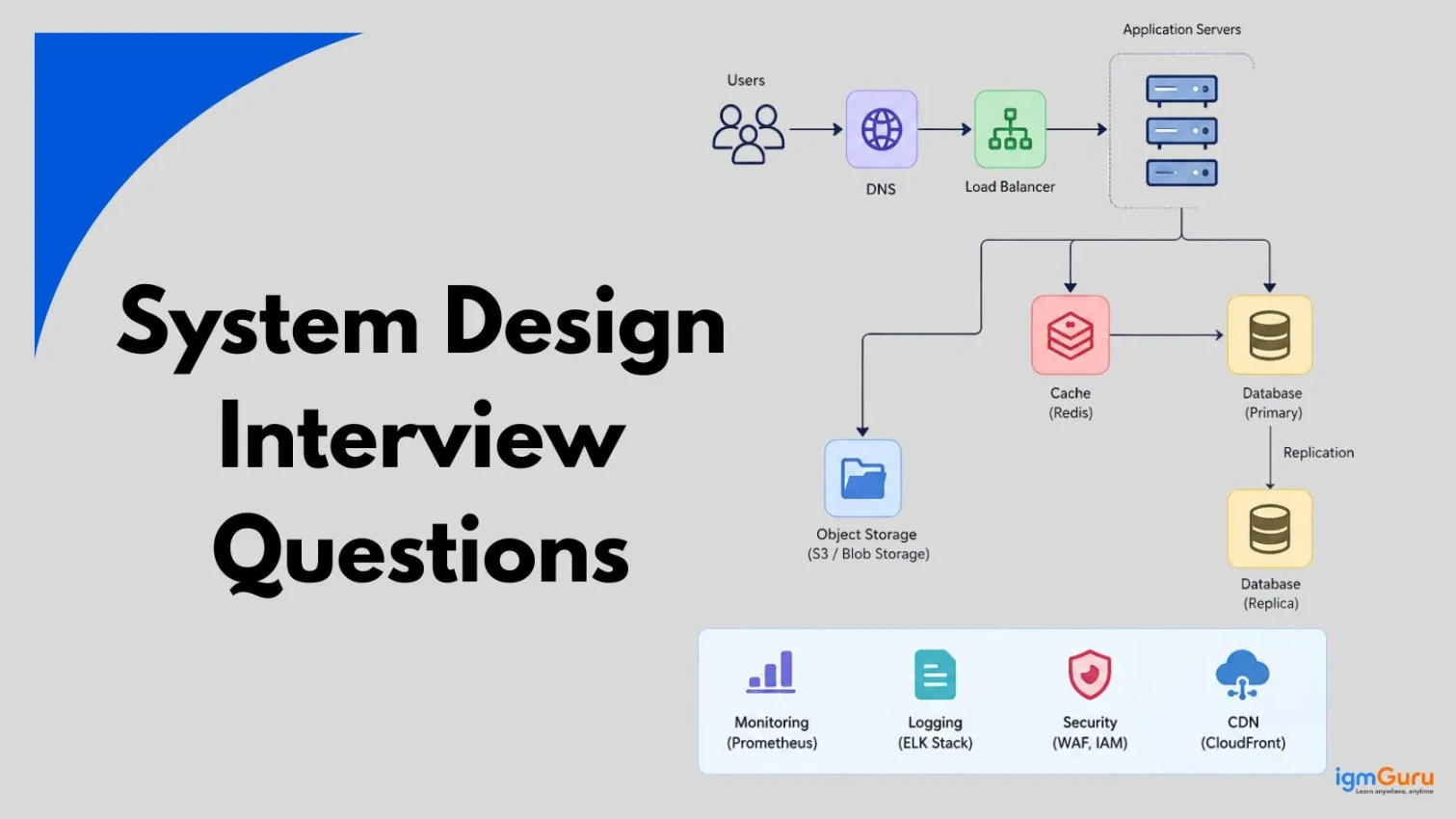
System design interviews are one of the most important rounds in technical hiring today. Whether you are applying to Google, Amazon, Microsoft, or a fast-growing startup, you will almost certainly face system design questions. These questions test how you think about building large-scale systems, not just whether you can write code.
This blog covers 40 system design interview questions and answers across four levels: beginner, intermediate, experienced and scenario-based. You will find clear, practical answers that help you understand the concept and walk into your interview with real confidence.
What Is System Design?
System design is the process of defining the architecture, components, modules, interfaces and data flow for a system that meets specific technical and business requirements. It is not about writing code. It is about thinking through how all the pieces of a large application fit together.
When you design a system, you are making decisions about databases, servers, APIs, caching layers, load balancers and much more. A good system design keeps the application fast, reliable, scalable and cost-efficient.
Companies ask system design interview questions to understand how you think at scale. They want to see that you can design systems that handle millions of users, recover from failures and grow with the business.
Why Does System Design Interviews Matter?
System design interviews matter because senior engineers and architects spend a large part of their day making design decisions. Coding skills alone are not enough at that level. Interviewers use these questions to assess your understanding of:
- Scalability: Can the system handle 10x or 100x more users?
- Reliability: Does the system stay up even when parts of it fail?
- Performance: Does the system respond quickly under heavy load?
- Maintainability: Is the system easy to update and debug over time?
These are real-world engineering concerns and your ability to address them directly reflects your experience and technical depth.
Read Also: Top Software Testing Interview Questions and Answers
How to Approach a System Design Interview
Before jumping into questions and answers, here is a simple framework you can follow in any system design interview:
- Clarify requirements: Ask about the scale, features, and constraints.
- Estimate scale: Calculate storage, traffic, and bandwidth needs.
- Define the API: Decide what endpoints or interfaces the system needs.
- Design the data model: Choose what data to store and how.
- Choose the architecture: Draw out the high-level components.
- Deep dive: Explain the most critical components in detail.
- Identify bottlenecks: Point out single points of failure and how to fix them.
Now, let us go through the questions.
Beginner System Design Interview Questions
These system design interview questions for beginners focus on core concepts. If you are new to system design, start here.
