'Neural networks' sounds like a familiar term, doesn't it?
Most of us would first think of those interconnected layers in our brain, responsible for processing information. We're not entirely wrong as this article covers something similar, the topic of 'artificial' neural networks which are interestingly inspired by the human brain itself. These are machine learning models that are capable of imitating complicated functions of the brain to perform tasks like learning patterns, making decisions, processing data and much more.
Neural Networks are basically computational models which were inspired by the human brain’s interconnected neuron structure. They are foundational to multiple machine learning algorithms, which lets computers identify patterns and make decisions according to the data. This blog covers a long list of information including ‘what is a neural network?’, functions, use cases, evolution, types, advantages, limitations and examples of neural networks. This guide is designed for both beginner and experienced professionals to provide them with foundational knowledge.
Neural networks are also known as simulated neural networks (SNNs) or artificial neural networks (ANNs). In simple words, it's a kind of machine learning model which provides assistance in making decisions, quite similarly to how a human brain functions. It is capable of recognizing patterns, making conclusions, considering different choices and much more through utilizing methods that imitate how brain cells communicate.
Each neural network is made up of layers and nodes including an input, output and other hidden layers. Every node is linked with other nodes and also has its own weight and threshold. If a node's output goes over its threshold, it gets activated and sends data to the next layer. If not, it just holds back and does not pass anything along. A well-known example of a neural network is Google's search algorithm.
Neural networks require training data to learn, gain accuracy and bring improvements over time. They play a pivotal role in artificial intelligence and computer science once they've achieved the expected accuracy. We can utilize these networks to categorize and group data in no time. For example, things like speech and image recognition can be done in minutes instead of hours compared to doing it by hand.
Both Neural Networks and Traditional Machine Learning can be used for predicting outcomes or analyzing data; however, these two methods differ from each other in their approach to learning, as well as their data handling capabilities and processing techniques. Below, you will find a basic comparison table of both types of methodologies.
| Basis of Comparison | Neural Networks | Traditional Machine Learning |
| Definition | A learning model inspired by the human brain using layers of neurons. | Algorithms that learn patterns from data using predefined rules and features. |
| Data Handling | Works best with large amounts of data. | Can work well with smaller datasets. |
| Feature Extraction | Automatically identifies important features from data. | Requires manual feature selection by humans. |
| Complexity | More complex and computationally intensive. | Simpler and easier to understand. |
| Training Time | Takes longer to train. | Usually faster to train. |
| Accuracy | Often gives higher accuracy for complex tasks. | Performs well for simpler problems. |
| Best Used For | Image recognition, speech processing, and deep learning tasks. | Classification, regression, and structured data analysis. |
| Human Involvement | Less manual intervention needed. | More human guidance is required. |
| Examples | CNN, RNN, Deep Neural Networks | Decision Trees, SVM, Linear Regression As a rule of thumb: If you can solve the problem with a simpler algorithm, do so. Reach for neural networks when the complexity of the data or the task demands it. |
If you can solve the problem with a simpler algorithm, do so. Reach for neural networks when the complexity of the data or the task demands it.
Enroll in igmGuru's Machine Learning training program to become ML experts.
Neural networks have gone through major evolution since they first emerged in the mid-20th century. This section highlights the major occurrences of this journey.
Source- WikiPedia
The neural network architecture is truly inspired by the fascinating human brain. Neurons, the human brain cells which are responsible to process information through sending electrical signals to one another, is behind this smart concept.
The artificial neural network works similarly by teaming up to resolve issues. Artificial neurons are like little software units, known as nodes. When these nodes work together in a setup called artificial neural networks, they form programs or algorithms that use computers to do math calculations.
