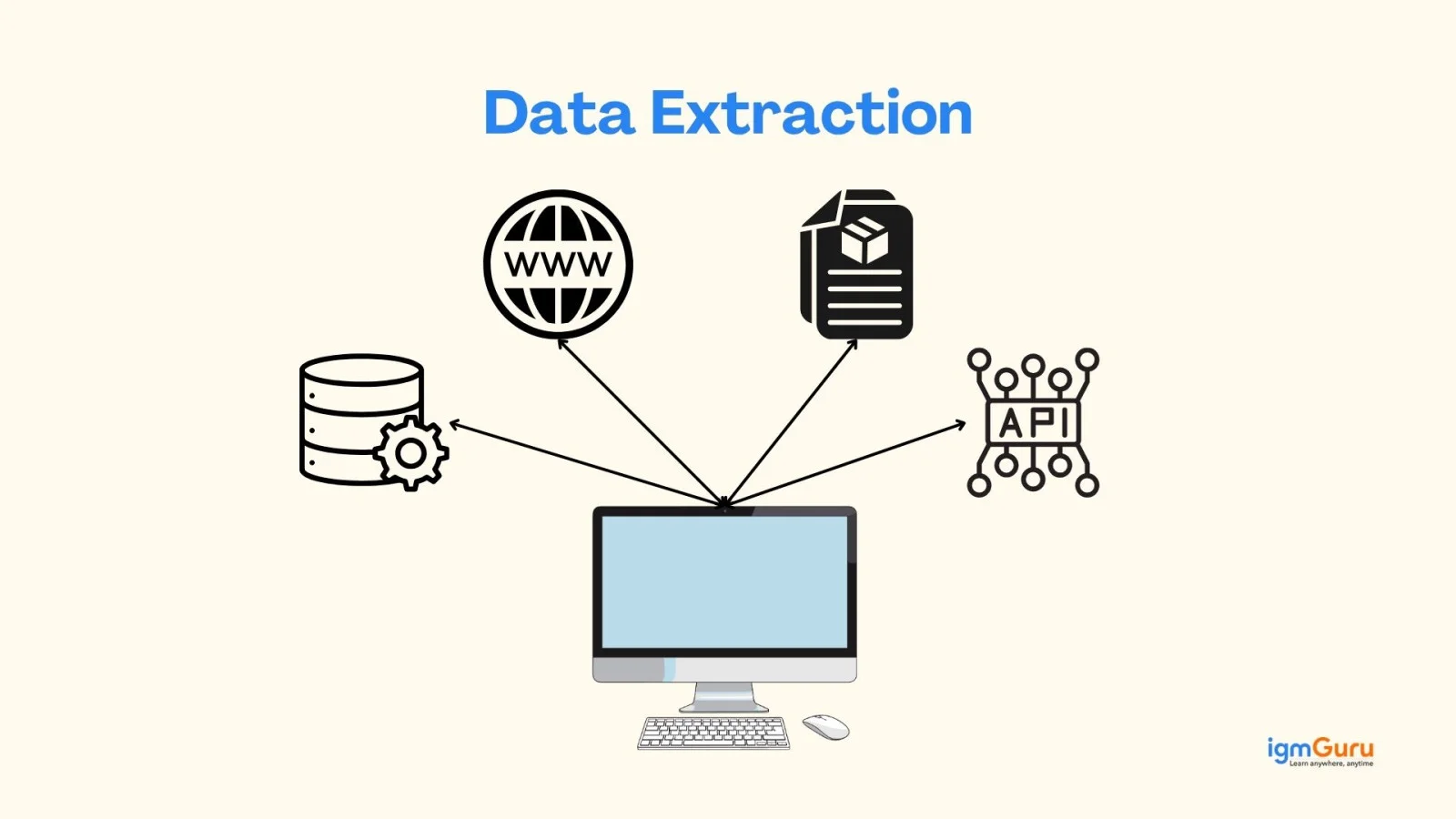
The extract phase in ETL is the first step where data is collected from different sources. These sources can include databases, cloud applications, APIs and files like CSV or Excel. The goal of data extraction is to gather all relevant data without changing it.
During this phase, data can be extracted in batches or in real time. It is important to ensure that the data is complete and up to date. The extract phase is the foundation of the ETL process because all further steps depend on the quality of the extracted data.
