XGBoost (short for eXtreme Gradient Boosting) is an advanced machine-learning technique based on boosting decision trees. It combines multiple weak learners into a single strong model in a way that is efficient for high predictive performance. It has become a go-to tool for many professionals, like analysts and data scientists.
Why does XGBoost matter? In data-rich fields today, getting accurate predictions is often the difference between success and failure. What sets XGBoost apart is its ability to handle large, complex datasets, manage missing or sparse data, avoid overfitting through regularization, and deliver results quickly using parallel processing. In this post, we'll explore what is XGBoost, how it works, why it has become so widely adopted, and how you can use it in your own projects.
XGBoost is a sophisticated machine learning algorithm engineered for speed and high performance. Other models, such as decision trees and random forests, offer high interpretability. They often fall short in accuracy when dealing with complex datasets. XGBoost is a smarter version of gradient boosting that addresses this gap.
It works by sequentially building many weak models, with each new model trained to fix the prediction mistakes of the ones before it. Combining these corrections results in a far more accurate overall model.
Mathematically, XGBoost combines the predictions from multiple decision trees to generate a final prediction. Each tree contributes a small correction that improves the overall model performance.
ŷi = ∑k=1K fk(xi)
XGBoost Ensemble Prediction Formula
In this formula:
This ensemble approach allows XGBoost to gradually reduce prediction errors and improve accuracy with every boosting round.
Furthermore, XGBoost is highly optimized for performance, including parallelization that utilizes multiple CPU cores to accelerate training on large datasets. Its performance can be finely tuned for any task using various hyperparameters such as learning rate, tree depth and regularization.
It constructs decision trees one after another, where each tree aims to fix the errors made by the one before it. The sequence works like this:
At its core, XGBoost minimizes an objective function that balances prediction accuracy and model complexity. The goal is not only to reduce errors but also to prevent the model from becoming overly complex.
Obj = ∑ L(yi, ŷi) + ∑ Ω(fk)
XGBoost Objective Function
Here:
This balance between accuracy and regularization is one of the main reasons why XGBoost performs exceptionally well on structured datasets.
XGBoost rose to prominence because it helped individuals and teams win many Kaggle structured data competitions. In those contests, companies or researchers release datasets, and data scientists compete to build the strongest predictive models.
At first, XGBoost was implemented in Python and R. Due to its success, it now has versions available in Java, Scala, Julia, Perl, and more, broadening its appeal across the developer community.
It's well integrated into popular ecosystems: for example, Python users can use it via scikit-learn, R users via caret, and it works seamlessly with distributed frameworks like Apache Spark and Dask. In 2019, XGBoost was honored as one of InfoWorld's "Technology of the Year" award winners.
Related Article: Python Cheat Sheet
Let me teach you how to use XGBoost through the following steps.
1. Regression: reg:squarederror
2. Binary classification: binary:logistic
3. Multiclass: multi:softprob or multi:softmax
These control how XGBoost builds trees and how it learns. Key ones include:
| Hyperparameter | What it does / Why it matters |
| learning_rate (eta) | How big a step each new tree takes: lower values mean slower learning but often better accuracy. |
| max_depth | How deeply each tree can grow controls model complexity. |
| n_estimators / num_boost_round | Number of trees / boosting rounds. More can overfit if other controls aren't used. |
| Regularization parameters (lambda, alpha) | Help avoid overfitting by penalizing complexity. |
The learning rate controls how much each new tree contributes to the final prediction. Smaller learning rates make the model learn more slowly but often improve generalization.
ŷ(t) = ŷ(t-1) + ηft(x)
Learning Rate Update Formula
In this formula:
A lower learning rate usually requires more trees but can produce more accurate and stable models.