1. What Is the CAP Theorem?
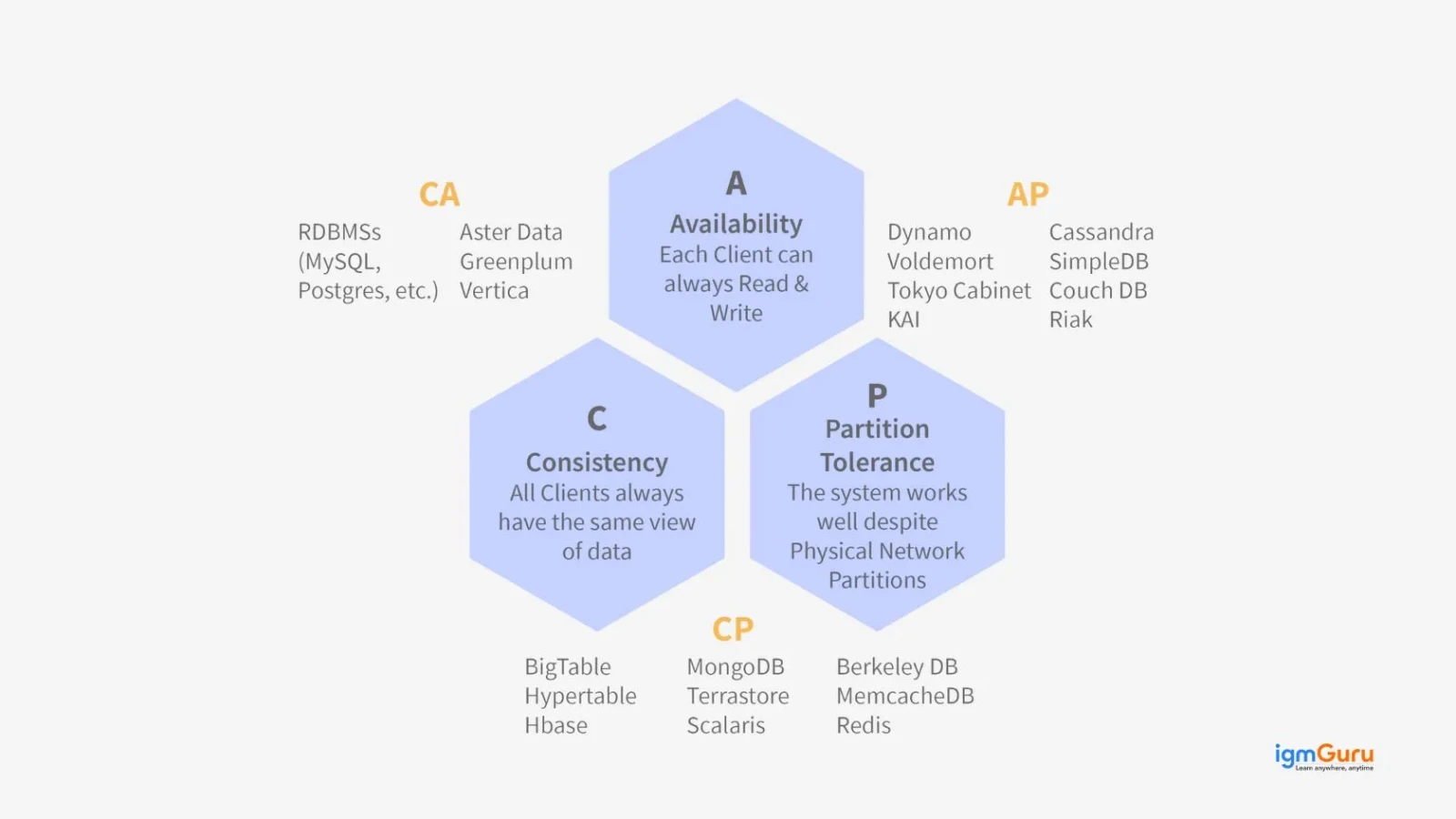
The CAP theorem states that a distributed system can guarantee only two of the following three properties at the same time:
- Consistency (C): Every read receives the most recent write or an error.
- Availability (A): Every request receives a response, though it may not be the most recent data.
- Partition Tolerance (P): The system continues to work even when network partitions cause some nodes to lose communication.
In real distributed systems, network partitions are unavoidable. So you will always have to choose between consistency and availability during a partition. For example, a banking application prioritizes consistency. A social media feed can tolerate some inconsistency for the sake of availability.
Common follow-up: Databases like Cassandra choose AP (availability + partition tolerance). Databases like PostgreSQL choose CP (consistency + partition tolerance).