The transform phase in ETL is where raw data is cleaned and converted into a usable format. This step is very important because raw data is often messy and inconsistent. Data transformation helps improve data quality and makes it ready for analysis.
Common tasks in this phase include removing duplicate data, fixing errors, handling missing values and standardizing formats. Business rules can also be applied to organize the data. The transform phase ensures that the data is accurate, consistent and useful.
The load phase in ETL is the final step where the transformed data is stored in a data warehouse or another target system. This step makes the data available for reporting, dashboards and analytics.
Data can be loaded in batches or in real time, depending on the system requirements. The load phase ensures that the data is stored properly and can be accessed quickly. Once the data is loaded, businesses can use it to gain insights and make better decisions.

ETL works by moving data through three main steps: extract, transform and load. First, data is collected from different sources like databases, applications or cloud systems. This raw data is often unstructured and stored in different formats. ETL brings all this data together into one pipeline.
Next, the data goes through the transformation stage, where it is cleaned and organized. Errors are fixed, duplicate records are removed and formats are standardized. This step ensures that the data is accurate and consistent. Finally, the processed data is loaded into a data warehouse, where it is ready for reporting and analysis.
In simple terms, ETL works like a system that takes raw data, improves its quality and stores it in a place where businesses can easily use it. This process is essential for data integration, business intelligence and analytics.
A simple real-world ETL example is an e-commerce company. The company collects data from multiple sources such as its website, mobile app, payment gateway and customer database. This is the extract phase, where all raw data is gathered.
In the transform phase, the company cleans the data by removing duplicate orders, correcting errors and converting currencies into a standard format. It may also calculate total sales, customer lifetime value or daily revenue.
In the load phase, the cleaned and processed data is stored in a data warehouse. This allows the company to create dashboards, track sales performance and understand customer behavior. This example shows how the ETL process helps turn raw data into useful insights.
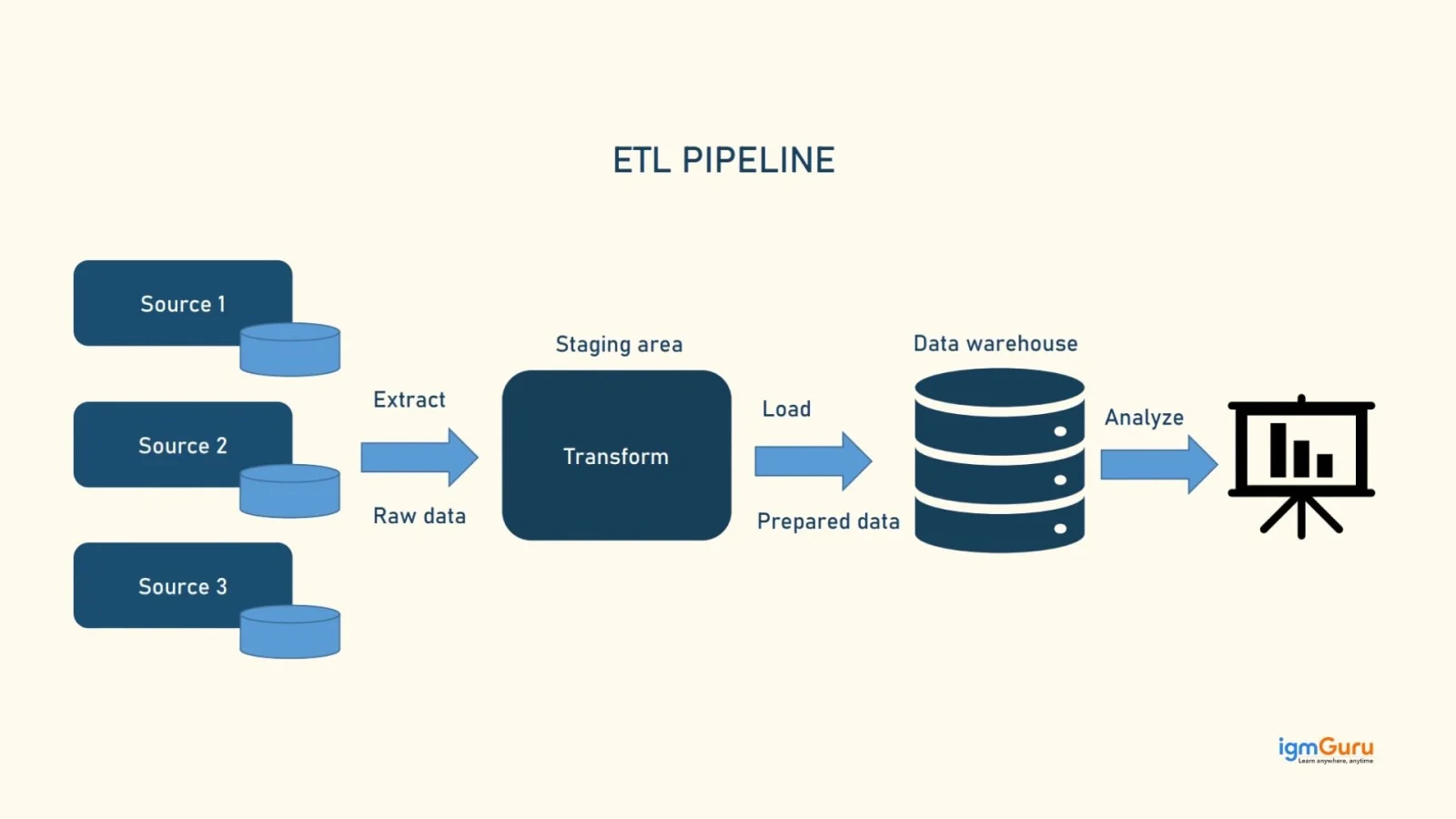
An ETL pipeline is the system that manages the flow of data from source to destination. It connects data sources, transformation tools and the data warehouse into one structured process. The ETL pipeline ensures that data moves smoothly and efficiently through each stage.
A typical ETL pipeline includes data sources, a staging area, transformation logic and a target system like a data warehouse. The staging area is a temporary space where data is prepared before transformation. The pipeline can run in batches or in real time, depending on business needs.
