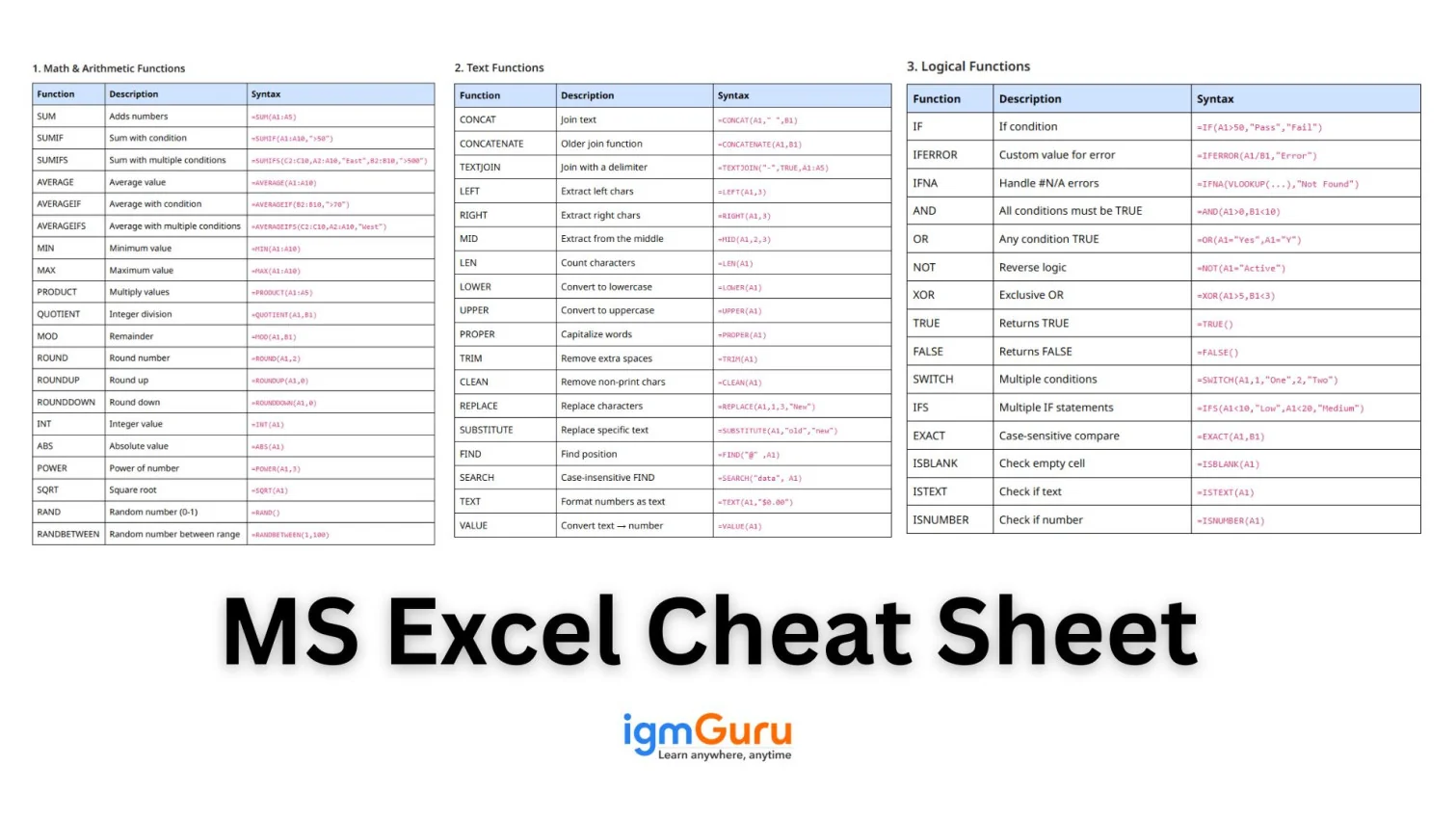
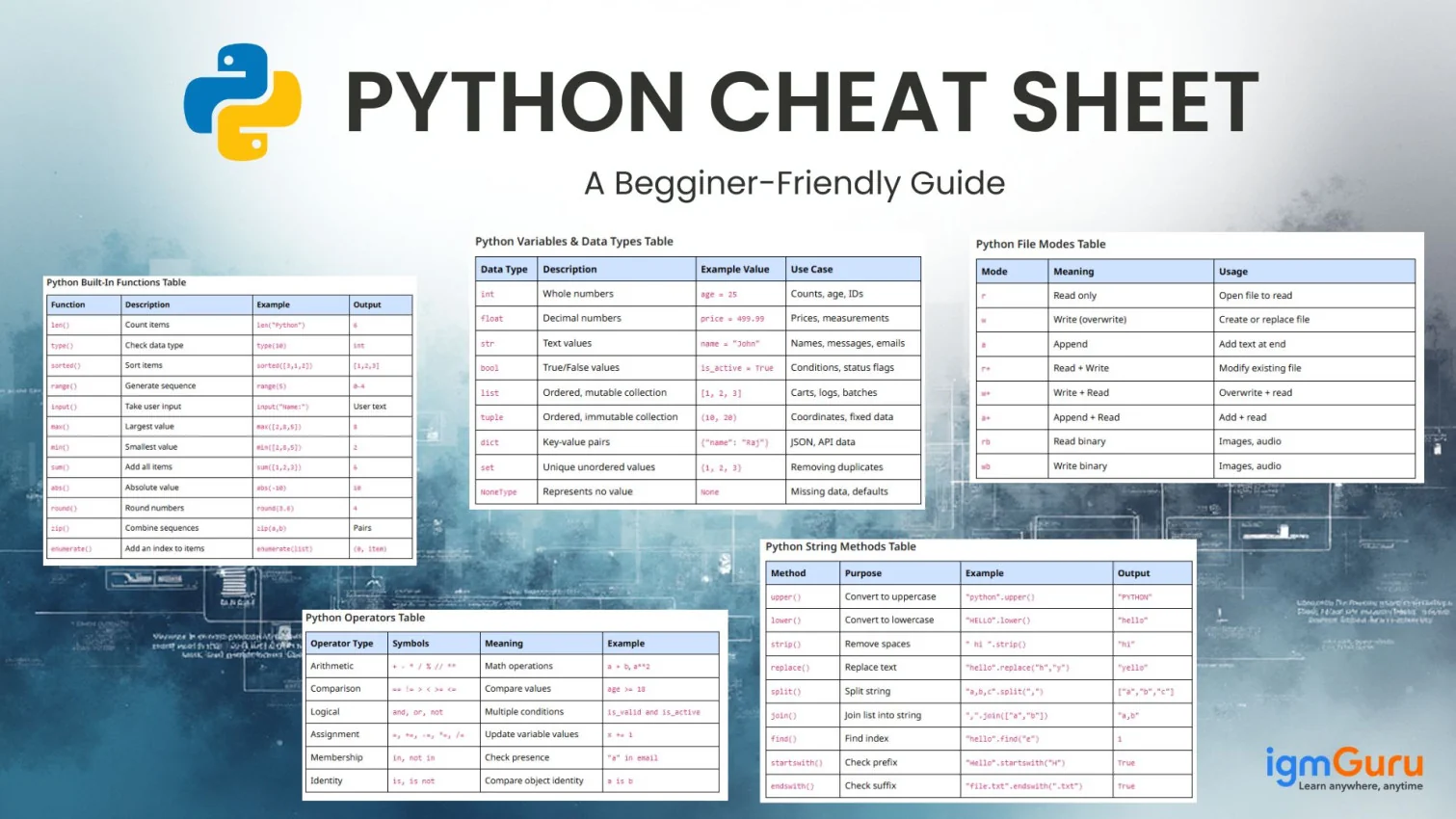
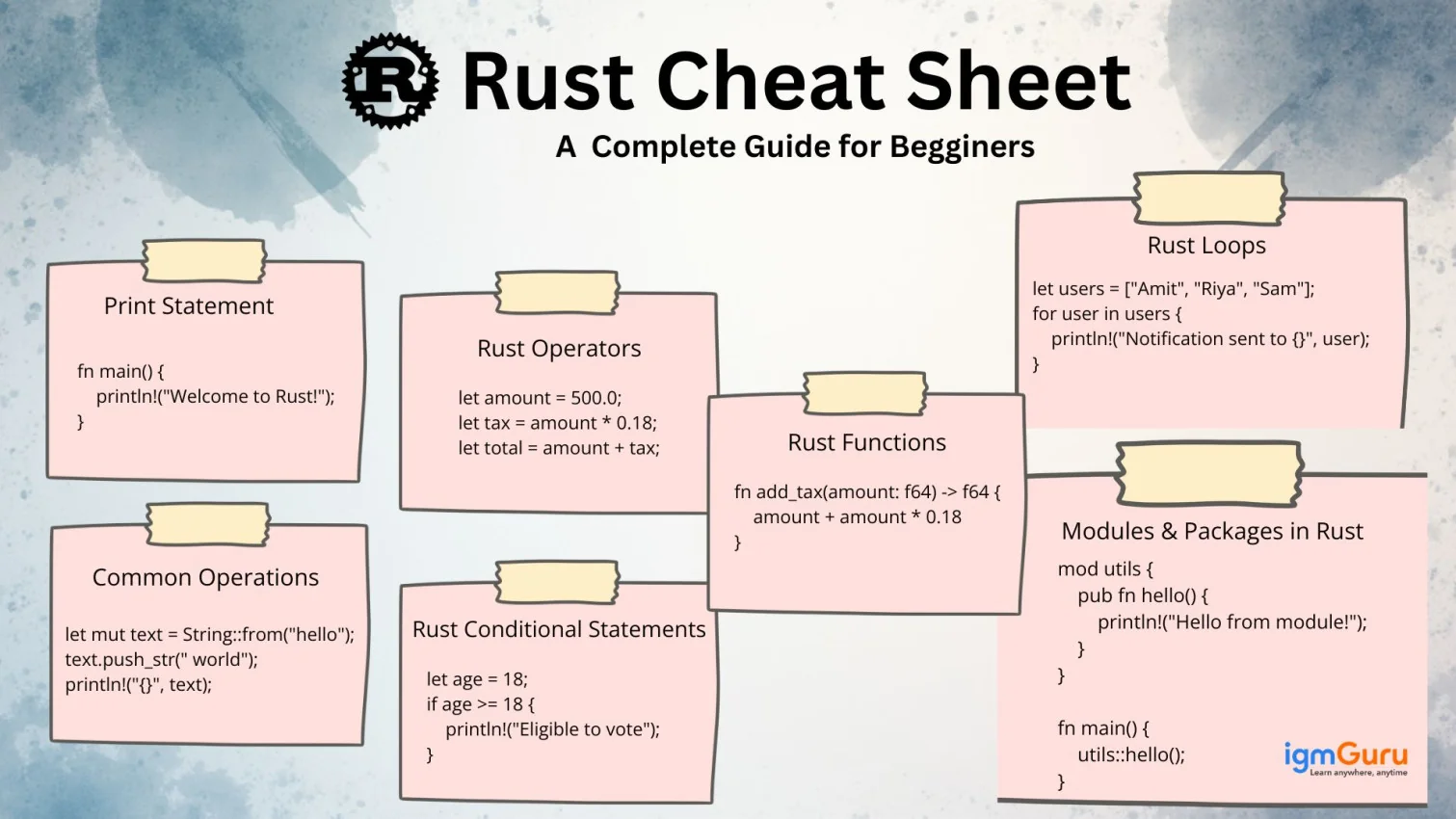