2. What Is Horizontal Scaling vs. Vertical Scaling?
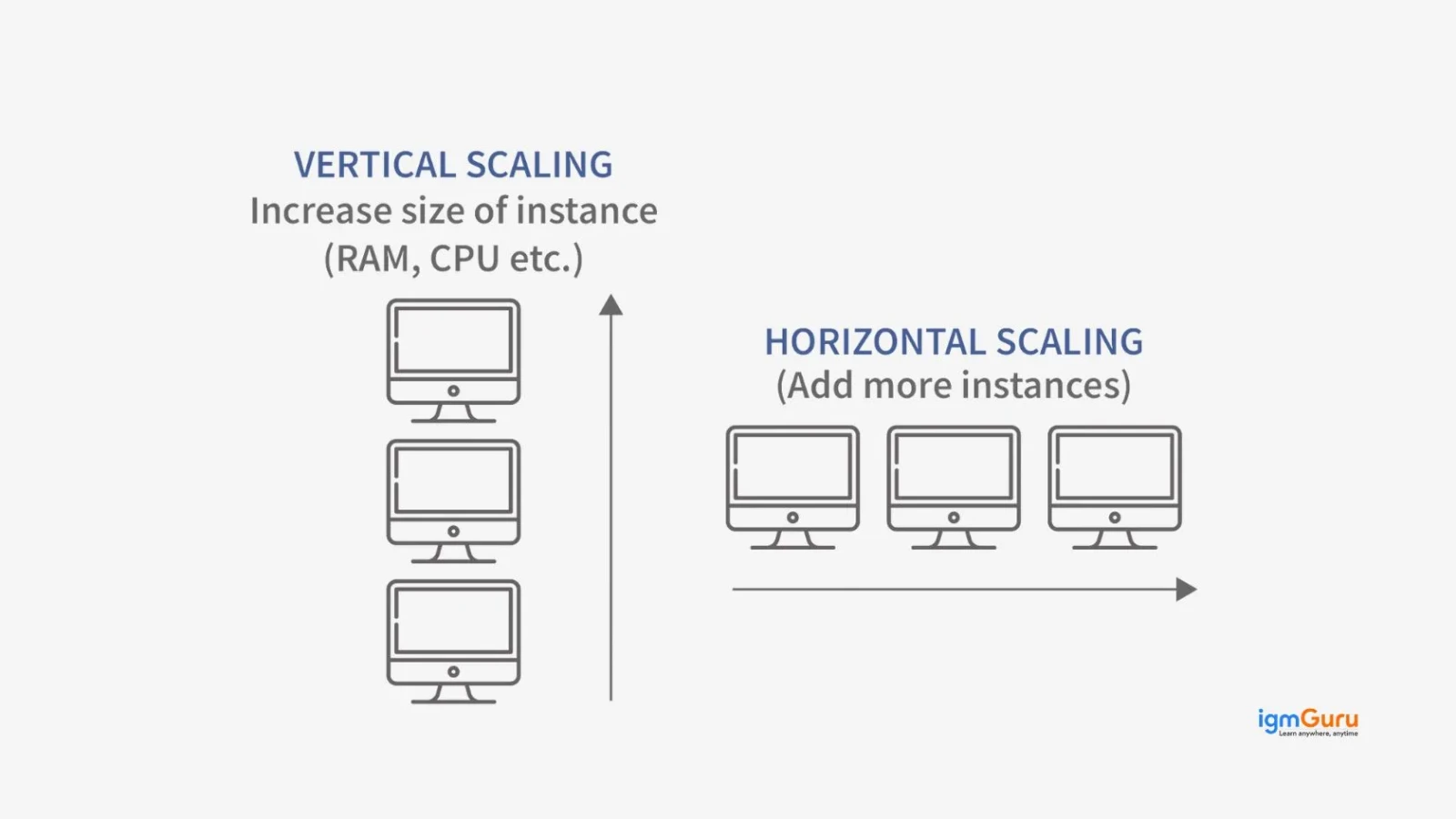
Scaling is about handling growth in users or data. Systems can scale by adding more machines or upgrading existing ones.
| Feature | Horizontal Scaling (Scale Out) | Vertical Scaling (Scale Up) |
| Definition | Adding more servers to distribute load | Increasing power (CPU, RAM) of a single server |
| Cost Efficiency | Often cheaper using commodity hardware | Expensive due to high-end machines |
| Scalability Limit | Virtually unlimited | Limited by hardware capacity |
| Fault Tolerance | High (failure of one node doesn’t crash system) | Low (single point of failure) |
| Complexity | Requires distributed system management | Easier to implement and manage |
3. What Is Load Balancing and Why Is It Important?
A load balancer distributes incoming network traffic across multiple servers so that no single server gets overwhelmed. It sits between the client and the server pool and routes requests based on algorithms like:
- Round Robin: Requests are sent to servers in rotation.
- Least Connections: Requests go to the server with the fewest active connections.
- IP Hash: The client's IP address determines which server handles the request.
Load balancing is critical in system design because it prevents any single server from becoming a bottleneck, improves availability by rerouting traffic when a server fails, and makes horizontal scaling possible.
4. What Is the Difference Between Latency and Throughput?
These metrics measure system performance but focus on different aspects—speed vs. capacity.
| Feature | Latency | Throughput |
| Definition | Time taken to process one request | Number of requests processed per unit time |
| Focus | Speed of individual request | Overall system capacity |
| Unit | Milliseconds (ms) | Requests/sec, MB/sec |
| Goal | Minimize latency | Maximize throughput |
| Example | Page load time | Number of users served per second |
5. What Is Caching and How Does It Work?
Caching stores the results of expensive operations in a faster storage layer so future requests can be served quickly without repeating the work.
For example, instead of querying the database every time a user requests the homepage, you can store the result in a cache like Redis. The next request gets the data from cache in microseconds instead of waiting hundreds of milliseconds for a database query.
Common cache update strategies include:
- Cache-aside (Lazy loading): The application loads data into the cache only when it is needed.
- Write-through: Data is written to both the cache and database at the same time.
- Write-behind (Write-back): Data is written to the cache first and the database is updated asynchronously.
- Read-through: The cache handles reading from the database when a cache miss occurs.
6. What Is Database Sharding?
Sharding is the process of splitting a large database into smaller, faster, and more manageable pieces called shards. Each shard holds a subset of the total data and runs on a separate database server.
For example, you can shard a users table by user ID. Users with IDs 1 to 1,000,000 go to Shard 1. Users with IDs 1,000,001 to 2,000,000 go to Shard 2, and so on. Sharding improves read and write performance, increases storage capacity, and allows the database layer to scale horizontally.
The main challenge with sharding is that it adds complexity around querying across shards, rebalancing shards when data grows unevenly, and managing transactions that span multiple shards.
7. What Is the Difference Between SQL and NoSQL Databases?
Databases differ in structure, scalability, and flexibility based on application needs.