The ETL pipeline architecture helps automate the entire process. It ensures data accuracy, reduces manual work and improves performance. A well-designed ETL pipeline is important for handling large volumes of data and supporting modern data analytics.
There are different types of ETL processes based on how data is collected, processed and loaded into a data warehouse. Each type is used for different business needs and data requirements. The most common types of ETL processes are batch ETL, real-time ETL and cloud-based ETL.
Understanding these types helps businesses choose the right ETL approach for better data integration, faster processing and improved analytics.
Batch ETL processing is the most traditional type of ETL process. In this method, data is collected and processed in large chunks at scheduled times, such as hourly, daily or weekly.
For example, a company may process all sales data at the end of the day instead of processing it instantly. Batch ETL is useful when real-time data is not required. It is simple to manage and works well for large volumes of data.
However, batch ETL may not be suitable for use cases where up-to-date data is needed, as there is always a delay between data generation and data processing.
Real-time ETL processing, also known as streaming ETL, processes data as soon as it is generated. This means data is extracted, transformed and loaded instantly or with very little delay.
This type of ETL is useful for applications that require immediate insights, such as fraud detection, live dashboards and real-time monitoring systems. It helps businesses make faster decisions based on the latest data.
Real-time ETL is more complex than batch processing, but it provides faster and more accurate insights.
Cloud-based ETL is a modern approach where ETL processes are performed using cloud platforms. Instead of using on-premise systems, data is processed and stored in the cloud.
Cloud ETL tools are scalable, flexible and easy to use. They can handle large volumes of data and support both batch and real-time processing. Many businesses prefer cloud-based ETL because it reduces infrastructure costs and improves performance.
This type of ETL is widely used in modern data warehousing and analytics systems, especially with the growth of cloud computing.
There are many ETL tools available that help businesses automate data extraction, transformation and loading. These tools make the ETL process faster, easier and more efficient. Some tools are best for beginners, while others are designed for large enterprises and cloud-based data systems.
Here is a list of the best ETL tools used in data engineering and data warehousing:
It is one of the most popular enterprise ETL tools. It is widely used for large-scale data integration and data warehousing projects.
It is a powerful ETL tool from Microsoft. It is easy to use and works well with SQL Server for data transformation and loading.
It is an open-source ETL tool that is flexible and widely used. It supports cloud, big data and real-time data integration.
It is a strong ETL and data flow automation tool. It is useful for handling real-time data and streaming data pipelines.
