You have trained a machine learning model. It looks great on paper. The accuracy is 95%. You are ready to deploy it. But then it fails in production. It misses the very cases you built it for.
This happens more often than you think. In most cases, a confusion matrix could have caught the problem before deployment.
A confusion matrix is one of the most important tools in machine learning. It tells you not just how often your model is right, but exactly where and how it goes wrong. If you work with classification models, understanding the confusion matrix is non-negotiable.
In this guide, you will learn what a confusion matrix is, how it works, how to read it, and how to use it to build better models. We will also walk through a Python implementation and cover real-world applications.
Let us get started!
Also Read: CatBoost in Machine Learning
A confusion matrix is a performance evaluation table for machine learning classification models. It compares a model's predicted categories against the actual, true categories of a dataset. Rather than summarizing performance in a single percentage, it reveals exactly where the model makes mistakes and how it confuses classes.
Imagine you have built an email classification model that predicts whether an email is Spam or Not Spam.
You test the model on 100 emails and get the following results:
| Predicted Spam | Predicted Not Spam | |
|---|---|---|
| Actual Spam | 40 | 10 |
| Actual Not Spam | 5 | 45 |
In this example:
This confusion matrix not only shows the number of correct predictions but also the specific types of errors the model made. Instead of relying solely on an overall accuracy score, you can see whether the model is more likely to miss spam emails or incorrectly flag legitimate emails as spam.
A confusion matrix is important because it provides a detailed view of how a classification model performs. Unlike accuracy, which only shows the percentage of correct predictions, a confusion matrix reveals the exact types of errors a model makes. Comparing predicted labels with actual labels, it helps identify:
A confusion matrix is particularly valuable when working with imbalanced datasets, where one class appears much more frequently than others. In such cases, a model may achieve high accuracy while still performing poorly on the minority class. The confusion matrix exposes these hidden issues.
Additionally, it serves as the foundation for several important evaluation metrics, including:
By analyzing these metrics, data scientists can better understand model strengths and weaknesses, improve classification performance, and make more informed decisions about model selection and optimization.
Related Article: LightGBM (Light Gradient Boosting Machine)
Before you can read a confusion matrix correctly, you need to understand how it is built. The layout follows a consistent pattern that every data scientist uses across projects and tools.