| Feature | SQL Databases | NoSQL Databases |
| Structure | Structured (tables, rows, columns) | Unstructured / semi-structured |
| Schema | Fixed schema | Flexible schema |
| Scalability | Vertical scaling | Horizontal scaling |
| Consistency | Strong consistency (ACID) | Eventual consistency (BASE) |
| Examples | MySQL, PostgreSQL | MongoDB, Cassandra |
8. What Is a Content Delivery Network (CDN)?
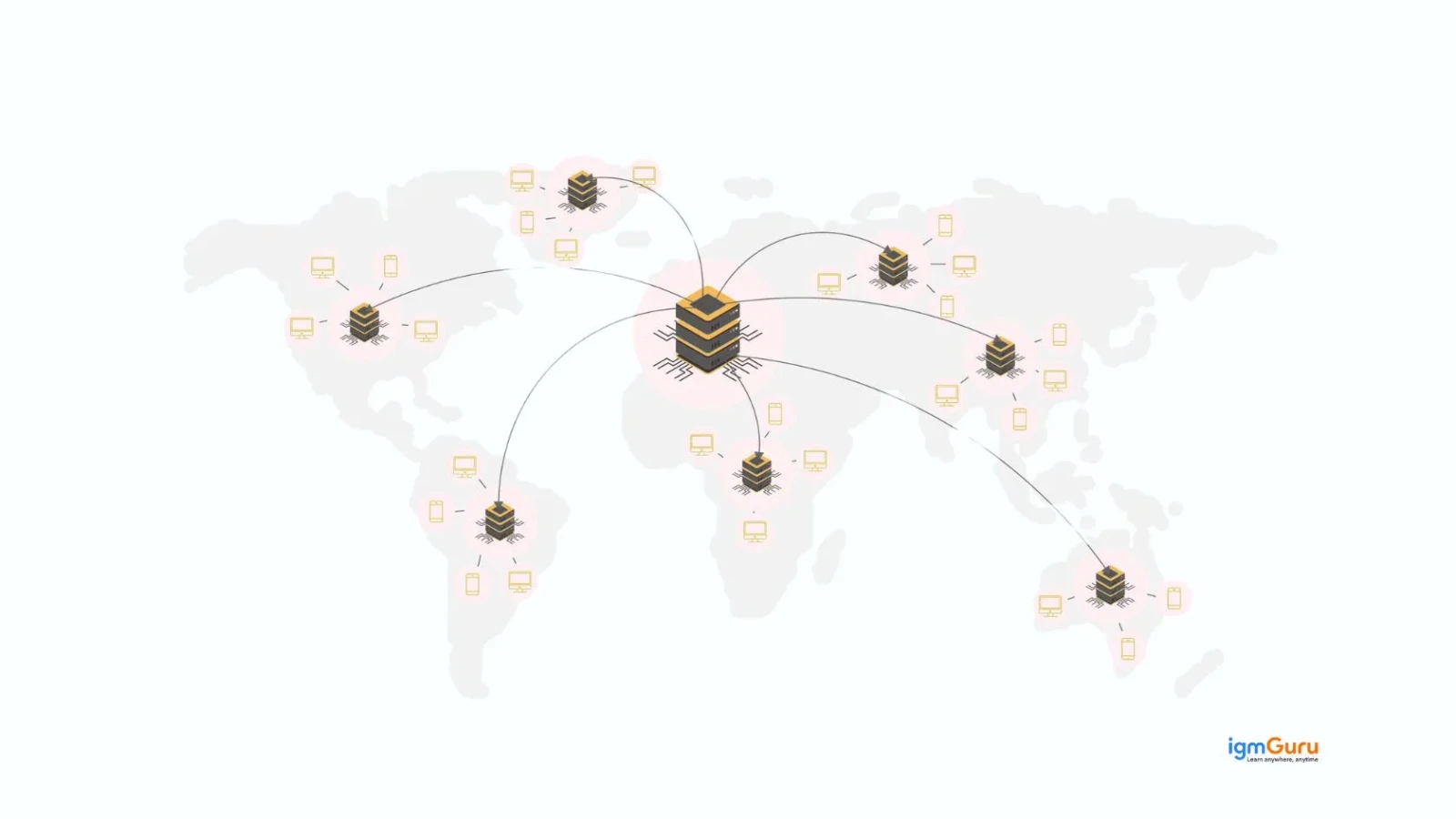
A Content Delivery Network is a geographically distributed network of servers that delivers static content (images, videos, CSS, JavaScript) to users from the server closest to their location.
Without a CDN, all requests go to the origin server regardless of where the user is. A user in Tokyo accessing a server in New York experiences high latency. With a CDN, that user gets content from a CDN node in Tokyo, which dramatically reduces load time.
CDNs also reduce the load on origin servers, protect against DDoS attacks, and improve availability through redundancy.
9. What Is the Difference Between Monolithic and Microservices Architecture?
Application architecture defines how components are structured and deployed.
| Feature | Monolithic Architecture | Microservices Architecture |
| Structure | Single unified codebase | Multiple independent services |
| Deployment | Entire app deployed together | Services deployed independently |
| Scalability | Harder to scale specific parts | Easy to scale individual services |
| Fault Isolation | One failure affects entire app | Failures isolated to services |
| Complexity | Simpler initially | More complex (network, APIs) |
10. What Is an API Gateway?
An API Gateway is a server that acts as the single entry point for all client requests in a microservices system. It handles routing, authentication, rate limiting, SSL termination, and response aggregation.
Instead of the client calling ten different microservices directly, it sends one request to the API gateway. The gateway routes the request to the right service, collects the response, and sends it back to the client.
Popular API gateways include AWS API Gateway, Kong, and NGINX.
Read Also: Top Software Engineering Interview Questions
These intermediate system design interview questions go deeper into distributed systems, databases, and design patterns.
1. What Is Consistent Hashing and Why Is It Used?
Consistent hashing is a technique used to distribute data across multiple nodes in a distributed system in a way that minimizes data movement when nodes are added or removed.
In traditional hashing, adding or removing a node causes almost all keys to be reassigned. In consistent hashing, only a small fraction of keys move when the ring changes. This makes it ideal for distributed caches and distributed databases.
Systems like Cassandra, Amazon DynamoDB, and Memcached use consistent hashing to distribute data evenly and handle node failures gracefully.
2. What Are the Different Types of Database Replication?
Database replication copies data from one database server (primary) to one or more other servers (replicas) to improve availability and read performance.
- Master-Slave Replication: The master handles all writes. Slaves replicate the data and handle read queries. If the master fails, a slave can be promoted.
- Master-Master Replication: Multiple masters accept writes. Data is synced between them. This allows higher write availability but introduces conflict resolution challenges.
- Synchronous Replication: The primary waits for the replica to confirm before completing the write. Strong consistency, but higher latency.
- Asynchronous Replication: The primary does not wait for replica confirmation. Lower latency, but small risk of data loss if the primary fails before the replica syncs.