params = { 'objective': 'binary:logistic', 'max_depth': 3, 'eta': 0.1, # other params … } num_round = 100 model = xgb.train(params, dtrain, num_boost_round=num_round, evals=[(dtest, 'eval')], early_stopping_rounds=10) |
With scikit-learn API:
from xgboost import XGBClassifier model = XGBClassifier(use_label_encoder=False, eval_metric='logloss', max_depth=3, learning_rate=0.1, n_estimators=100) model.fit(X_train, y_train, early_stopping_rounds=10, eval_set=[(X_test, y_test)]) |
Here are the features of XGBoost:
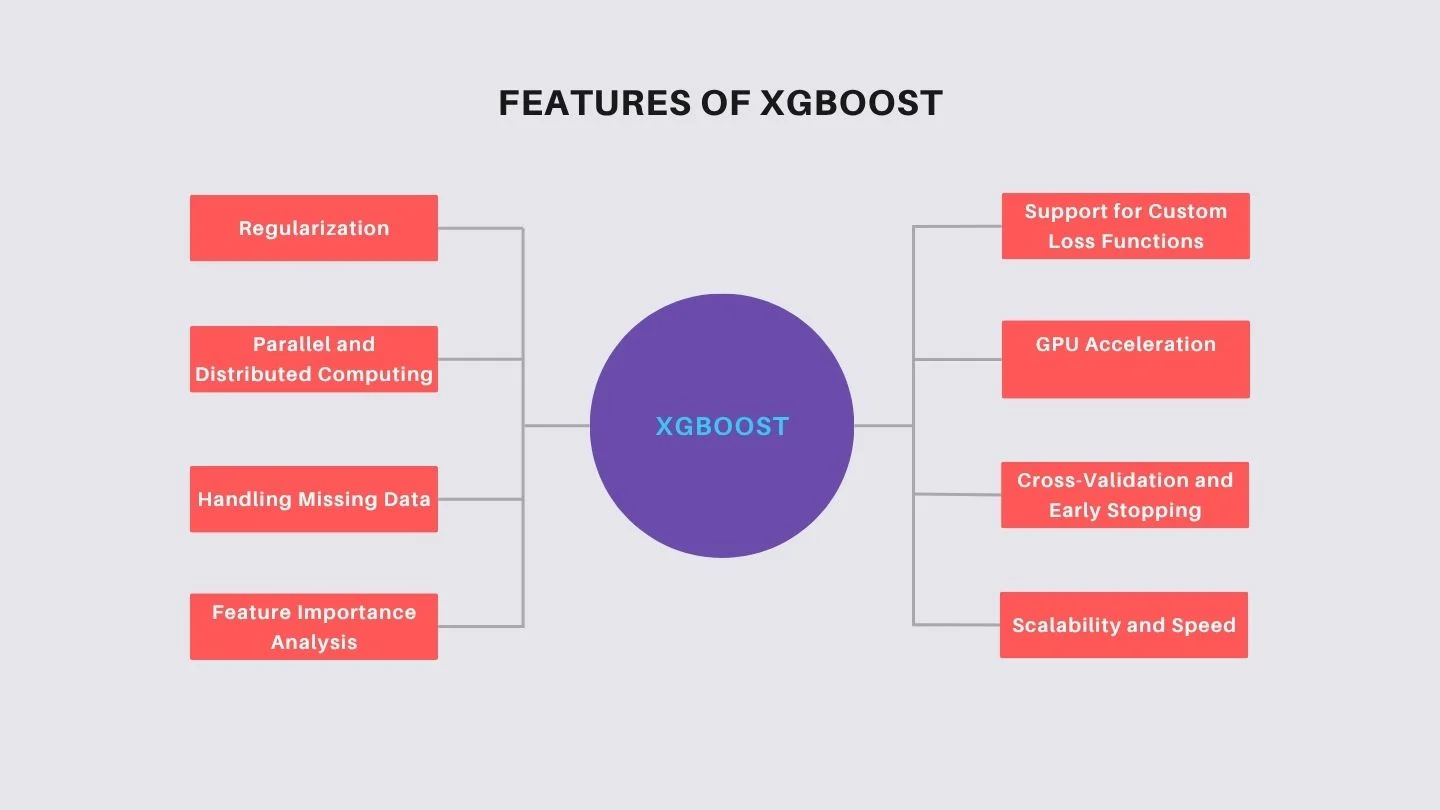
XGBoost incorporates both L1 (Lasso) and L2 (Ridge) regularization techniques into its objective function. This helps control model complexity and prevent overfitting, leading to better generalization on unseen data.
XGBoost uses regularization techniques to reduce overfitting and improve model generalization. It penalizes overly complex trees by adding a regularization term to the objective function.
Ω(f) = γT + ½λ||w||²
XGBoost Regularization Formula
In this equation:
This regularization mechanism helps XGBoost avoid overfitting while maintaining strong predictive performance.
The library stores data in in-memory units called blocks, allowing for parallel processing across multiple CPU cores. It also supports distributed training across clusters using frameworks like Apache Spark, Dask, and Kubernetes, enabling efficient scaling for large datasets.
