Anthropic just changed the game with the launch of Claude Fable 5 on June 9, 2026. It's the most capable AI model ever released to the general public, and the first Mythos-class model that anyone can access. If you've been following the AI space closely, you know what that means. Mythos was the model that Anthropic was too cautious to release publicly. Now, with the right safeguards in place, it's here.
In this complete guide, we cover everything: what Claude Fable 5 is, how it differs from Claude Mythos 5, what it can actually do, who it's for, how much it costs, and where you can use it. If you've been waiting for the most thorough breakdown of this launch, this is it.
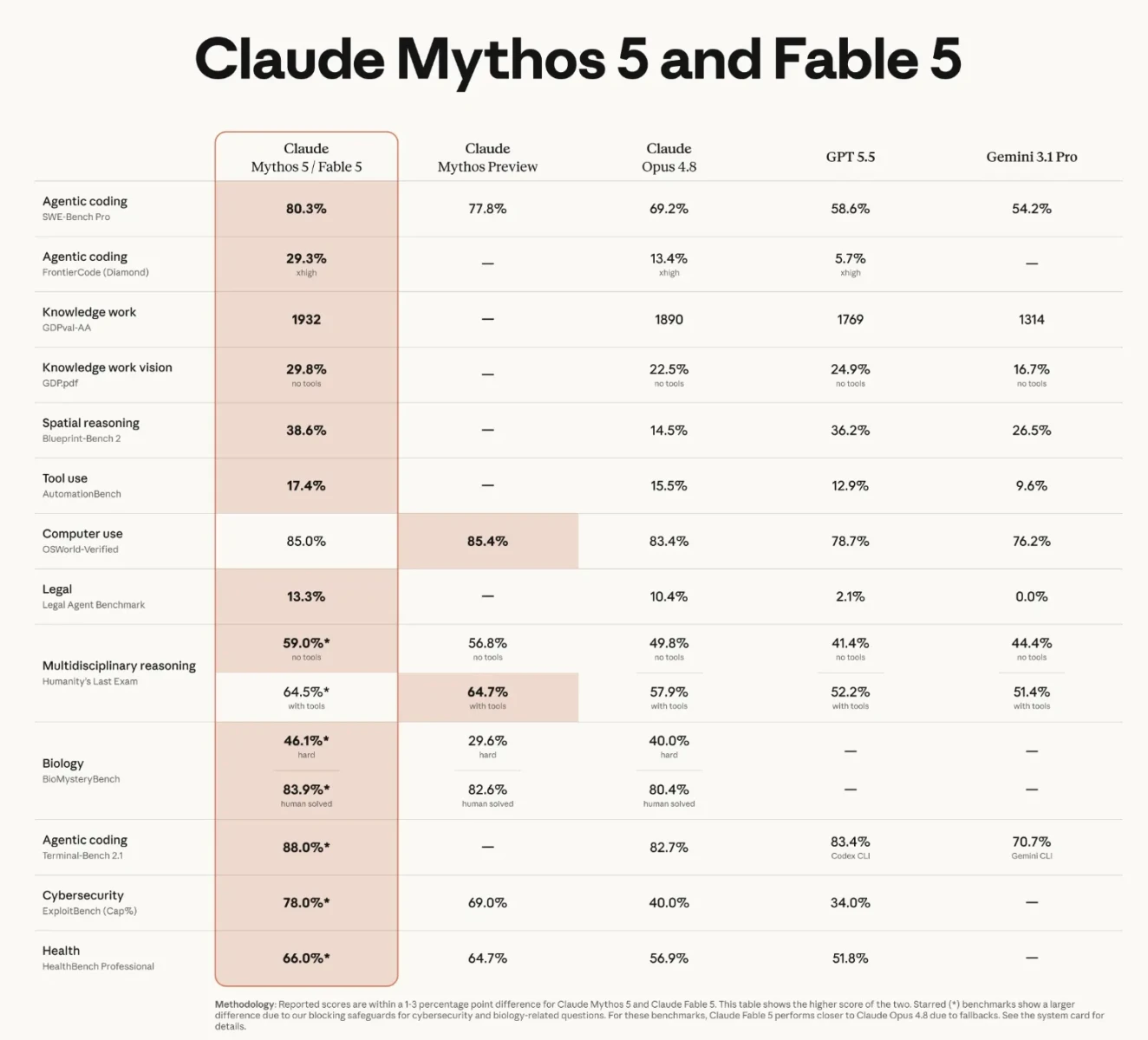
Claude Fable 5 is a Mythos-class AI model built for your most ambitious, long-running work. It sits above the Opus class in Anthropic's model hierarchy and represents the 5th generation of Claude models. It is state-of-the-art across nearly every tested benchmark of AI capability, software engineering, knowledge work, vision, scientific research and more.