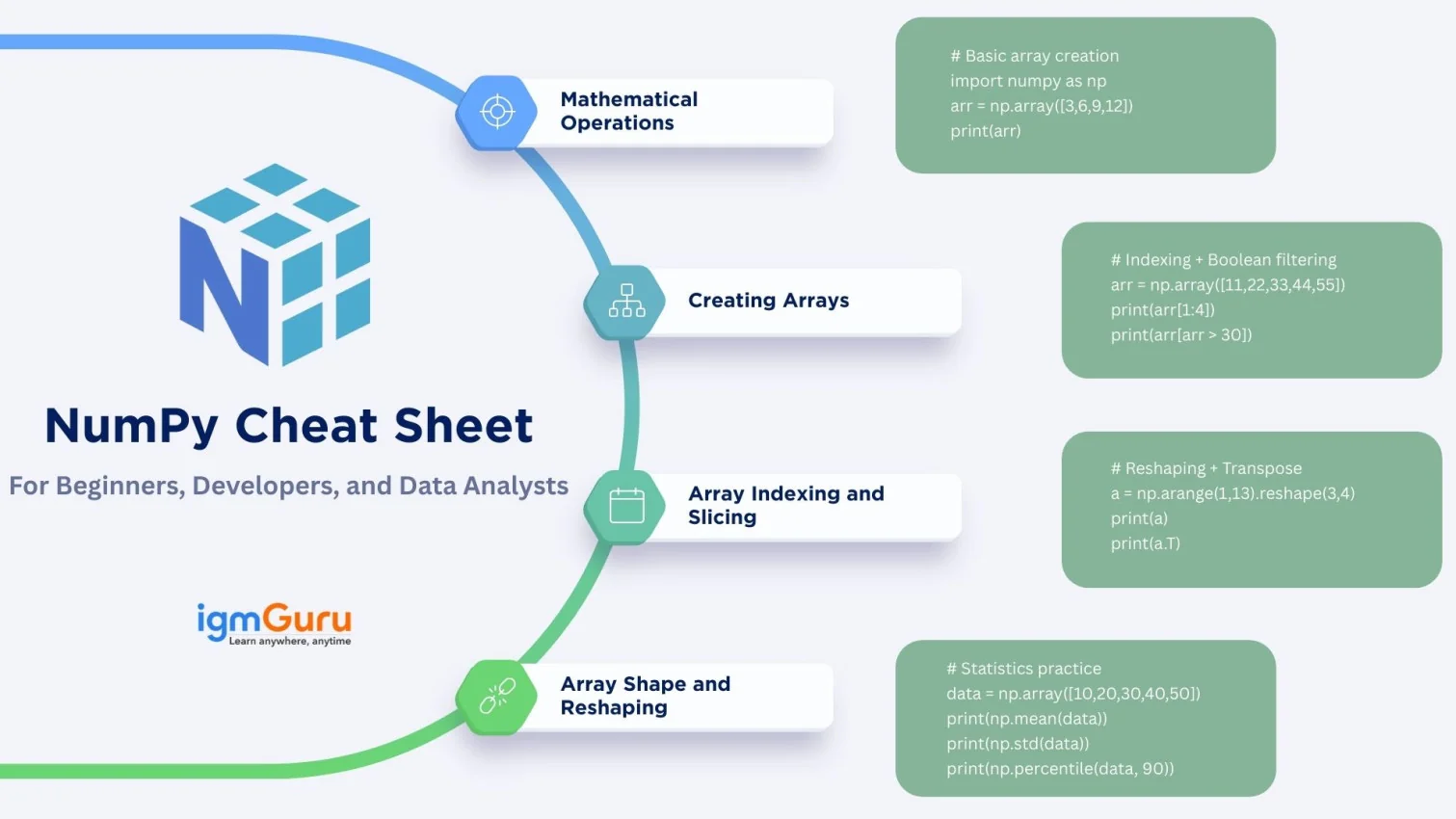
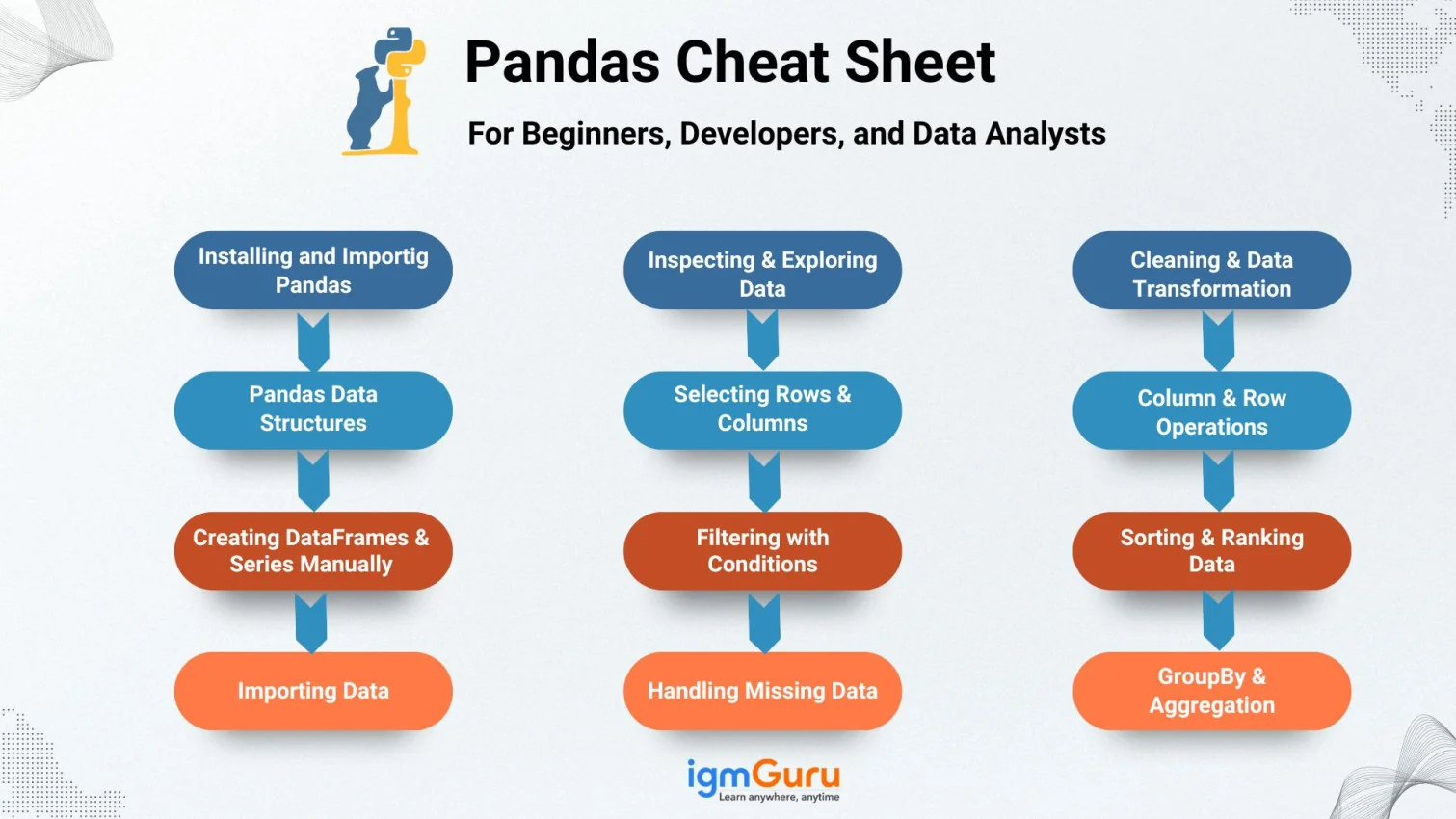