XGBoost can automatically learn the best direction to assign missing values during training, effectively handling sparse or incomplete datasets without the need for manual imputation.
The algorithm provides built-in tools to assess feature importance, helping users understand which variables contribute most to the model's predictions. This is valuable for feature selection and model interpretation.
XGBoost allows users to define custom objective functions and evaluation metrics, offering flexibility to tailor the model to specific problem requirements.
The library supports GPU-accelerated training, significantly reducing computation time for large datasets and complex models. This is achieved through optimized algorithms that leverage the parallel processing capabilities of GPUs. Recent XGBoost releases have further improved GPU memory efficiency and training speed, making GPU acceleration more practical for large-scale datasets and production machine learning workflows.
XGBoost includes built-in support for k-fold cross-validation and early stopping, aiding in model selection and preventing overfitting by halting training when performance on a validation set ceases to improve.
Designed for efficiency, XGBoost can handle large datasets with millions of records. Its optimized algorithms and parallel processing capabilities ensure fast training times without compromising accuracy.
Let's go through some real-world applications and use cases of XGBoost:
Here are some steps to learn how to deploy and scale XGBoost in production, along with some best practice suggestions.
Begin by saving your trained XGBoost model in a format suitable for deployment. The save_model() function allows you to export the model to a file, which can then be loaded into your production environment. Alternatively, you can use Python's pickle module to serialize the model object.
To make your model accessible for real-time predictions, deploy it using a serving framework. For instance, Ray Serve provides a scalable and flexible solution for serving machine learning models, including XGBoost. It allows you to handle high-throughput inference requests efficiently.
Alternatively, Flask can be used to create a lightweight API for serving your model. While Flask is suitable for smaller-scale applications, it may require additional tools like Gunicorn for handling concurrent requests in production.
Package your model and its dependencies into a Docker container to ensure consistency across different environments. This approach simplifies deployment and scaling, as containers can be orchestrated using tools like Kubernetes.
For large datasets, consider using distributed training frameworks to scale your model. Dask integrates well with XGBoost, enabling parallel processing across multiple nodes. This setup is particularly beneficial when performing hyperparameter optimization.
Cloud services like AWS SageMaker offer managed environments for training and deploying XGBoost models. SageMaker provides built-in support for XGBoost, simplifying the deployment process. Additionally, SageMaker Neo can optimize your model for faster inference on edge devices. AWS SageMaker, Azure Machine Learning, and Google Vertex AI all provide managed environments for training and deploying XGBoost models, making it easier to build scalable production pipelines.
To enhance inference speed, consider optimizing your model using tools like SageMaker Neo or TensorRT. These tools can compile your model to run more efficiently on specific hardware, reducing latency and improving throughput.
Understand what differs XBoost from other existing boosting algorithms through the given table.
| Algorithm | Key Strengths | Handling of Categorical Data | Tree Growth Strategy | Speed |
| XGBoost | High accuracy, scalability, support for missing values | Requires preprocessing (e.g., one-hot encoding) | Level-wise (depth-first) | Moderate |
| LightGBM | Extremely fast, efficient for large datasets | Native support for categorical features | Leaf-wise (best-first) | Very Fast |
| CatBoost | Excellent for categorical data, minimal preprocessing | Native support for categorical features | Symmetrical tree structure | Moderate |
| AdaBoost | Simple, interpretable, effective for weak learners | Not inherently designed for categorical data | Sequential (adjusts weights of misclassified instances) | Moderate |
In this journey through XGBoost, we've uncovered how this powerhouse algorithm blends speed, accuracy, and scalability to tackle complex data challenges. Whether you're a data enthusiast or a seasoned practitioner, XGBoost offers a toolkit that can elevate your machine learning projects.
XGBoost uses a second-order Taylor expansion of the loss function to approximate both gradients and Hessians (first and second derivatives). This lets it optimize with respect to both slope and curvature, giving more precise updates in each boosting round.
XGBoost has a sparsity-aware split algorithm: for missing feature values, it learns a "default direction" (left or right) during split finding to minimize loss. So missing entries are handled internally.
Gradient Boosting builds trees level-wise and doesn't include built-in regularization, whereas XGBoost offers advanced regularization techniques (L1 & L2) and supports parallel processing.
Yes. Although XGBoost cannot replace large language models, it is often used alongside them. For example, embeddings generated by LLMs can be used as input features for XGBoost in classification, ranking, fraud detection, recommendation systems, and structured prediction tasks.