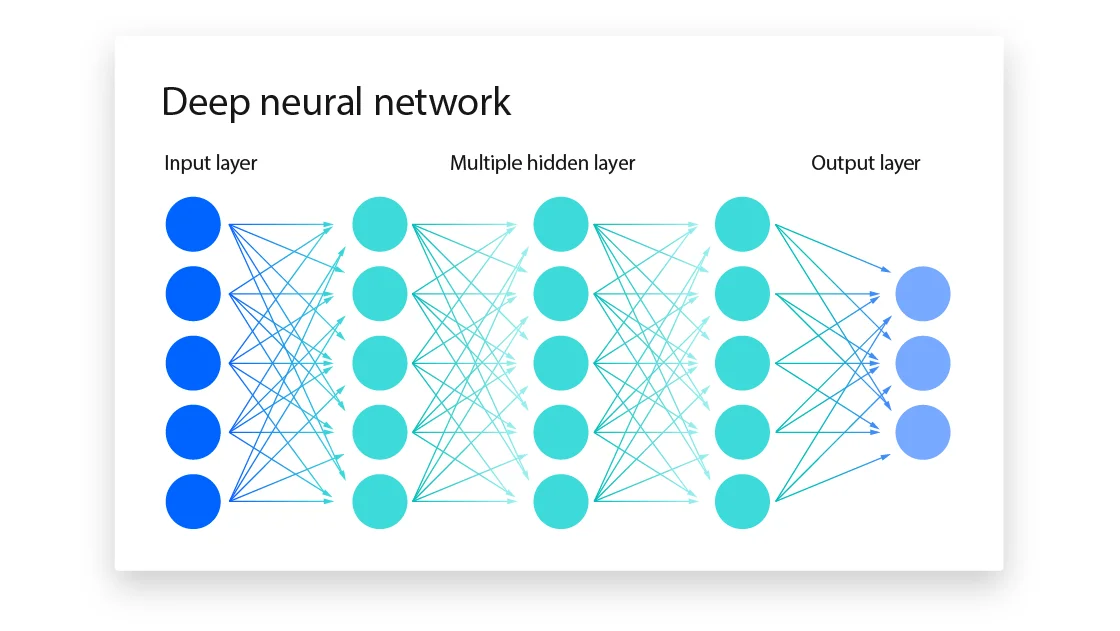
This type of architecture consists of three layers of connected artificial neurons.
Data from the outside world enters the artificial neural network through the input layer. The input nodes are responsible for processing, analyzing and organizing the data before sending it to the next layer.
The output layer is where the artificial neural network wraps up all its processing. It can have one or more nodes, depending on what we're working with. For a yes/no question, there's usually just one output node that tells us if it's 1 or 0. But if we're dealing with multiple categories, then the output layer will have several nodes to represent all the different options.
These layers attain their information from other hidden layers or the input layer. Artificial neural networks consist of several hidden layers. Each one looks at the output from the last layer, processes it, and sends it to the next layer.
Many concealed layers exist in deep neural networks with innumerable artificial neurons that are connected to each other. Each connection between these neurons is assigned a number called weight. The weight is a positive number if one neuron boosts the activity of another. The weight is negative if one node holds back the other.
Pretty much any sort of input or output can be handled by deep neural networks, However, they require intense training as compared to training simple machine learning methods.
To be able to understand how a neural network actually learns, there are two key steps involved:
Forward Propagation occurs first. When the input enters the network, every neuron will calculate a weighted sum of all the inputs and add a bias value to the sum. The equation for this is as follows:
z = (w1 × x1) + (w2 × x2) + … + b [where w is the weight(s), x is the input(s) and b is the bias]. Therefore, the value which is calculated (z) is passed through an activation function (the output of the neuron).
The output will be sent to the next layer of the network until there is an output or prediction is made by the network.
Back Propagation occurs after an output has been made by the network. At this time, the output is compared to the desired (correct) output by the network using a loss function. The amount of error (or loss) indicates how much error the output contained and for how far away the prediction was from the desired or expected output.
Once the network has evaluated the output, it will then work its way through the layers of the network in reverse order to calculate how each weight contributed to the loss in the output.
Finally, the network will adjust every weight in proportion to the calculated contribution to the error by using a method or algorithm called gradient descent.
This process will go on thousands of times until all the weights have been adjusted enough to reflect the desired output from the network.
An activation function determines if a neuron will transmit its signal onwards. If there were no activation functions, then a neural network would be doing only linear calculation instead of learning complex relationships using neural-networks linear combination of weights and inputs. Activation-functions provide the non-linear elements necessary for producing an output from hidden layer neurons, therefore allowing them to operate as part of an intelligent system.