3. What Is a Message Queue and When Should You Use It?
A message queue is an asynchronous communication mechanism where producers send messages to a queue and consumers process them independently.
You should use a message queue when:
- You need to decouple services so they do not depend on each other being available at the same time.
- You want to handle traffic spikes by buffering requests.
- You need guaranteed delivery of events, even if the consumer is temporarily down.
- You are building event-driven or stream-processing systems.
Popular message queue systems include Apache Kafka, RabbitMQ, and Amazon SQS.
4. What Is the Difference Between a Proxy and a Reverse Proxy?
Both act as intermediaries but serve different roles in network communication.
| Feature | Proxy | Reverse Proxy |
| Position | Between client and internet | Between client and servers |
| Purpose | Hides client identity | Hides server identity |
| Use Case | Access control, anonymity | Load balancing, caching |
| Direction | Client → Proxy → Server | Client → Reverse Proxy → Server |
| Example | Corporate firewall proxy | Nginx, Cloudflare |
5. What Is Rate Limiting and How Do You Implement It?
Rate limiting controls how many requests a client can make to a system in a given time window. It protects the system from abuse, DDoS attacks, and unintentional overload.
Common rate limiting algorithms include:
- Fixed Window Counter: Counts requests in fixed time windows (e.g., 100 requests per minute). Simple but allows burst traffic at window boundaries.
- Sliding Window Log: Tracks the timestamp of each request and allows requests only if the count in the last N seconds is below the limit. More accurate but memory-intensive.
- Token Bucket: A bucket holds tokens. Each request consumes a token. Tokens refill at a fixed rate. Allows bursts up to the bucket size.
- Leaky Bucket: Requests fill a bucket that leaks at a steady rate. Smooths out bursts.
- Rate limiting is typically implemented at the API gateway or load balancer level.
6. What Is Data Partitioning and What Are Its Strategies?
Data partitioning divides a large dataset into smaller parts to distribute the load across multiple storage nodes.
Common partitioning strategies include:
- Horizontal Partitioning (Sharding): Rows are split across different tables or databases based on a key (like user ID or geography).
- Vertical Partitioning: Columns are split across different tables. For example, frequently accessed columns go in one table while rarely accessed ones go in another.
- Directory-Based Partitioning: A lookup table maps data to the appropriate partition. Flexible but introduces a single point of failure if not replicated.
Choosing the right partitioning strategy depends on your access patterns, query requirements, and expected data growth.
7. What Is the Difference Between Strong Consistency and Eventual Consistency?
Consistency models define how data updates are reflected across distributed systems.
| Feature | Strong Consistency | Eventual Consistency |
| Definition | All nodes see same data instantly | Data becomes consistent over time |
| Accuracy | Always up-to-date | May show stale data temporarily |
| Performance | Slower due to synchronization | Faster and more scalable |
| Use Case | Banking systems | Social media feeds |
| Trade-off | Lower availability | Temporary inconsistency |
8. What Is a Distributed Cache and How Is It Different from Local Cache?
A local cache stores data in the memory of a single server. It is fast but only available to that one server. If the server restarts, the cache is lost.
A distributed cache stores data across multiple servers in a cluster. All application servers can access the same cache. Redis and Memcached are the most common distributed caches. They provide high availability through replication and can handle very large datasets that would not fit in a single server's memory.
Distributed caching is essential in horizontally scaled systems where many application servers need to share the same cached data.
9. What Is the Two-Phase Commit Protocol?
The two-phase commit (2PC) protocol is a distributed algorithm that ensures all nodes in a transaction either commit or roll back together. It maintains atomicity across distributed systems.
- Phase 1 (Prepare): The coordinator asks all participants if they are ready to commit.
- Phase 2 (Commit/Abort): If all participants say yes, the coordinator sends a commit command. If any participant says no, the coordinator sends a rollback command.
The downside of 2PC is that it can block if the coordinator fails after the prepare phase. Systems like Google Spanner use more advanced protocols to avoid this.
10. What Is Service Discovery in Microservices?
In a microservices architecture, services need to find and communicate with each other. Service discovery is the mechanism that allows services to locate each other dynamically without hardcoding IP addresses or ports.
There are two types:
- Client-side discovery: The client queries a service registry (like Eureka or Consul) and selects which instance to call.
- Server-side discovery: The client sends requests to a load balancer or router, which queries the service registry and forwards the request.
Service discovery is critical in dynamic environments like Kubernetes where service instances start and stop frequently.
Read Also: Operating System Interview Questions and Answers
Experienced System Design Interview Questions
These system design interview questions for experienced engineers test your ability to design real-world systems at scale and make trade-off decisions under constraints.
1. How Would You Design a URL Shortening Service Like TinyURL?
Requirements: Users submit a long URL and get a short URL. When they visit the short URL, they are redirected to the original.
Key design decisions:
- Encoding: Generate a unique 6-8 character key using Base62 encoding (a-z, A-Z, 0-9). This gives you 62^6 = 56 billion possible URLs.
- Database: Store the mapping of short key to long URL in a relational or key-value database. A key-value store like DynamoDB works well here because access patterns are simple.
- Redirection: When a user visits the short URL, the server looks up the key and returns a 301 (permanent) or 302 (temporary) redirect.
- Caching: Cache the most popular mappings in Redis to reduce database load.
- Custom aliases: Allow users to choose their own short key if it is not already taken.
- Analytics: Track click counts and timestamps in a separate analytics service to avoid slowing down the redirect path.
Scale considerations: At 100 million URLs per day, you need to handle around 1,200 writes per second and potentially millions of reads per second. Horizontal scaling of the API layer and database read replicas are essential.
2. How Would You Design a Distributed Message Queue Like Kafka?
A distributed message queue needs to handle high-throughput writes, guarantee message delivery, and allow multiple consumers to read from the same stream.
Core components:
- Producers: Applications that publish messages to topics.
- Brokers: Servers that store and serve messages. Kafka uses a cluster of brokers.
- Topics and Partitions: Topics are logical channels. Each topic is split into partitions distributed across brokers. This allows parallel processing.
- Consumers and Consumer Groups: Consumers read messages from partitions. Consumer groups allow multiple instances to process different partitions simultaneously.