A standard binary confusion matrix has four cells arranged in a 2x2 grid. Each cell represents a specific combination of predicted and actual outcomes.
Here is the standard layout:
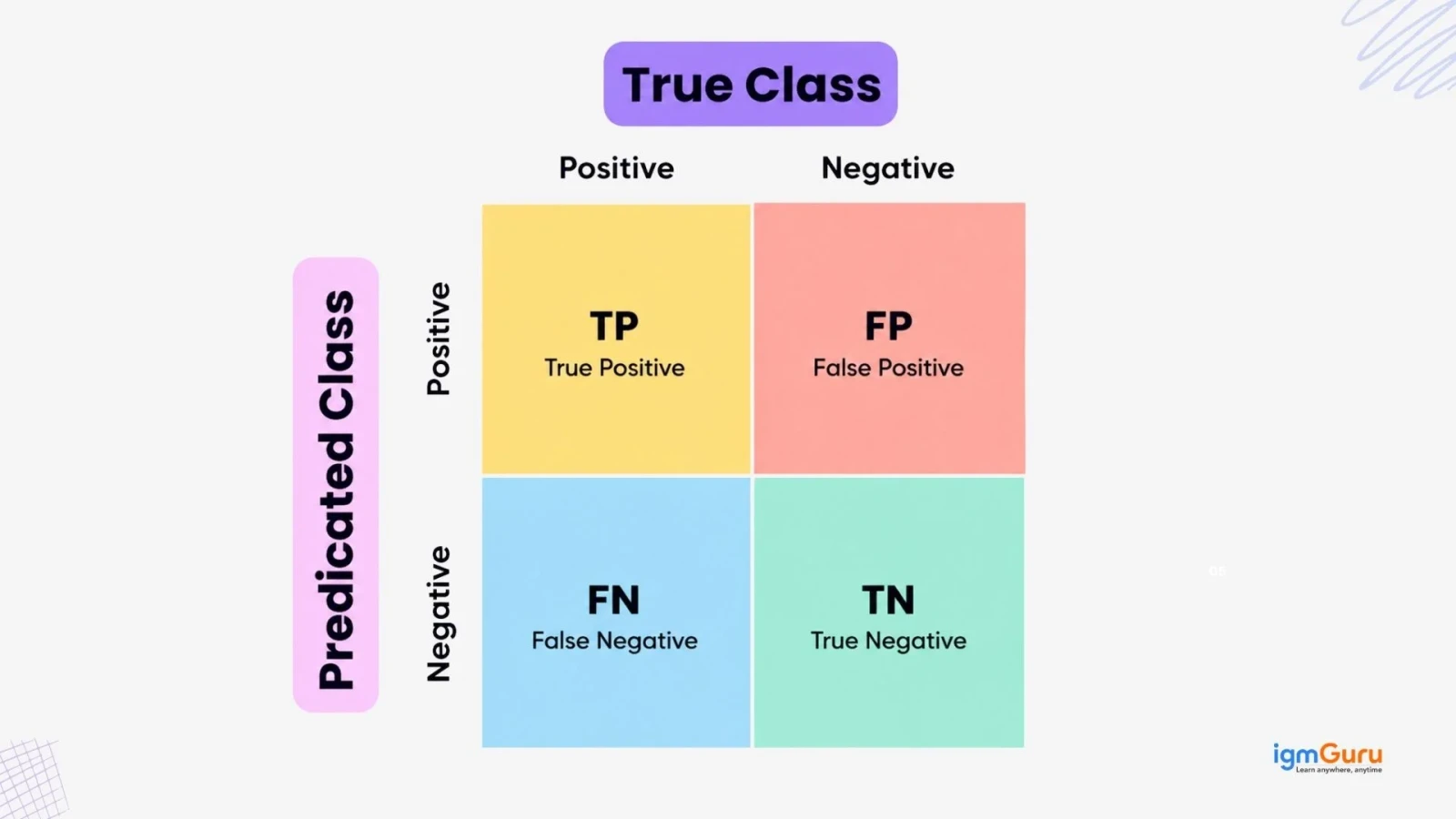
Each cell in the confusion matrix has a specific name and meaning. These four components are the building blocks of every evaluation metric you will use. Understanding them clearly will make the rest of this guide much easier to follow.
The model predicted positive, and the actual label is also positive. This is a correct prediction. In the spam example, this means the model correctly identified a spam email as spam.
The model predicted negative, and the actual label is also negative. This is also a correct prediction. The model correctly identified a legitimate email as not spam.
The model predicted positive, but the actual label is negative. This is a wrong prediction. The model flagged a legitimate email as spam. This is also called a Type I error.
The model predicted negative, but the actual label is positive. This is also a wrong prediction. The model missed a real spam email and let it through. This is also called a Type II error.
Understanding these four values is the foundation of everything else. All the metrics you calculate later come directly from these four numbers.
Read Also: How to Install TensorFlow: A Step-by-step Guide For Beginners
Having the confusion matrix in front of you is just the first step. Knowing how to read it correctly is what gives you actionable insight. Here is a simple approach you can use every time.
Reading a confusion matrix becomes straightforward once you know what to look for.
In a correctly structured confusion matrix, the diagonal from top-left to bottom-right contains the correct predictions. Higher numbers on the diagonal mean better model performance.
These are the errors. Large off-diagonal numbers tell you the model is regularly confusing one class with another.
Each row represents an actual class. The row total tells you how many samples belong to that class. If one class has far more samples than another, you are dealing with a class imbalance.
A false negative in a cancer detection model is far more dangerous than a false positive. A confusion matrix helps you think about the real-world cost of each error type.
Most beginners start with accuracy because it feels simple and intuitive. But accuracy can give you a false sense of confidence, especially when your dataset is not balanced. This section shows you exactly why that happens.
Accuracy measures the total number of correct classifications divided by the total number of cases.
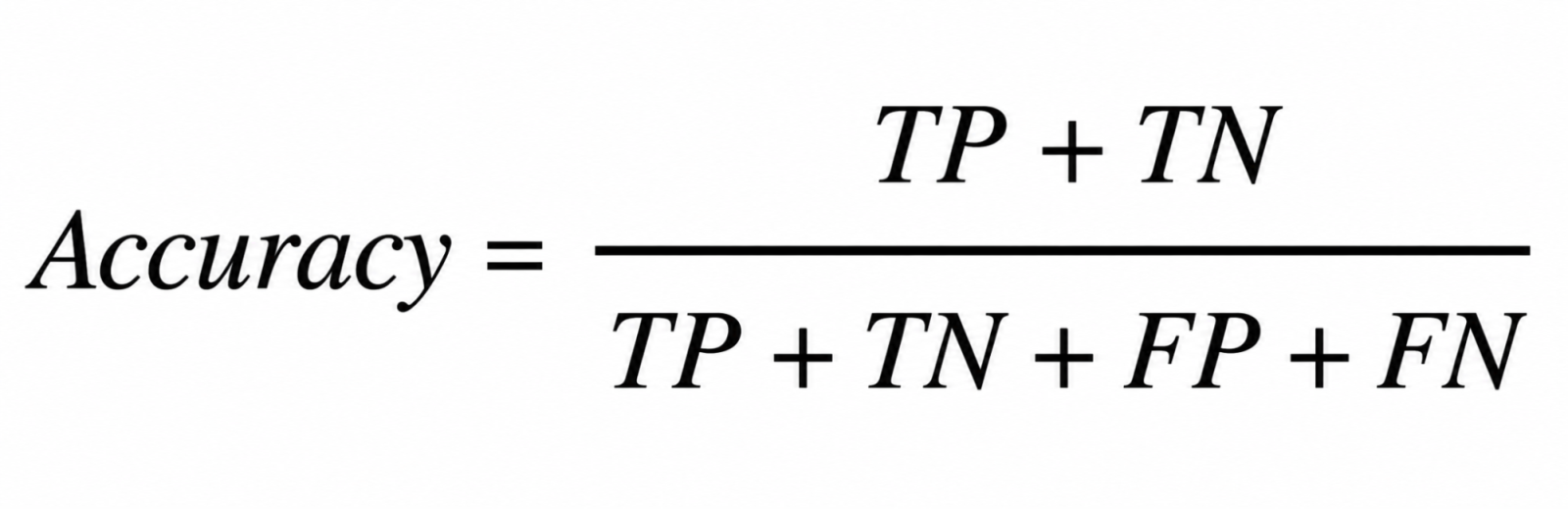
This seems reasonable. But it only tells you the percentage of correct predictions overall.