The name Fable comes from the Latin fabula, meaning "that which is told,” a deliberate nod to its Greek counterpart, mythos. This naming is, of course, intentional, as Fable 5 and Mythos 5 are two versions of the same underlying model. They are just distinguished by their safeguards. Fable 5 has more restrictions on the cybersecurity domain than Mythos 5.
But don’t worry about the restriction, that is for good reasons. You should consider the best feature of this version. The longer and more complex the task, the larger its lead over every previous Claude model.
As I have just stated, Fable is restricted to some features of Mythos for good reasons. This is also the only difference between the two models. Let me give you a clear distinction between them:
| Feature | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| Underlying model | Same | Same |
| Public availability | Yes, API & Enterprise | No, restricted access |
| Cybersecurity safeguards | Active (conservative) | Lifted in select areas |
| Access via | Claude API, claude.ai, AWS, Azure, Vertex AI | Project Glasswing only |
| Pricing | $10/M input, $50/M output | Same |
| Best for | Developers, enterprises, researchers | Trusted cyberdefense orgs |
Claude Fable 5 is the version available to you right now. It carries the full Mythos-level capability engine, with safety guardrails that intercept high-risk queries (cybersecurity exploits, dangerous biology, etc.) and fall back to Claude Opus 4.8 in those cases. This happens in less than 5% of sessions on average.
Claude Mythos 5 is the same model but with those safeguards lifted in specific areas. It is deployed through Project Glasswing in collaboration with the US government, primarily for trusted cyberdefenders and critical infrastructure operators. It has the strongest cybersecurity capabilities of any AI model in the world right now.
Related Article: Claude Code Cheat Sheet
Here are some of the main capabilities of Fable 5 you need to know before using it in your real-world tasks:
This is where Fable 5 is getting the most attention. During early testing, Stripe reported that Fable 5 compressed months of engineering into days. They tried it on a 50-million-line Ruby codebase, the model performed a full codebase-wide migration in a single day. This work might have taken an entire team over two months to do manually.
It is also the highest-scoring model on Cognition's FrontierCode evaluation, which tests whether models can pass difficult coding tasks while meeting the standards of high-quality production codebases, and it achieves this even at medium effort.
In practice: if you run Fable 5 in an agent harness like Claude Code or Claude Managed Agents, it can work for days at a time, planning across stages, delegating to sub-agents, writing its own tests, and checking its work autonomously.
Fable 5 ranks highest on Hebbia's Finance Benchmark for senior-level analytical reasoning among all tested models. It shows substantial gains in document-based reasoning, chart and table interpretation and complicated problem solving.
IMC noted that it has exceeded their trading-analysis evaluations across factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis. Using it can be a meaningful upgrade for anyone doing heavy research, analysis, or professional-grade document work.
Fable 5 is Anthropic's new state-of-the-art model for vision tasks. It can extract precise numbers from complicated scientific figures. It can also perform tasks like rebuilding a web app's source code from screenshots alone, without additional scaffolding.
A striking demonstration: Earlier, Claude models needed complicated helper harnesses to play Pokémon FireRed. Claude Fable 5 completed the game using only raw game screenshots, without maps, navigation aids, or extra game-state information. Vision only.
Fable 5 stays focused across millions of tokens in long-running tasks and uses its own notes to improve outputs. In tests using the deck-building game Slay the Spire, access to persistent file-based memory improved Fable 5's performance three times more than the same setup did for Opus 4.8. Fable also reached the game's final act three times more often than the previous model.
This is where Mythos 5 becomes genuinely remarkable. Anthropic's internal protein design experts can accelerate aspects of the drug design process by approximately ten times. In one scenario, the model, given protein design and bioinformatics tools but no human assistance, matched or beat skilled human operators across the full scientific workflow: choosing binding sites, selecting and running tools, and recovering from failures independently.
Nine of 14 protein targets yielded strong drug design candidates that are now under active investigation.