It is a cloud-based ETL tool from Amazon. It is serverless and helps automate data preparation for analytics.
It is a fully managed ETL service for stream and batch data processing in the cloud.
It is a cloud-based ETL and data integration service from Microsoft. It is highly scalable and widely used in modern data pipelines.
The ETL process plays a key role in data warehousing and analytics. It helps businesses turn raw data into useful insights by improving data quality and organization. Here are the main benefits of ETL:
ETL cleans and standardizes data before storing it. It removes duplicates, fixes errors and ensures consistency. For instance, if customer names are written differently (Nehal, nehal, NEHAL), ETL standardizes them into one format.
ETL collects data from different systems like databases, APIs, CRM tools, etc. and brings everything into one place.
Since ETL provides clean and structured data, businesses can make more accurate and faster decisions. For instance, managers can easily analyze sales trends and plan strategies.
Manual data cleaning and integration takes a lot of time. ETL automates this entire process. For instance, faster reporting and less human effort.
ETL applies the same rules and transformations across all data, so everything follows a standard format. For instance, dates stored as DD/MM/YYYY across all datasets.
ETL is essential for loading data into data warehouses, where large-scale analysis happens. If ETL is not there, then the Data warehouse would have messy, unorganized data.
Clean and structured data makes it easier to use BI tools (like dashboards, reports, analytics). For instance, Power BI or Tableau dashboards work better with ETL-processed data.
ETL tools are designed to process huge datasets efficiently. It is very useful for big companies that handle millions of records daily.
Sensitive data can be filtered, encrypted, or masked during transformation. For instance, hiding credit card details before storing data.
Since ETL is automated and rule-based, the chances of human error are reduced.
You also have to be informed about the challenges while using ETL Process:
One of the biggest problems in ETL is poor data quality.
ETL pulls data from multiple sources, which makes integration difficult.
As data grows, ETL processes can slow down.
Transforming raw data into useful format is not always easy.
ETL systems need continuous monitoring and updates.
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are both data integration methods used in data warehousing. The main difference between ETL and ELT is the order in which data is transformed and loaded. In ETL, data is transformed before loading into the data warehouse, while in ELT, raw data is loaded first and transformed later.
Both ETL and ELT are widely used in modern data systems. ETL is more common in traditional data warehouses, while ELT is popular in cloud-based data platforms. To clearly understand the difference between ETL and ELT, let’s first understand what ELT is.
ELT stands for Extract, Load, Transform. In this process, data is first extracted from different sources and directly loaded into a data warehouse or data lake. After loading, the data is transformed inside the target system.
ELT takes advantage of modern cloud data warehouses that have high processing power. Instead of transforming data before loading, ELT allows faster data ingestion and performs transformations later when needed. This makes ELT more flexible and scalable for handling large volumes of data.
Now that we understand both ETL and ELT, let’s compare them side by side to see the key differences.
| Feature | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| Process Order | Transform before loading | Load before transforming |
| Data Storage | Only processed data is stored | Raw data is stored first |
| Speed | Slower due to transformation step | Faster data loading |
| Use Case | Traditional data warehouses | Cloud-based data platforms |
| Flexibility | Less flexible | More flexible |
| Scalability | Limited | Highly scalable |
ETL is a key part of modern data warehousing and data integration. It helps businesses collect data from multiple sources, clean and transform it and store it in a structured format for analysis. Data would remain scattered, unorganized and difficult to use without ETL.
From understanding what ETL is to learning about the ETL process, ETL pipeline, types of ETL and ETL vs ELT, it is clear that ETL plays an important role in data analytics and business intelligence. It improves data quality, ensures consistency and helps organizations make better decisions.
As data continues to grow, ETL tools and modern ETL solutions will become even more important. Whether you are working with traditional systems or cloud-based platforms, ETL helps turn raw data into meaningful insights that drive business success.
ETL is a type of data pipeline that specifically focuses on extracting, transforming and loading data into a data warehouse. A data pipeline is a broader concept that includes any process of moving data from one system to another, with or without transformation.
Yes, ETL is still widely used today in data warehousing and data analytics. It is especially important to clean and prepare data before analysis.
ETL tools are software applications that automate the process of extracting, transforming and loading data. They help businesses handle large volumes of data efficiently and build reliable data pipelines.