The three most frequently used activation functions include:
This is currently the most widely used activation function and works by returning the input/output from a hidden layer neuron when that number is greater than zero and a value of zero; otherwise it will return 0. This means it's easy to compute. In addition, there is nothing more complicated than simply retrieving the max number from two numbers and applying it. Therefore, the function itself can be expressed mathematically as follows: f(x) = max(0, x)
This function performs well at squeezing any number between 0 and 1; therefore, it is best when applied to binary classifiers (for example, yes/no classification). Mathematically this function is expressed as: f(x) = 1/(1+e(-x))
Unlike the sigmoid function, the tanh (tangent hyperbolic) does not perform well when working within hiddenlayer(s). Therefore, the tanh function for hidden layers outputs numbers between negative one and positive one which will allow for more effective communications amongst hidden neuron layers because tanh has a zero-symmetric midpoint. Mathematically this function can be expressed as: f(x) = (e^x-e(-x))/(e^x+e(-x))
| Activation Function | Output Range | Best Used In |
| ReLU | 0 to ∞ | Hidden layers |
| Sigmoid | 0 to 1 | Binary output layer |
| Tanh | -1 to 1 | Hidden layers |
Training a neural network means that it learns how to make predictions through constant trial and error by comparing its prediction accuracy from each guess and adapting/retuning itself to learn more effectively. As the neural network retrains itself repeatedly, it uses the repeated training to recognize patterns in the data, reduce prediction error rates, and improve the accuracy of future predictions.
This process occurs in three phases:
As data travels from an input layer through one or more hidden layers to the final output layer, it does so by using inputs, multiplying by their respective weights, adding a bias value, and passing through an activation function at each respective neuron along the way to obtain the model’s output prediction.
The model output prediction will then be compared against the actual (correct) answer using some kind of loss function, shown as a number describing the degree of inaccuracy between the two to ensure that future predictions made will continue to decrease over time.
The model will then reverse the input to output path, looking for any weights that contributed to a loss and reducing their values by applying a small value (determined through the process of applying gradient descent) to them to improve any future model output predictions made at each iteration of this training process, until the output is of sufficient accuracy for the particular task.
Neural networks can learn differently depending on whether the task is supervised, unsupervised, or via reinforcement learning.
The neural network is trained on data that has been labeled in a way that the network knows what the correct output is for every input. The neural network will make an initial prediction of the input, compare the predicted output to the actual output, and adjust its weights to improve the accuracy of future predictions; this is the most widely used method for applications like spam detection, image classification, and speech recognition.
The neural network receives unlabeled data and has to find its own patterns and structure within the data. Instead of predicting a specific output for each input, the neural network organizes or encodes the input data into groups (clusters) based on their characteristics. Examples of unsupervised learning algorithms include autoencoders and generative networks (e.g., GANs). Unsupervised learning is commonly used for applications such as anomaly detection, data compression, and generating content.
The neural network learns to make decisions using trials-and-errors by interacting with a specific environment. The neural network receives positive reinforcement for making a correct decision and receives negative reinforcement (or punishment) for making an incorrect decision; as the neural network continued to learn the best way to make decisions (the strategy) it will strive to receive the most positive reinforcement (i.e., total reward). Examples of applications that utilize reinforcement learning include AI game-playing systems (e.g., AlphaGo and chess engines) and robotics.
This section highlights different areas where neural networks are being utilized.
Neural networks can learn and spot patterns right from data without needing any set rules. They're made up of a few important parts.
Learning happens in a clear, three-step process:
1. Input Computation - The network gets data fed into it.
2. Output Generation - Based on what it knows, the network produces an output.
3. Iterative Refinement - The network tweaks its output by adjusting those weights and biases, gradually getting better at different tasks.
In a setting where learning is flexible:
Read Also- Machine Learning Interview Questions and Answers
There are various types of neural networks, each built for different jobs and uses.
A feedforward neural network is one of the simplest types of artificial neural networks. In this setup, data moves in one direction only. It goes into the network through the input layer and comes out through the output layer. Sometimes there are hidden layers in between, but not always. No backtracking happens here; everything is forward-moving.
A convolutional neural network (CNN) shares some features with the feedforward type, particularly with how connections between units have weights that affect each other. What's different is that a CNN has one or more convolutional layers. These layers apply a convolution operation to the input and send the result to the next layer. CNNs are popular for tasks like speech and image processing, especially in computer vision.
A modular neural network consists of several separate neural networks that work on their own to produce an output, without interacting with each other. Each network handles a different task using its own set of inputs. This design makes it easier to break a complicated process into smaller, more manageable parts while still achieving the desired result.
Radial basis functions focus on how far a point is from a center. These networks have two layers. In the first layer, input data is mapped to different radial basis functions in the hidden layer, and then the output layer does the final calculations. Radial basis function networks are often used to model data that shows a trend or a function.
A recurrent neural network (RNN) keeps track of the output from one layer and feeds it back as input to improve predictions. The first layer operates like a feedforward neural network, but RNNs start to differ once the first output is generated. After that, each unit remembers past information, allowing it to function like a memory cell in its calculations.
