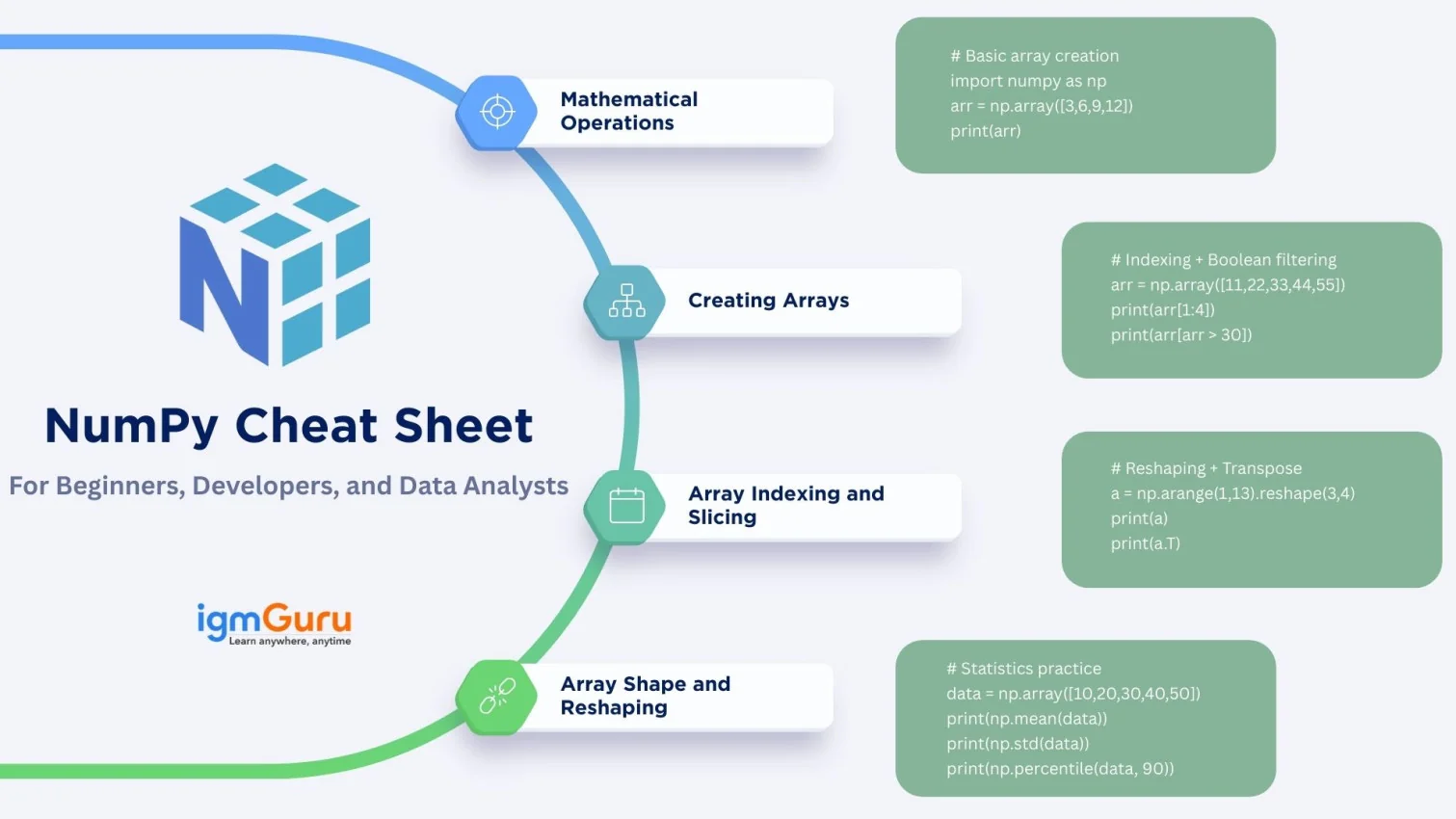
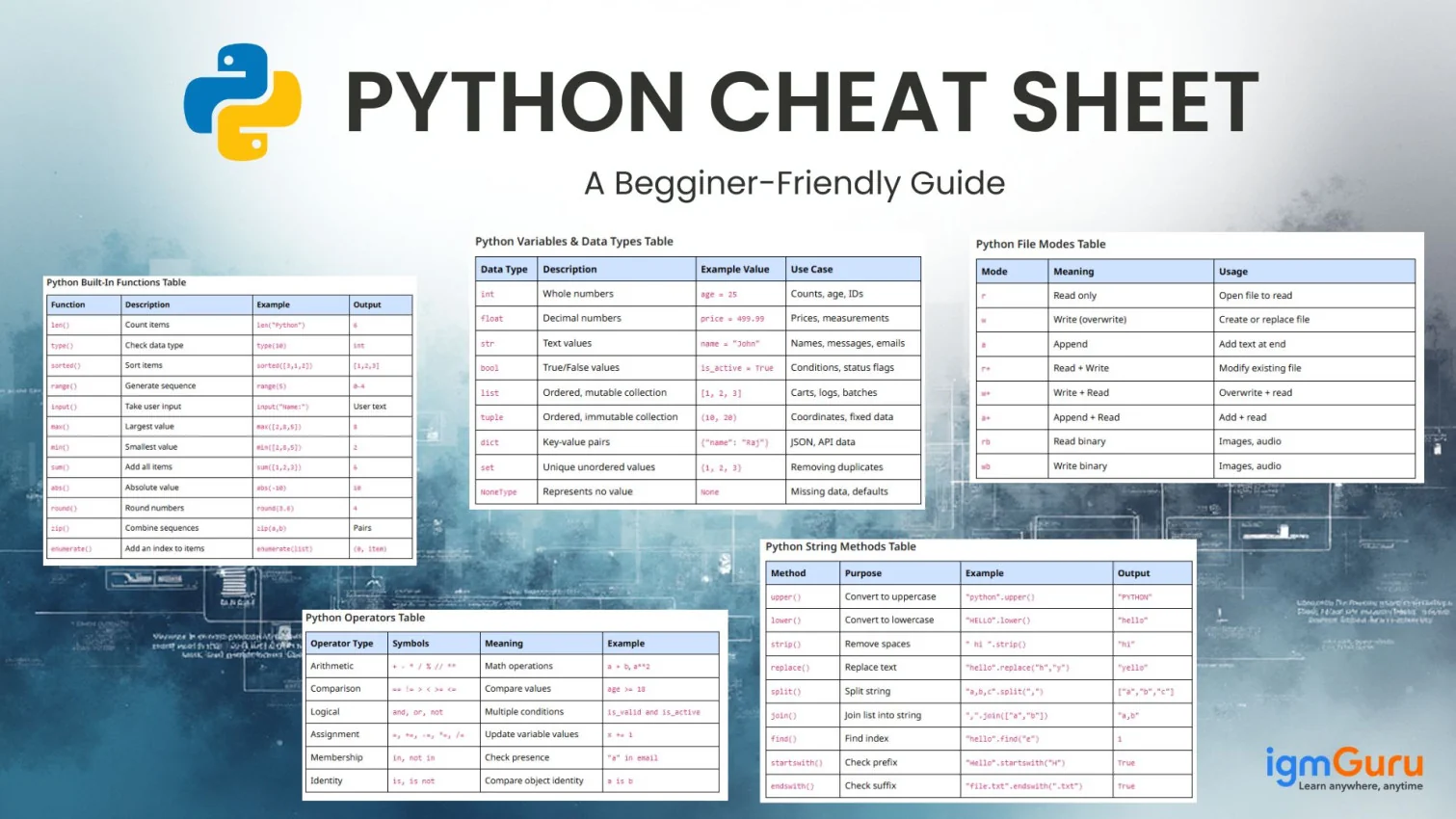
NumPy is a Python library built for fast mathematical computing, large dataset handling and scientific analysis. It works with multi-dimensional arrays that execute considerably faster than standard Python lists due to optimized memory allocation and vectorized operations. This Numpy cheat sheet provides a complete reference to array creation, indexing, reshaping, broadcasting, mathematical functions, statistics, random generation and linear algebra methods used in data science and machine learning.
Who is this NumPy Cheat Sheet For?
This NumPy cheat sheet is created for absolute beginners, students, and professionals who want a fast, simplified reference for array manipulation, mathematical operations, and data analysis workflows in Python. It is useful for learners preparing for interviews, developers working in machine learning domains, and analysts handling large datasets. Anyone who needs quick access to syntax, functions, and commands without searching long documentation pages will find this cheat sheet valuable. It reduces learning time, improves retention, and supports hands-on practice while coding real projects and experiments.
1. NumPy Basics
NumPy is a numerical computation library written in C and integrated with Python for high-speed processing. The core of NumPy is the ndarray, which stores large arrays in continuous memory blocks for faster execution and improved efficiency in mathematical operations. Unlike Python lists, NumPy arrays use fixed data types, allowing the CPU to optimize operation speed. NumPy is foundational for machine learning, data processing, statistical modeling and algorithm implementation, making it a required skill for data analysts and AI developers. Learning the basics is important because every advanced feature in data science stacks depends on NumPy.