Mythos 5 is the first Claude model to consistently produce novel, compelling scientific hypotheses in molecular biology. In blinded comparisons, scientists preferred Mythos's molecular biology hypotheses roughly 80% of the time over Opus-class outputs. One hypothesis about an E. coli protein mechanism was independently corroborated by a separate lab working on the same problem.
Also Explore: Best AI Chatbots
This model is useful for the following entities:
Getting started with Claude Fable 5 on the API takes less than five minutes. Here's exactly how to do it.
|
|
Fable 5 uses adaptive thinking, and the model's reasoning automatically scales to match the complexity of your prompt. Unlike extended thinking (which you toggle manually on Opus 4.8), adaptive thinking on Fable 5 is always on. There is nothing extra to configure.
|
This unlocks Fable 5's full autonomous capabilities like multi-day sessions, self-written test suites, sub-agent delegation, and self-verification. This is where the model's lead over everything else becomes most visible.
One important note for enterprise users: Claude Fable 5 comes with a mandatory 30-day data retention policy. Unlike previous Claude models, where zero-day retention was available, Fable 5 requires Anthropic to retain API inputs and outputs for 30 days for safety monitoring purposes. Factor this into your compliance review before deploying in regulated industries.
Related Article: How to Learn Coding
| Plan | Price |
|---|---|
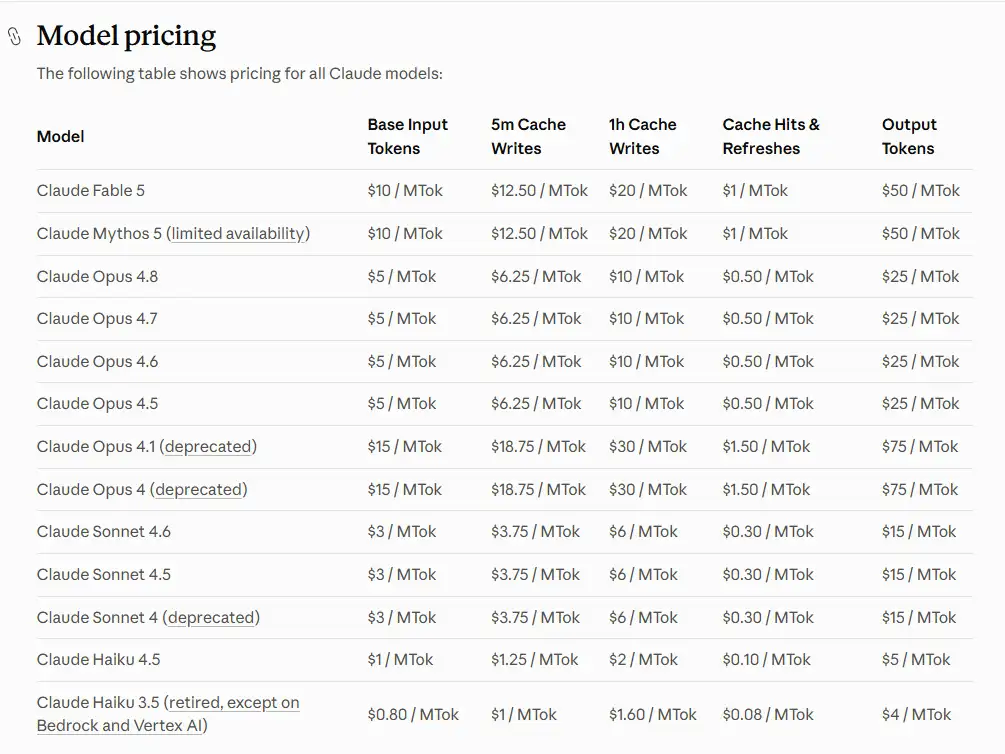
| Input tokens | $10 per million tokens |
| Output tokens | $50 per million tokens |
| Prompt caching discount | 90% off input tokens |
| US-only inference | 1.1x standard pricing |
This is less than half the price of Claude Mythos Preview, making Mythos-class capability accessible to a much broader developer audience.
You can access it from the following tools:
We were discussing the safeguards of Fabke from the very start. Anthorpic has also been very transparent about the risks from the start. Let me explain everything about it. Fable 5 has exceptional cybersecurity capabilities that could be used to identify and exploit software vulnerabilities at scale. It should not go in the wrong hands, as Marvel says Great Powers Come with Great Responsibilities.