When creating a neural network, configuration of many different aspects is required before the neural network will begin training. This includes setting the weights of the network, but there are many other parameters that need to be set beforehand to optimize learning of the neural network—these are called hyperparameters. The following are the most important hyperparameters:
The rate at which the optimizer moves in the right direction (in terms of updating weights) is called the learning rate. If the learning rate is too fast, the optimizer will miss the optimal point (overshoot), and if it is too slow, the optimizer will take a very long time to update weights (take a very long time to train the model). Recommended starting value is 0.001.
An epoch is when the neural network has processed all training samples once through all layers. Generally speaking, this means that more epochs will be better in terms of learning. However, too many epochs will contribute to overfitting and not generalizing well.
The number of training examples that are passed through the network will dictate how many times the weights are updated. Recommended values for batch sizes are 32, 64, or 128. Smaller batch sizes will produce noisier updates to the weights, but will produce more frequent updates. Larger batch sizes will result in more stable but longer converging updates.
The number of hidden layers can affect how well the neural network performs. The more hidden layers there are, the more complex of a pattern the neural network will learn. It is easier to train the neural network with fewer hidden layers; thus, it is recommended to start simple, and increase complexity until necessary. Hyperparameter tuning is the art and science of finding the correct combination of hyperparameters to use. This step is often one of the most time-consuming tasks in building a neural network.
Here are some primary advantages of neural networks.
One of the cool things about artificial neural networks (ANNs) is that they can manage tons of data and find patterns that we humans might miss, as well as ones that simple algorithms catch easily.
This makes them perfect for things like recognizing images and speech, understanding natural language, and even keeping machines running well in different industries.
ANNs are handy when it comes to predicting outcomes and making decisions based on data. They can learn to make choices by themselves, which is useful for spotting fraud in banks, assessing risk in insurance, and predicting how customers will behave in retail.
They help automate many processes, making businesses more accurate in what they do.
The neat thing about ANNs is that they can adapt and learn as they get new information. This flexibility is crucial in fast-changing fields like healthcare, where ANNs can be set up to detect disease signs or monitor a patient's health over time for better diagnoses.
ANNs are really effective for real-time tasks since they give fast results. They can process information instantly, which is important for things like self-driving cars and the stock market.
Let's discuss some limitations of neural networks.
ANNs (artificial neural networks) can learn well from large amounts of training data, but getting all that data can take a lot of time and effort.
ANNs can get overly complicated with their structure and the big datasets they're trained on. Sometimes they just memorize the training data, which can hurt their ability to work well with new data.
The way ANNs work can be quite complicated, making it tough to figure out how they come to their decisions. Some people might struggle to understand what they're doing.
ANNs can also get thrown off by small tweaks in the input data. These slight changes can lead to wrong decisions and outputs.
Another downside is that ANNs require powerful hardware, like good processors or special AI chips, along with a lot of storage and memory.
With the continuous advancement and increasing adoption of neural networks, the existence of ethical issues related to their use can no longer go unnoticed. The items below illustrate some of the more serious ethical issues connected with the development and use of neural networks:
Neural networks learn from data. If the data that the neural network is trained on contains historical human bias, the neural network will also learn that same bias. For example, suppose a provider of a hiring tool uses an algorithm that is trained on historical resumes. In that case, the neural network may learn to prefer candidates from specific demographics and disadvantage candidates from others. Similarly, facial recognition systems trained predominantly on lighter-skinned individuals will be less accurate when identifying darker-skinned individuals due to the training data.
The majority of neural networks lack interpretability concerning how they arrive at their decisions; this presents a significant issue in high-stakes applications, such as medical diagnoses, loan approvals, and criminal risk assessments. The field of Explainable AI (XAI) is currently trying to produce tools that will create additional transparency and auditability concerning the decision-making process of neural networks.
Neural networks trained on private data (medical records, browsing history, and voice recordings) create tremendous concerns related to the collection, storage, and use of that data.
The training of large deep learning models requires massive amounts of electricity. As an example, the total CO₂ emissions associated with the training of GPT-3 were expected to be in the hundreds of tons. Researchers are actively pursuing ways to improve energy efficiency.