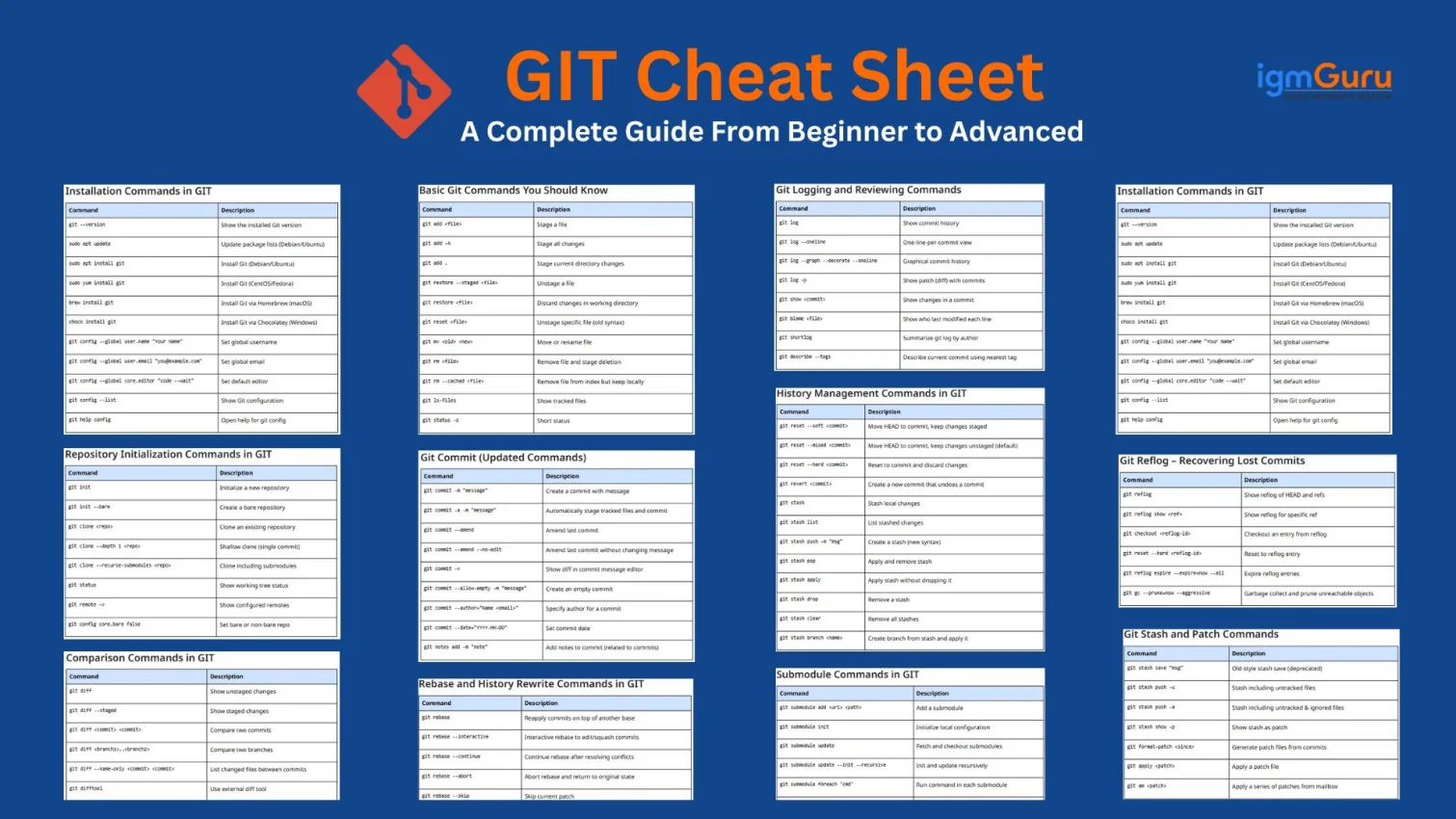
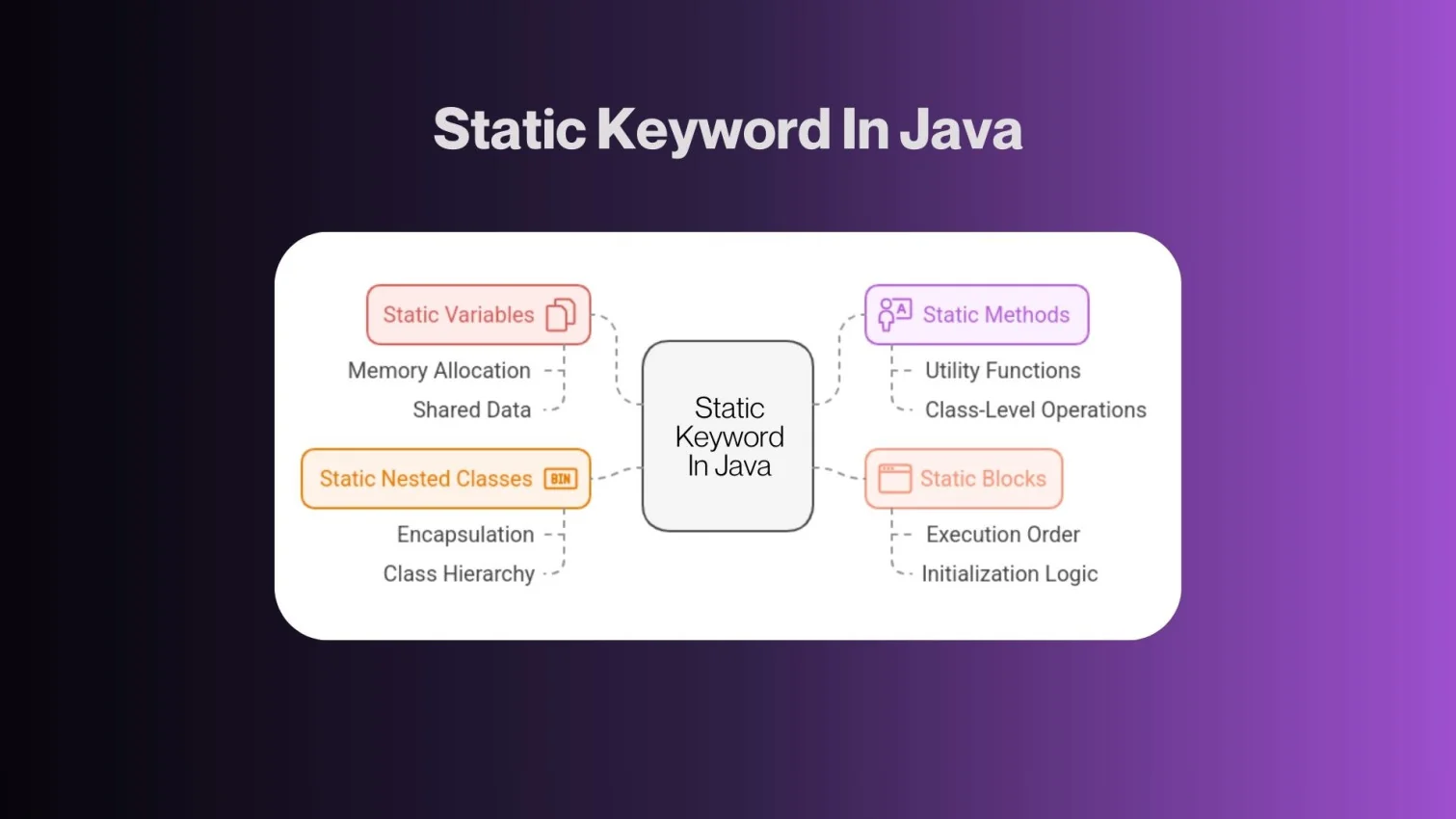
SQL (Structured Query Language) is the standard language used to interact with relational databases. It can create, read, update, and delete data (CRUD), shape results for reports, run analytics, and manage database objects like tables, indexes, views, etc.