Therefore, Anthoric has come to a solution:
Conservative safeguards that intercept queries in high-risk areas (cybersecurity, biology, chemistry, distillation) and fall back to Claude Opus 4.8. Before the public launch, Anthropic ran an external bug bounty that produced no universal jailbreaks in over 1,000 hours of testing, followed by external red-teaming organizations, which also found none.
These safeguards will sometimes catch harmless requests, that's by design. The false positive rate sits at under 5% of sessions on average, and Anthropic has stated it is actively working to reduce this as model generations improve. This is, frankly, one of the more mature safety rollout strategies the industry has seen.
The Claude offers three powerful models now. Therefore, most of indovuals always come across one common question: which one is right for your use case? Here's a direct, no-fluff comparison based on official specs.
| Feature | Claude Fable 5 | Claude Opus 4.8 | Claude Sonnet 4.6 |
|---|---|---|---|
| Model tier | Mythos-class | Opus-class | Sonnet-class |
| Best for | Days-long, complex, autonomous tasks | Complex reasoning & agentic coding | Speed + intelligence balance |
| Context window | 1M tokens | 1M tokens | 1M tokens |
| Max output | 128k tokens | 128k tokens | 128k tokens |
| Adaptive thinking | Yes (always on) | Yes | Yes |
| Extended thinking | No | Yes | No |
| Input price | $10/M tokens | $15/M tokens | $3/M tokens |
| Output price | $50/M tokens | $75/M tokens | $15/M tokens |
| API model ID | claude-fable-5 | claude-opus-4-8 | claude-sonnet-4-6 |
| Availability | API, Claude.ai, AWS, GCP, Azure | API, Claude.ai, AWS, GCP, Azure | API, Claude.ai, AWS, GCP, Azure |
The real rivalry isn't within Anthropic's own lineup. It is between Claude Fable 5 and GPT-5.5. Here's where things stand based on available benchmark data.
| Benchmark | Claude Fable 5 | GPT-5.5 |
|---|---|---|
| SWE-bench Verified | 95.0% | Not published |
| Every Senior Engineer | 91/100 | 62/100 |
| FrontierCode Diamond | 29.3% | Not published |
| Vision tasks | State-of-the-art | Competitive |
| Context window | 1M tokens | 1M tokens |
| Input pricing | $10/M tokens | ~$10/M tokens |
| Output pricing | $50/M tokens | ~$40/M tokens |
| Autonomous agent runs | Days-long natively | Hours-long |
Coding benchmarks aren't even close right now. A 95% SWE-bench Verified score vs GPT-5.5's unpublished numbers, combined with the Every Senior Engineer gap of 91 vs 62, makes Fable 5 the clear choice for serious software engineering work. Fable 5 also handles longer autonomous runs natively, days, not hours.
For general-purpose conversational tasks, creative writing, and workflows deeply embedded in the Microsoft/Azure ecosystem, GPT-5.5 remains a strong option. OpenAI's plugin and integration ecosystem is also more mature for certain business workflows.
Claude Fable 5 is not a minor update. It is a fundamental capability shift, where Anthropic moved its most powerful model class from a restricted research program into the hands of developers, enterprises, and individuals worldwide.
For anyone building serious AI-powered systems, doing complex research, or simply wanting access to the most capable AI assistant currently available to the public, Claude Fable 5 is the model to use right now.
$10 per million input tokens and $50 per million output tokens. Prompt caching comes with a 90% input token discount.
Yes. It is available on Amazon Bedrock and Claude Platform on AWS in multiple global regions, effective June 9, 2026.
As a limited trial, yes. It was included for free plan users until June 22. For ongoing access, a Claude Pro subscription is required.
The Mythos 5 is the complete AI agent that does not have any safety restrictions partially lifted for trusted cyberdefenders and critical infrastructure operators. It is deployed via Project Glasswing, an initiative in collaboration with the US government.
Yes. When used in an agent harness like Claude Code or Claude Managed Agents, Fable 5 can work for days at a time, planning across stages, delegating to sub-agents, writing its own tests, and checking its own outputs.
It is state-of-the-art on nearly all tested benchmarks, with top scores on Cognition's FrontierCode evaluation (coding), Hebbia's Finance Benchmark (knowledge work), and multiple vision benchmarks. Full benchmark comparisons are available on Anthropic's official model card.
The API model ID is claude-fable-5. For the exact versioned string and migration guidance, refer to the official Anthropic API documentation at platform.claude.com.

Claude Fable 5 and Mythos 5: Anthropic's Most Powerful AI Model
June 11th, 2026