import numpy as np
arr = np.array([1, 2, 3])
print(arr)
|
| Concept | Description |
|---|
| ndarray | Main array container in NumPy |
| Vectorized Operations | Perform operations without loops |
| Faster Execution | Runs faster than standard lists |
2. Creating Arrays
Array creation is the first step in data processing with NumPy, allowing developers to generate structured numerical datasets efficiently. Arrays can be initialized using Python lists, zeros, ones, random distributions or identity matrices. NumPy also supports sequence generation with arange and linspace, which help in mathematical modeling and simulation work. Array creation is important in machine learning input preparation, statistical sampling, and tensor building for neural networks. Understanding creation techniques improves workflow speed, reduces redundant code and forms the foundation for every transformation that happens later.
np.array([1, 2, 3])
np.zeros((2, 2))
np.ones(5)
np.arange(0, 10, 2)
np.linspace(1, 5, 5)
np.eye(3)
|
| Function | Output |
|---|
| np.zeros(3) | [0 0 0] |
| np.ones(3) | [1 1 1] |
| np.arange(5) | [0 1 2 3 4] |
| np.linspace(1,10,5) | Even spaced values |
| np.eye(3) | Identity matrix |
3. Array Indexing and Slicing
Indexing and slicing help extract elements, rows and columns from NumPy arrays without requiring iteration loops. These operations are efficient for data filtering, selection and transformation. NumPy supports slice ranges, step slicing, negative indexing, boolean masks and fancy indexing. Boolean filtering helps retrieve values based on conditional logic, and advanced slicing aids reshaping before model training. Efficient indexing improves speed, reduces memory overhead and simplifies complex numerical workflows. It is also essential in array cleaning, sampling and segmentation of large datasets.
arr = np.array([10, 20, 30, 40, 50])
arr[0]
arr[1:4]
arr[arr > 25]
|
| Type | Example |
|---|
| Basic Index | arr[2] |
| Slice | arr[1:4] |
| Boolean Mask | arr[arr > 25] |
| Fancy Index | arr[[0, 3]] |
4. Data Types (dtype)
NumPy uses specific data types for storing values inside arrays, which results in faster execution and lower memory usage compared to standard Python structures. dtype determines the precision and storage format of values including integer, float, boolean and complex types. Selecting the right dtype helps ensure compatibility with machine learning models, maintains numerical stability and controls rounding behaviour in scientific computing. Understanding dtype is useful while loading datasets, converting formats, optimizing memory usage and ensuring models compute values accurately. Many runtime errors occur due to dtype mismatch, making dtype awareness important in numerical workflows.
arr.dtype
np.int32
np.float64
np.bool_
np.complex_
|
| dtype | Description |
|---|
| int32 / int64 | Integer numbers |
| float32 / float64 | Decimal values |
| bool_ | True or False |
| complex128 | Complex numbers |
5. Array Shape and Reshaping
Array shape defines the row and column structure of NumPy arrays, while reshaping allows conversion between dimensional formats without changing total elements. Reshaping is important for feeding data into machine learning models, preparing batches, vectorizing text and aligning image tensors. NumPy supports flatten, ravel, transpose, squeeze and expand dimension methods for flexible shape manipulation. Incorrect reshape attempts result in size mismatch errors, so dimension awareness is necessary. Mastering shape operations makes data pipelines more organized and supports efficient mathematical modeling.
a = np.arange(12).reshape(3, 4)
a.flatten()
a.T
np.expand_dims(a, axis=0)
np.squeeze()
|
| Method | Usage |
|---|
| reshape() | Change array dimension |
| flatten() | Convert to one-dimensional |
| ravel() | Flatten view of array |
| T | Transpose matrix |
| squeeze() | Remove single dimensions |
6. Mathematical Operations
NumPy enables fast element-wise mathematical operations using vectorization instead of loops. It supports addition, subtraction, multiplication, exponentiation and absolute value computations. NumPy also includes logarithmic, exponential, square root and trigonometric transformations. These methods are important for preprocessing machine learning inputs, signal transformation, scaling and statistical analysis. Vectorization enhances speed and workflow efficiency, especially when operating over large datasets that require repeated numeric transformations. Mathematical operations form the core of data science computation and model training.
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
a + b
a * b
a ** 2
np.sqrt(a)
np.log(a)
np.exp(a)
|
| Operation | Example |
|---|
| Addition | a + b |
| Multiplication | a * b |
| Exponent | a ** 2 |
| Square Root | np.sqrt(a) |
| Logarithm | np.log(a) |
7. Statistical Functions
NumPy provides statistical functions to calculate mean, median, standard deviation, variance, minimum and maximum values. These functions are used in data analysis, pattern detection, distribution understanding and exploratory data analysis before model training. Statistical measures reveal skewness, scaling issues, outliers and normalization requirements. NumPy performs aggregations quickly due to optimized backend execution. Statistics are fundamental for machine learning, predictive analytics and evaluation tasks, making this section essential for anyone working with numerical datasets.