- ZooKeeper / KRaft: Manages cluster metadata and leader election.
Durability: Messages are persisted to disk on each broker. Replication ensures that if one broker fails, another has the data.
Message ordering: Kafka guarantees ordering within a partition, not across partitions. If ordering is critical, you must route related messages to the same partition using a partition key.
3. How Would You Design a Global File Storage System Like Google Drive?
Core features: Upload, download, share, sync across devices, and version control.
Key components:
- Metadata service: Stores file names, paths, ownership, sharing permissions, and version history in a relational database.
- Blob storage: The actual file content is stored in object storage like Amazon S3. Files are split into chunks (typically 4MB) and each chunk is stored separately. This allows efficient delta sync (only changed chunks are uploaded during updates).
- Sync service: Detects changes on the client device and syncs them to the server. Uses a client agent that monitors file system events.
- CDN: Serves popular files from edge nodes close to the user.
- Deduplication: If two users upload the same file, store only one copy and reference it from both accounts.
Conflict resolution: If two users edit the same file simultaneously, the system creates a conflict copy and notifies the user.
4. How Would You Design a Web Crawler?
A web crawler systematically browses the internet to index web pages for search engines.
Key components:
- URL Frontier: A queue of URLs to visit. It must prioritize important pages and avoid revisiting the same URL too often.
- Fetcher: Downloads web pages from URLs in the frontier.
- Parser: Extracts content and discovers new URLs from downloaded pages.
- Deduplication: Checks whether a URL or page has already been crawled. Uses a distributed hash table or Bloom filter.
- Storage: Crawled content is stored in a distributed file system or object storage.
- Robots.txt: The crawler must respect the crawling rules published by each website.
Scale considerations: A large-scale crawler handles billions of URLs. The URL Frontier must be distributed across multiple machines. The fetcher must use politeness policies to avoid overloading any single website.
5. How Would You Design a Ride-Sharing Service Like Uber?
Core features: Match riders to nearby drivers, track driver location in real time, calculate fare, and handle payments.
Key components:
- Location service: Drivers continuously send GPS coordinates (every 4 seconds). The system stores these in a geospatial index (like Google S2 or geohash) to enable fast "find drivers near this location" queries.
- Matching service: When a rider requests a ride, the system finds available drivers within a certain radius, ranks them by distance and ETA, and sends a request to the closest driver.
- Trip service: Manages the lifecycle of a trip (requested, accepted, in progress, completed).
- Routing service: Calculates optimal routes using map data. Integrates with services like Google Maps API or uses a proprietary routing engine.
- Payment service: Processes payments after trip completion. Uses a third-party payment gateway.
- Surge pricing: A separate service monitors supply and demand in each geographic area and calculates multipliers.
Real-time communication: WebSockets or long polling maintains persistent connections between the app and server for real-time location updates and trip status changes.
6. How Would You Design a Distributed Rate Limiter?
A distributed rate limiter needs to enforce limits consistently across multiple API servers.
Approach using Redis:
- Use Redis as the shared store for request counters.
- For each client, maintain a counter in Redis with an expiration time matching the rate limit window.
- When a request arrives, use a Lua script to atomically increment the counter and check if it exceeds the limit. Lua scripts in Redis are atomic, which prevents race conditions.
Sliding window with Redis sorted sets:
- Store each request as a member of a sorted set with the timestamp as the score.
- Remove members older than the window duration.
- Count the remaining members. If the count exceeds the limit, reject the request.
Challenges: At very high traffic, the counter update in Redis can become a bottleneck. You can reduce this by allowing each API server to maintain a local counter and sync with Redis periodically, accepting a small tolerance in the limit.
7. How Would You Design a Notification System?
A notification system needs to deliver push notifications, emails, and SMS reliably and at scale.
Key components:
- Event ingestion: Services publish events (order placed, friend request, payment received) to a message queue like Kafka.
- Notification service: Consumes events, determines the notification type, looks up user preferences and device tokens.
- Channel handlers: Separate services handle each channel (push via APNs/FCM, email via SendGrid/SES, SMS via Twilio).
- Retry mechanism: If delivery fails, the system queues the notification for retry with exponential backoff.
- User preferences: Store per-user preferences for which notification types they want on which channels.
- Deduplication: Prevent sending the same notification twice if a message is processed more than once.
Scale: At 10 million notifications per day, the system needs to process around 120 per second on average with the ability to handle spikes.
8. How Would You Design a Search Autocomplete System?
A search autocomplete system suggests completions as the user types.
Key components:
- Data collection: Log all search queries. Build a frequency table of queries and their counts.
- Trie data structure: Store all popular queries in a trie. Each node represents a character. To find suggestions, traverse the trie to the prefix the user has typed, then return the most frequent completions under that node.
- Distributed trie: For large datasets, the trie is sharded. A consistent hashing approach distributes prefixes across multiple servers.
- Caching: The most common prefixes (like "ho", "te") are cached in Redis for sub-millisecond response times.
- Update frequency: The trie is rebuilt periodically (e.g., daily or weekly) from the aggregated query logs rather than updated on every search.
Latency requirement: Autocomplete must respond in under 100ms to feel instant to the user. Caching the top prefixes is the most effective way to achieve this.
9. How Would You Design an E-Commerce Flash Sale System?
A flash sale involves thousands or millions of users simultaneously trying to buy limited inventory.
Challenges: Overselling (selling more than the available stock), database overload, and system crashes under spike traffic.
Solutions:
- Pre-load inventory into Redis: Use Redis to track the remaining stock. Redis operations are atomic, so decrementing the counter is race-condition-safe.
- Queue incoming requests: Do not let all users hit the database at once. Place purchase requests into a queue (Kafka or SQS) and process them sequentially.
- Rate limiting at the entry point: Use aggressive rate limiting and CAPTCHA to prevent bot traffic.
- Separate the flash sale service: Run the flash sale logic as an isolated service with its own infrastructure to prevent it from affecting other parts of the platform.
- Idempotency: Ensure that if a user's request is retried, it does not result in a double purchase.