SQL works on a declarative approach, which means you describe what you want, and the database figures out how to get it. Don’t you think it can be a great skill for you? Start learning with this SQL cheat sheet, explaining each operation from basic to advanced.
What is SQL?
SQL is a domain-specific language used to handle relational databases. It is too popular that you can see its application in almost every data-based tech. Think of it as a primary language you can use to interact with databases. It allows you to perform various operations on the data stored within them. It also provides different features, including:
- Filter and aggregate (WHERE, GROUP BY, HAVING)
- Modify data (INSERT, UPDATE, DELETE)
- Define schema (CREATE/ALTER/DROP)
- Control transactions (BEGIN/COMMIT/ROLLBACK)
- Extend behavior with views, stored procedures, triggers, and window functions.
Different Dialects of SQL You Can Use
SQL has different database systems with small syntax differences and additional features. It is because of the variety in data and database types. You should be aware of all of them to become proficient in SQL. Some of the common SQL dialects are:
- MySQL/MariaDB - popular for web apps.
- PostgreSQL - known for standards compliance and advanced features (JSON, window functions).
- Oracle (PL/SQL) - enterprise features and powerful procedural extensions.
- SQLite - lightweight, file-based DB for apps and testing.
- Amazon Redshift/Snowflake/BigQuery - analytical variants optimized for data warehousing (each has SQL dialect quirks).
Read Also: PostgreSQL Tutorial For Beginners in 2026
The SQL Cheat Sheet: Every Command You Should Use in 2026
The table given below includes all the commands and concepts, from basic to advanced, that you should know.
| Command / Concept |
Syntax (core) |
Description |
Short example |
| Select basics |
SELECT col1, col2 FROM table; |
Retrieve columns from a table. |
SELECT id, name FROM users; |
| Select all |
SELECT * FROM table; |
Retrieve all columns. |
SELECT * FROM employees; |
| Filter (WHERE) |
SELECT ... FROM ... WHERE condition; |
Filter rows. |
SELECT * FROM orders WHERE status = 'shipped'; |
| Comparison ops |
=, !=, <, <=, >, >= |
Standard comparisons. |
WHERE price > 100 |
| Logical ops |
AND, OR, NOT |
Combine conditions. |
WHERE a=1 AND b>2 |
| IN / NOT IN |
col IN (val1, val2) |
Match one of several values. |
WHERE country IN ('IN','US') |
| BETWEEN |
col BETWEEN low AND high |
Range check (inclusive). |
WHERE date BETWEEN '2025-01-01' AND '2025-01-31' |
| LIKE |
col LIKE 'pattern' |
Pattern matching: % and _. |
WHERE name LIKE 'J%'; |
| IS NULL / IS NOT NULL |
col IS NULL |
Null checks. |
WHERE deleted_at IS NULL |
| Distinct |
SELECT DISTINCT col FROM table; |
Remove duplicates. |
SELECT DISTINCT department FROM employees; |
| Aggregate funcs |
COUNT(), SUM(), AVG(), MIN(), MAX() |
Summaries over groups. |
SELECT COUNT(*) FROM visits; |
| GROUP BY |
SELECT col, AGG() FROM table GROUP BY col; |
Group rows for aggregation. |
SELECT dept, COUNT(*) FROM emp GROUP BY dept; |
| HAVING |
HAVING AGG() condition |
Filter groups after aggregation. |
HAVING COUNT(*) > 10 |
| ORDER BY |
ORDER BY col ASC | DESC |
Sort results. |
|
| LIMIT / OFFSET |
LIMIT n OFFSET m |
Pagination. |
LIMIT 10 OFFSET 20 |
| JOINs |
FROM a JOIN b ON a.x = b.x |
Combine rows from multiple tables. |
INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN |
| Subquery |
SELECT ... FROM (SELECT ...) AS t |
Query inside another query. |
SELECT name FROM (SELECT * FROM users) u |
| Exists |
EXISTS (SELECT 1 FROM ...) |
True if subquery returns rows. |
WHERE EXISTS (SELECT 1 FROM orders o WHERE o.user_id = u.id) |
| UNION / UNION ALL |
SELECT ... UNION SELECT ... |
Combine result sets (UNION removes dups). |
UNION ALL preserves duplicates. |
| INSERT |
INSERT INTO table (c1,c2) VALUES (v1,v2); |
Add rows. |
INSERT INTO users (name, email) VALUES ('Anu','a@x.com'); |
| INSERT ... SELECT |
INSERT INTO t (...) SELECT ... FROM ...; |
Insert from query results. |