np.mean(a)
np.median(a)
np.std(a)
np.var(a)
np.percentile(a, 75)
|
| Metric | Function |
|---|
| Mean | np.mean() |
| Standard Deviation | np.std() |
| Variance | np.var() |
| Percentile | np.percentile() |
8. Broadcasting
Broadcasting performs operations on multiple arrays with different shapes by automatically expanding dimension sizes where required. It allows scalar addition to arrays, row and column level arithmetic, normalization operations, image transformation and neural network computations without manually replicating values. Broadcasting helps reduce code complexity, improves execution time and conserves memory. Understanding valid shape combinations prevents shape mismatch errors, which are common when operating on multidimensional arrays. Broadcasting makes model development more efficient and readable.
a = np.array([1, 2, 3])
a + 2
|
| Compatibility | Example |
|---|
| Compatible | (3,) + scalar |
| Compatible | (3, 1) + (3, 3) |
| Not Compatible | (3,) + (2,) shape mismatch |
9. NumPy Random
The NumPy random module generates random numbers for simulations, machine learning weight initialization, sampling and probability modeling. The module supports random integers, random floats, uniform distribution, Gaussian distribution, seeding for reproducibility and array shuffling. Random number generation is essential for experimental studies, dataset splitting, Monte Carlo simulations and stochastic model evaluation. Controlled randomness allows fair comparisons between models and prevents training bias during model optimization runs.
np.random.rand(3, 3)
np.random.randint(1, 10, 5)
np.random.seed(42)
np.random.normal(0, 1, 1000)
|
| Function | Use |
|---|
| rand() | Random floats |
| randint() | Random integers |
| seed() | Control randomness |
| normal() | Gaussian distribution |
10. Linear Algebra
NumPy features a powerful linear algebra engine supporting dot product, matrix multiplication, determinants, matrix inversion and eigen decomposition. These operations are heavily used in deep learning, computer vision, recommendation systems and regression models. Linear algebra allows conversion of large numerical tasks into optimized matrix-based solutions. Understanding these functions is necessary for building and training machine learning models, handling tensors, time series analysis and multi-variable mathematical simulations. Efficient linear algebra computation is one of NumPy’s strongest capabilities.
np.dot(a, b)
np.matmul(A, B)
np.linalg.inv(A)
np.linalg.det(A)
np.linalg.eig(A)
|
| Operation | Function |
|---|
| Dot Product | np.dot() |
| Matrix Multiplication | np.matmul() |
| Matrix Inverse | np.linalg.inv() |
| Eigenvalues | np.linalg.eig() |
Code Snippets You Can Practice
This section provides short, easy practice snippets that help beginners strengthen NumPy fundamentals through hands-on execution. These code blocks cover array creation, slicing, reshaping, mathematical operations, random generation, statistics, and broadcasting. Practicing them repeatedly builds muscle memory, making NumPy usage natural in real coding environments. Run them in Jupyter Notebook, VSCode, Google Colab, or any Python editor for quick learning. You can modify values, experiment with shapes, apply functions, and verify outputs instantly, which makes learning NumPy faster and more effective for real-world applications.
I. Basic Array Creation
# Basic array creation
import numpy as np
arr = np.array([3,6,9,12])
print(arr)
|
II. Indexing and Boolean Filtering
# Indexing + Boolean filtering
arr = np.array([11,22,33,44,55])
print(arr[1:4])
print(arr[arr > 30])
|
III. Reshaping and Transpose
# Reshaping + Transpose
a = np.arange(1,13).reshape(3,4)
print(a)
print(a.T)
|
IV. Statistics Practice
# Statistics practice
data = np.array([10,20,30,40,50])
print(np.mean(data))
print(np.std(data))
print(np.percentile(data, 90))
|
V. Random Number Generation
# Random number generation practice
np.random.seed(10)
print(np.random.randint(1,100,10))
print(np.random.rand(3,3))
|
Unlock Your Future in Data Science
Boost your career with in-demand data skills.
Explore Now
Conclusion
NumPy is one of the most important tools in the Python data ecosystem. It supports fast array operations, numerical computing, statistics, mathematical modeling and deep learning tensor transformations. This cheat sheet gives a complete reference to array creation, slicing, broadcasting, random number generation and linear algebra. Regular practice will improve your skill and build confidence in handling large datasets and analytical workflows.
FAQs
1. Is NumPy necessary for data science?
Yes. NumPy is used for numerical computation and array handling in machine learning, forecasting models, neural networks and data analysis pipelines.
2. Is NumPy faster than Python lists?
NumPy arrays run faster because they use fixed data types and continuous memory storage. This leads to vectorized executions instead of slow Python loops.
3. Can beginners learn NumPy easily?
Yes. NumPy is beginner-friendly and easy to understand. With consistent practice, handling arrays, mathematical functions and numpy-based data processing becomes simple.
Articles You Can Also Read:
Course Schedule