10. How Would You Design a Distributed Logging and Monitoring System?
A distributed logging system collects, stores, and makes searchable the logs generated by all services in a large system.
Key components:
- Log agents: Lightweight agents on each server collect logs and send them to a centralized collector (like Fluentd or Logstash).
- Message queue buffer: Logs are sent to Kafka first. This prevents log data from being lost if the storage backend is temporarily slow.
- Storage: Logs are stored in Elasticsearch (for fast full-text search) and cold object storage (like S3) for long-term retention.
- Visualization: Kibana or Grafana provides dashboards for searching and visualizing logs.
- Alerting: Rules trigger alerts (via PagerDuty or Slack) when error rates exceed thresholds.
- Distributed tracing: Tools like Jaeger or Zipkin trace individual requests as they move across microservices. Each request carries a trace ID that is logged at every service boundary.
Read Also: Java Tutorial
Scenario-Based System Design Interview Questions
Scenario-based system design interview questions test your ability to handle real constraints, trade-offs, and failure modes. These are common at senior levels.
1. Your Application Database Is Becoming a Bottleneck. What Steps Do You Take?
This is one of the most common real-world system design scenarios.
- Step 1 — Profile the bottleneck: Identify whether the problem is slow queries, high read volume, or high write volume. Use database slow query logs and monitoring tools.
- Step 2 — Optimize queries and indexing: Add missing indexes. Rewrite expensive queries. Avoid N+1 query problems in the application layer.
- Step 3 — Add read replicas: If the problem is high read volume, route read traffic to read replicas. The primary handles only writes.
- Step 4 — Introduce caching: Add Redis or Memcached in front of the database. Cache frequently read, rarely changing data.
- Step 5 — Connection pooling: Use a connection pooler like PgBouncer to reduce the overhead of opening and closing database connections.
- Step 6 — Vertical scaling: Temporarily scale up the database instance to relieve pressure while long-term solutions are implemented.
- Step 7 — Shard the database: If the write volume is genuinely too high for a single database, implement sharding.
2. Your Service Is Experiencing a DDoS Attack. How Do You Respond?
A DDoS (Distributed Denial of Service) attack floods your system with traffic to make it unavailable.
Immediate actions:
- Enable rate limiting at the load balancer or API gateway to reject traffic from offending IP addresses.
- Activate your CDN's DDoS protection (Cloudflare, AWS Shield, Akamai) to absorb attack traffic at the edge before it reaches your servers.
- Use IP reputation lists and geo-blocking if the attack traffic is concentrated in specific regions.
Medium-term measures:
- Implement CAPTCHAs and bot detection at critical endpoints.
- Use Anycast routing to distribute the attack traffic across multiple data centers.
- Set aggressive timeouts and connection limits on your web servers.
Long-term design:
- Design your system to be stateless so you can scale out quickly under load.
- Use auto-scaling groups to absorb legitimate traffic spikes.
- Maintain relationships with upstream providers who can null-route attack traffic at the network level.
3. How Would You Handle a Sudden 10x Traffic Spike?
Suppose your system normally handles 10,000 requests per second and suddenly receives 100,000 requests per second.
Pre-incident (design for it):
- Use auto-scaling groups on your application tier. Set scaling policies that add servers within minutes when CPU or request count crosses a threshold.
- Use a CDN to serve static assets. This absorbs a large portion of read traffic without touching your servers.
- Implement aggressive caching at every layer.
During the spike:
- Shed non-critical load. Disable features that are not essential (personalization, recommendations) to preserve capacity for core functionality.
- Queue non-urgent work (notifications, analytics events) in a message queue instead of processing synchronously.
- Temporarily increase rate limits gracefully — return 429 Too Many Requests instead of letting the system crash.
Database protection:
- Use a circuit breaker pattern to stop sending queries to the database if it is already overwhelmed. Serve cached or degraded responses instead.
4. How Would You Design a System That Needs to Be Available 99.99% of the Time?
99.99% availability means the system can be down for no more than about 52 minutes per year.
Key design principles:
- Eliminate single points of failure: Every critical component must be redundant. Use multiple load balancers, multiple application servers, database replication, and multiple CDN providers.
- Active-active vs. active-passive failover: In active-active mode, all replicas serve traffic simultaneously. If one fails, the others absorb the load. In active-passive, the passive replica takes over only when the active one fails. Active-active offers faster recovery.
- Multi-region deployment: Deploy the system in at least two geographic regions. Use a global load balancer (like AWS Route 53 with latency-based routing) to route users to the nearest healthy region.
- Health checks and automatic failover: Load balancers and DNS should automatically detect unhealthy instances and route traffic away from them.
- Chaos engineering: Regularly run failure simulations (like Netflix's Chaos Monkey) to find hidden dependencies and failure modes before they cause real outages.
- Graceful degradation: When a non-critical service is unavailable, the system should continue to work with reduced functionality rather than failing.
A gaming leaderboard needs to show the top N players by score, update in near real-time, and handle millions of players.
Core approach using Redis Sorted Sets:
Redis sorted sets are a perfect fit for leaderboards. Each player's score is stored as a member of a sorted set. Redis automatically keeps the set ordered by score. You can retrieve the top N players with a single ZREVRANGE command, which runs in O(log N + M) time.
Update flow:
1. The player completes a game and earns points.
2. The game server sends the score update to a leaderboard service.
3. The leaderboard service runs ZADD in Redis to update the player's score.
4. The sorted set is instantly re-ranked.
Persistence: Redis is an in-memory store. Back up the sorted set to a persistent database (like PostgreSQL) periodically for durability.
Global leaderboard at scale: If you have 100 million players, the sorted set can still fit in Redis memory (each entry is roughly 100 bytes = 10GB for 100M players, which is manageable).
Segment leaderboards: Maintain separate sorted sets for daily, weekly, all-time, regional, and friend leaderboards. Refresh time-bound leaderboards on a schedule.
6. How Would You Design a System to Detect Fraud in Real Time?
A fraud detection system needs to evaluate each transaction in milliseconds and flag suspicious activity.
Key components:
- Feature extraction: For each transaction, extract features like transaction amount, location, time of day, device fingerprint, velocity (how many transactions in the last hour), and deviation from typical behavior.