INSERT INTO archive SELECT * FROM events WHERE date < ...; |
| UPDATE |
UPDATE table SET c1=v1 WHERE condition; |
Modify rows. |
UPDATE users SET active = false WHERE last_login < '2024-01-01'; |
| DELETE |
DELETE FROM table WHERE condition; |
Remove rows. |
DELETE FROM sessions WHERE expires < now(); |
| CREATE TABLE |
CREATE TABLE t (id INT PRIMARY KEY, name TEXT, ...); |
Define a table and columns. |
CREATE TABLE products (id SERIAL PRIMARY KEY, price NUMERIC); |
| ALTER TABLE |
ALTER TABLE t ADD COLUMN c TYPE; |
Modify schema. |
ALTER TABLE users ADD COLUMN bio TEXT; |
| DROP TABLE |
DROP TABLE table; |
Remove table and data. |
DROP TABLE temp_data; |
| CREATE INDEX |
CREATE INDEX idx_name ON table(column); |
Speed up lookups. |
CREATE INDEX idx_users_email ON users(email); |
| Transactions |
BEGIN; ... COMMIT; / ROLLBACK; |
Group statements into atomic unit. |
BEGIN; UPDATE a...; UPDATE b...; COMMIT; |
| Views |
CREATE VIEW v AS SELECT ...; |
Named stored query (virtual table). |
CREATE VIEW active_users AS SELECT * FROM users WHERE active; |
| Stored procedures / functions |
Varies by dialect (PL/pgSQL, T-SQL, PL/SQL) |
Encapsulate logic in DB. |
CREATE FUNCTION ... |
| Triggers |
CREATE TRIGGER ... |
Run code on table events (INSERT/UPDATE/DELETE). |
Audit trail on INSERT. |
| Common data types |
INT, BIGINT, VARCHAR(n), TEXT, DATE, TIMESTAMP, BOOLEAN, NUMERIC, JSON |
Basic column types. |
email VARCHAR(255), data JSON |
| Window functions |
OVER (PARTITION BY ... ORDER BY ...) |
Row-wise analytics (ROW_NUMBER, RANK, SUM() OVER...). |
ROW_NUMBER() OVER (PARTITION BY dept ORDER BY salary DESC) |
| CASE expression |
CASE WHEN cond THEN val ELSE val END |
Conditional expressions. |
SELECT CASE WHEN qty=0 THEN 'OOS' ELSE 'OK' END |
| EXPLAIN / EXPLAIN ANALYZE |
EXPLAIN SELECT ... |
Show query plan and performance hints. |
EXPLAIN ANALYZE SELECT * FROM big_table; |
| GRANT / REVOKE |
GRANT SELECT ON table TO user; |
Access control. |
GRANT SELECT ON sales TO reporting_user; |
Examples of Using SQL: Basic to Advanced
Let’s explore some real-life examples to understand how to use SQL perfectly:
I. Basic Data Retrieval (SELECT Queries)
1. Select basics
SELECT id, name, email
FROM users;
|
2. Select all
3. Filter (WHERE)
SELECT *
FROM orders
WHERE status = 'shipped';
|
4. Comparison operators
SELECT id, price
FROM products
WHERE price > 100 AND price <= 500;
|
5. Logical operators (AND, OR, NOT)
SELECT *
FROM events
WHERE (type = 'login' OR type = 'signup') AND active = TRUE;
|
6. IN / NOT IN
SELECT id, country
FROM customers
WHERE country IN ('IN', 'US', 'GB');
|
7. BETWEEN
SELECT order_id, created_at
FROM orders
WHERE created_at BETWEEN '2025-01-01' AND '2025-01-31';
|
8. LIKE
SELECT id, name
FROM users
WHERE name LIKE 'J%n';
|
9. IS NULL / IS NOT NULL
SELECT id, deleted_at
FROM posts
WHERE deleted_at IS NULL;
|
10. DISTINCT
SELECT DISTINCT department
FROM employees;
|
II. Aggregation & Grouping
11. Aggregate functions
SELECT COUNT(*) AS total_orders,
SUM(total_amount) AS total_revenue,
AVG(total_amount) AS avg_order
FROM orders;
|
12. GROUP BY
SELECT department, COUNT(*) AS headcount
FROM employees
GROUP BY department;
|
13. HAVING
SELECT department, COUNT(*) AS headcount
FROM employees
GROUP BY department
HAVING COUNT(*) > 10;
|
14. ORDER BY
SELECT id, created_at
FROM tickets
ORDER BY created_at DESC;
|
15. LIMIT / OFFSET
SELECT id, name
FROM products
ORDER BY id
LIMIT 10 OFFSET 20;
|
IV. Joins & Subqueries
16. JOINS (INNER / LEFT)
-- INNER JOIN
SELECT u.id, u.name, o.id AS order_id
FROM users u
JOIN orders o ON o.user_id = u.id;
-- LEFT JOIN
SELECT u.id, u.name, o.id AS order_id
FROM users u
LEFT JOIN orders o ON o.user_id = u.id;
|
17. Subqueries (scalar + table)
-- Scalar
SELECT id,
(SELECT COUNT(*) FROM orders o WHERE o.user_id = u.id) AS order_count
FROM users u;
-- Table subquery
SELECT name
FROM (SELECT name FROM users WHERE active = TRUE) AS active_users;
|
18. EXISTS
SELECT u.id, u.name
FROM users u
WHERE EXISTS (
SELECT 1 FROM orders o WHERE o.user_id = u.id AND o.status = 'completed'