When constructing your own neural network, you won’t begin with a blank slate — rather, you’ll do this through one of the major existing structures of AI called deep learning frameworks. The following three frameworks are the most popularly used ones shown below:
1. TensorFlow: Created by Google as a framework used for creating production-level models that have undergone extensive testing, are used in large-scale enterprise use cases, and can be deployed/ run on mobile devices, web services, and edge computers.
2. PyTorch: Created by Facebook, PyTorch is widely accepted in research and academia as it’s easy to debug due to its “define-by-run” structure. As such, most new scientific papers created today have been created with PyTorch as the original programming language for those scientists.
3. Keras: Keras is a high-level application programming interface (API) that works within Tensor Flow and uses the least amount of code of any neural network framework to create and integrate a working model.
Here is a minimal working example of a neural network built in Keras that classifies data into two categories:
|
What this code does step by step: it creates a network with one hidden layer of 8 neurons using the ReLU activation function, and an output layer with a single neuron using sigmoid (for binary classification). It compiles with the Adam optimizer and trains for 100 epochs. The final line feeds in new data and gets a probability output — above 0.5 means class 1, below 0.5 means class 0.
Neural networks are really useful in various ways. Here are a few examples:
Read Also- Machine Learning Tutorial- A Complete Guide For Beginners
Let's discuss some neural network applications.
Neural networks and deep learning are closely related technologies in artificial intelligence. While both help machines learn from data, they differ in complexity, structure, learning capability, and the type of tasks they perform.
| Basis | Neural Networks | Deep Learning |
| Definition | A machine learning model inspired by the human brain. | An advanced form of neural networks with many hidden layers. |
| Structure | Usually contains one or few hidden layers. | Contains multiple deep hidden layers. |
| Complexity | Simpler and less computationally intensive. | More complex and requires high computing power. |
| Data Requirement | Works with smaller datasets. | Needs large amounts of data for better accuracy. |
| Training Time | Faster to train. | Takes longer to train due to depth. |
| Performance | Good for basic prediction tasks. | Better for complex tasks like image and speech recognition. |
| Human Involvement | Requires manual feature selection. | Automatically learns features from data. |
| Examples | Spam detection, simple forecasting. | Self-driving cars, virtual assistants, facial recognition. |
The field of neural networks is growing rapidly with new advances. Below are the most prominent areas that will define the future of AI systems.
Models such as GPT-4, Claude and Gemini are examples of neural networks built on the transformer architecture and trained on tens of hundreds of billions of text tokens. They can write, reason, create code and engage in conversation as if they were human beings — these abilities used to be considered science fiction 10 years ago. We are now beginning to see LLM's being integrated into search engines, productivity tools, coding assistance and customer service tools.
The most recent models can take in and process all different types of data (text, image, audio, video) at the same time and through the same system (GPT-4o, Google Gemini). This removes the constraints of AI that's designed and optimized for one type of data only and enables an entirely new market for AI applications that were never possible previously.
The introduction of small, lightweight neural-network architectures enable large, sophisticated, powerful neural networks to be run directly on mobile phones, smartwatches and iOT's, thereby avoiding the need to transmit data to the cloud for processing. This results in greater privacy, reduced latency and the ability to operate offline.
Researchers are developing new types of chips that run like the human brain utilizing the brain's energy-efficient spike-based signaling versus conventional digital computation in order to run neural nets with far less energy than is currently utilized by existing hardware.
Neural networks are increasingly being used to help with important tasks in industries such as healthcare, legal, and financial. Because of this, it is very important for these models to be understandable and provide a description of their own decisions. This is one of the most rapidly advancing research areas currently.
Neural networks have really changed the game in machine learning. They help systems learn from data in ways that are becoming more complex and similar to how we think. You see them everywhere, from recognizing images and speech to understanding language. This article on what is a neural network has already explained everything you need to know. As research moves forward, we can look forward to better and clearer models that will keep pushing the boundaries of AI.
Models like ChatGPT are based on transformer neural networks with billions of parameters — not directly comparable to human brain neurons..
No, machine learning is a subset of AI but not all machine learning can be considered neural networks. Many other techniques exist to cure AI problems.
Building a neural network includes a few important steps: figuring out what problem you want to solve, getting your data ready, setting up the network design, starting with some initial settings, running forward and backward calculations, choosing a cost function, and then training the network.
The main components are the input layer, hidden layers and the output layer. Each layer helps process data and produce results.
Course Schedule
| Course Name | Batch Type | Details |
| AI and ML Certification Courses | Every Weekday | View Details |
| AI and ML Certification Courses | Every Weekend | View Details |