- Rules engine: A fast, deterministic rule engine runs first. Rules like "transaction over $10,000 from a new device in a foreign country" immediately flag the transaction.
- Machine learning model: A pre-trained classification model (gradient boosting or neural network) scores the transaction. The model is retrained regularly on labeled fraud data.
- Real-time stream processing: Use Apache Flink or Kafka Streams to process transactions as a stream and compute rolling features like velocity.
- Decision and action: If the score exceeds a threshold, block the transaction or trigger a step-up authentication (OTP). Log all decisions for audit.
- Feedback loop: When fraud is confirmed or a false positive is reported, feed this back into the training data to improve the model.
7. How Would You Migrate a Monolith to Microservices Without Downtime?
This is a classic real-world scenario that many engineering teams face.
The Strangler Fig Pattern: Rather than rewriting the entire monolith at once, you incrementally extract services while keeping the monolith running.
Step-by-step approach:
1. Identify bounded contexts: Use domain-driven design to identify natural boundaries in the monolith (e.g., user management, orders, payments).
2. Start with the edges: Extract services that have the least dependencies on the rest of the monolith first.
3. Route traffic gradually: Use a proxy (NGINX or an API gateway) in front of the monolith. Gradually route traffic for specific paths to the new microservice.
4. Shared database (temporary): Initially, the new microservice and monolith can share the same database. Gradually migrate the new service to its own database.
5. Use the anti-corruption layer: Build an adapter between the monolith and new services to translate data formats and contracts.
6. Deploy independently: Once a service is fully extracted, it can be deployed, scaled, and updated independently.
7. Repeat: Continue until the monolith is fully decomposed or reduced to a thin shell.
8. How Would You Design a System to Handle Millions of IoT Devices?
An IoT system connects millions of devices (sensors, cameras, smart meters) that continuously send data to a central platform.
Key challenges: High connection count, high write throughput, data ingestion at scale, real-time alerts, and long-term storage.
Architecture:
- Device gateway: A message broker (MQTT protocol) handles persistent connections from millions of devices efficiently. AWS IoT Core or Apache ActiveMQ are common choices. MQTT is lightweight and designed for unreliable networks.
- Ingestion layer: The gateway publishes device messages to Kafka for buffering and fan-out.
- Stream processing: Apache Flink or Spark Streaming processes the raw stream to detect anomalies, compute aggregates, and trigger alerts in real time.
- Time-series database: Store sensor data in a time-series database like InfluxDB or TimescaleDB. These are optimized for high-frequency writes and time-range queries.
- Cold storage: After a retention period, move older data to S3 for long-term storage and batch analytics.
- Device management: A separate service handles device registration, firmware updates, and configuration management.
9. Your Microservices Are Experiencing Cascading Failures. How Do You Fix It?
Cascading failures happen when one service fails and the failure propagates through dependent services, bringing down the whole system.
Root cause: Service A calls Service B. Service B is slow. Service A's threads get stuck waiting for Service B. Eventually, Service A runs out of threads and becomes unresponsive. Service C, which depends on Service A, also fails. And so on.
Solutions:
- Circuit Breaker: Implement a circuit breaker (using libraries like Resilience4j or Hystrix) that monitors calls to a dependency. If failures exceed a threshold, the circuit opens and subsequent calls immediately fail fast (return a cached or default response) instead of waiting. After a timeout, the circuit tries again.
- Timeouts: Always set timeouts on all downstream calls. Never allow a thread to wait indefinitely.
- Bulkhead pattern: Allocate separate thread pools for calls to each downstream service. A failure in one pool does not exhaust threads for other calls.
- Retry with exponential backoff: Retry failed calls with increasing delays to avoid overwhelming a struggling service.
- Graceful degradation: Design each service to return a fallback response (cached data, default value) when its dependencies are unavailable.
A live streaming platform allows users to broadcast live video to thousands or millions of concurrent viewers.
Ingestion:
- Streamers send video to an ingest server using RTMP protocol.
- The ingest server transcodes the raw video stream into multiple resolutions and bitrates (1080p, 720p, 480p, 360p) using encoding clusters (FFmpeg at scale).
Delivery:
- Transcoded segments are pushed to a CDN in HLS or DASH format. HLS breaks the video into short segments (2-6 seconds) that can be independently cached and delivered.
- Viewers receive segments from the nearest CDN edge node.
Latency:
- Standard HLS has 10-30 seconds of latency. For interactive live streams (gaming, auctions), Low-Latency HLS (LL-HLS) or WebRTC reduces this to 1-3 seconds.
Chat and interaction:
- Real-time chat uses WebSockets. A pub/sub system (Redis pub/sub or Kafka) fans out chat messages to all viewers of a stream.
Recording: Live streams are simultaneously written to object storage (S3) for on-demand playback after the stream ends.
Scale: Popular streams can have millions of concurrent viewers. The CDN layer handles this. The origin servers (ingest + transcoding) only process the single source stream.
Wrap Up
System design interviews reward engineers who think clearly, communicate well, and understand how real systems work at scale. The 40 questions and answers in this guide cover everything from fundamental concepts like caching and load balancing to advanced topics like distributed rate limiting, cascading failure recovery, and live video streaming architecture.
The key to doing well in a system design interview is not memorizing answers. It is building a mental model of how large systems work and practicing how to reason through trade-offs under constraints.
FAQs
1. How much detail should you go into during a system design interview?
When interviewing for a system design role you want to balance between giving enough high level architectural details and enough detail in the area that is most critical to your solution. You are also encouraged to leave out any unnecessary details until requested for clarification. When describing your/or architecture, explain the reasoning behind your design decisions and the trade-offs of those decisions.
2. What mistakes should you avoid in system design interviews?
Avoid jumping into solutions without clarifying requirements, ignoring scalability, overlooking edge cases, and failing to communicate your reasoning clearly throughout the design process.
3. How do you handle uncertainty during system design discussions?
When you are unsure of what to say or do during the system design interview discussion, it is very important to ask clarifying questions. Clearly state any assumptions that you are making and continue with a logical progression. The majority of interviewers prefer structured thought process and be flexible rather than having a perfect answer.