);
|
19. UNION / UNION ALL
SELECT email FROM customers_us
UNION
SELECT email FROM customers_eu;
SELECT email FROM customers_us
UNION ALL
SELECT email FROM customers_eu;
|
V. Data Modification (DML)
20. INSERT
INSERT INTO users (name, email, signup_date)
VALUES ('Asha', 'asha@example.com', CURRENT_DATE);
|
21. INSERT … SELECT
INSERT INTO archive_events (id, event_data, archived_at)
SELECT id, event_data, NOW()
FROM events
WHERE created_at < '2024-01-01';
|
22. UPDATE
UPDATE users
SET last_login = NOW()
WHERE id = 42;
|
23. DELETE
DELETE FROM sessions
WHERE expires_at < NOW();
|
VI. Schema Definition (DDL)
24. CREATE TABLE
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255),
price NUMERIC(10,2),
created_at TIMESTAMP DEFAULT NOW()
);
|
25. ALTER TABLE
ALTER TABLE users
ADD COLUMN bio TEXT;
|
26. DROP TABLE
DROP TABLE IF EXISTS temp_data;
|
27. CREATE INDEX
CREATE INDEX idx_orders_customer
ON orders(customer_id);
|
VII. Transactions & Database Control
28. Transactions (BEGIN / COMMIT / ROLLBACK)
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
|
29. Views
CREATE VIEW active_users AS
SELECT id, name
FROM users
WHERE active = TRUE;
|
30. Grant / Revoke
GRANT SELECT, INSERT ON sales TO sales_app;
REVOKE DELETE ON sales FROM junior_analyst;
|
VIII. Advanced SQL
31. Stored function (PostgreSQL example)
CREATE FUNCTION add_numbers(a INT, b INT)
RETURNS INT AS $$
BEGIN
RETURN a + b;
END;
$$ LANGUAGE plpgsql;
|
32. Trigger
CREATE FUNCTION audit_user_insert() RETURNS TRIGGER AS $$
BEGIN
INSERT INTO audit_log (user_id, action)
VALUES (NEW.id, 'user_created');
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg_audit_user_insert
AFTER INSERT ON users
FOR EACH ROW EXECUTE FUNCTION audit_user_insert();
|
33. Common data types
CREATE TABLE sample (
id BIGINT,
name VARCHAR(100),
profile JSONB,
price NUMERIC(8,2),
active BOOLEAN,
created_at TIMESTAMP
);
|
34. Window functions
SELECT user_id, amount,
SUM(amount) OVER (PARTITION BY user_id ORDER BY created_at) AS running_total,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_at DESC) AS rn
FROM payments;
|
35. CASE expression
SELECT id, qty,
CASE
WHEN qty = 0 THEN 'Out of stock'
WHEN qty < 5 THEN 'Low'
ELSE 'In stock'
END AS stock_status
FROM inventory;
|
36. EXPLAIN / EXPLAIN ANALYZE
EXPLAIN ANALYZE
SELECT * FROM huge_table WHERE customer_id = 123;
|
IX. Dialect-Specific Notes (Optional but Useful)
37. LIMIT vs TOP vs FETCH
-- MySQL/PostgreSQL
SELECT * FROM products ORDER BY id LIMIT 5;
-- SQL Server
SELECT TOP 5 * FROM products;
|
38. Auto-increment differences
-- PostgreSQL
CREATE TABLE t (id SERIAL PRIMARY KEY);
-- MySQL
CREATE TABLE t (id INT AUTO_INCREMENT PRIMARY KEY);
|
39. Date/time function differences
SELECT NOW(); -- Postgres/MySQL
SELECT GETDATE(); -- SQL Server
|
Wrap-Up
SQL remains one of the most essential skills in data, development, analytics, and backend engineering. Whether you’re filtering data, joining tables, writing reports, or managing large-scale databases, the commands you learned here form the foundation for everything you’ll do with SQL.
This SQL cheat sheet is designed to give beginners a complete, ready-to-use reference. It is something you can quickly scan before writing a query or preparing for an interview. As you continue learning, try running each example in a real database environment. The more you practice, the faster SQL will feel like second nature.
Read Also
FAQs
1. Is SQL hard to learn for beginners?
Not really. With the declarative approach of SQL, you only need to tell the database what you want. So, anyone can learn it.
2. Which SQL dialect should I start with?
If you're just learning, start with MySQL or PostgreSQL. Both are free, widely used, and beginner-friendly. Once you learn the basics, switching between dialects becomes easy.
3. Can SQL be used for data science and analytics?
Yes, SQL is one of the most important skills for data analysts and data scientists. It’s used for data cleaning, filtering, aggregation, reports, and preparing datasets for machine learning.