Consider a fraud detection system. Out of 10,000 transactions, 9,900 are legitimate and 100 are fraudulent. A model that predicts "Not Fraud" for everything achieves 99% accuracy. But it catches zero fraud cases.
This is the accuracy paradox. It is especially common in medical diagnosis, fraud detection, and other high-stakes applications where the minority class is the one that matters most.
The confusion matrix gives you the full picture. It shows you exactly how the model performs on each class separately.
Read Also: What Is PyTorch?
The confusion matrix does not just show you errors. It also unlocks a set of powerful metrics that give you a much deeper view of model performance. Each metric measures something different, and knowing when to use each one is a key skill for any machine learning practitioner.
The four components of a confusion matrix feed directly into these key evaluation metrics.
Precision indicates the proportion of positive predictions made by a model that are accurate.
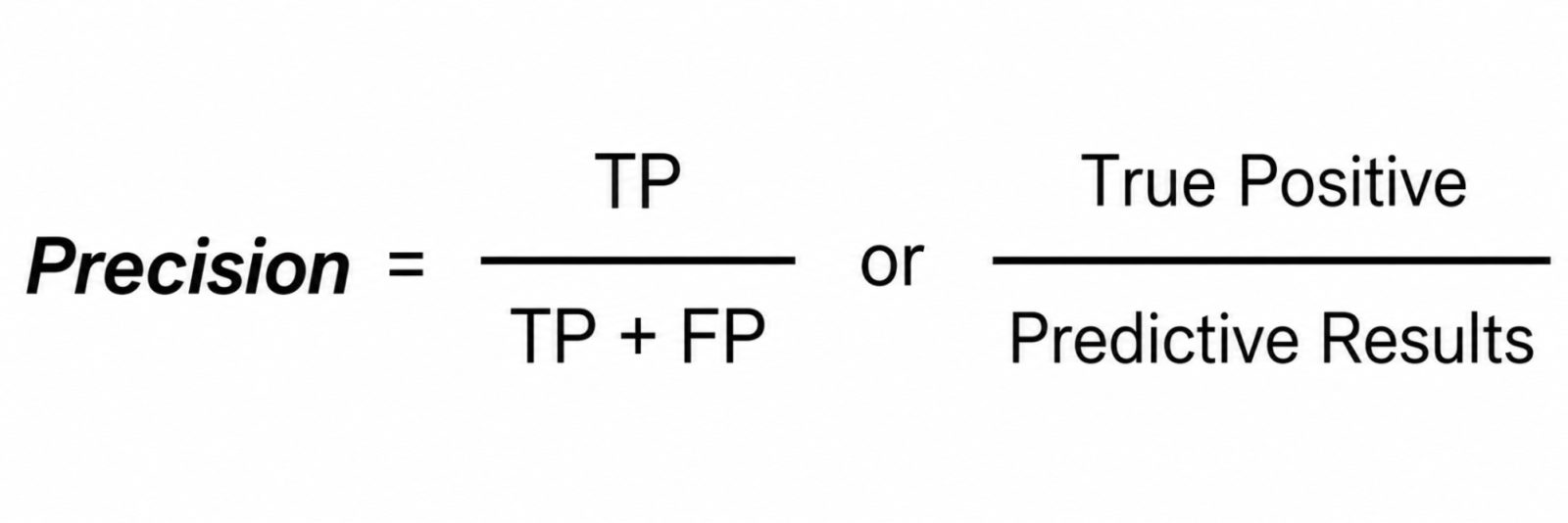
High precision means fewer false positives. This matters when false alarms are costly. For example, you do not want a spam filter that marks important emails as spam too often.
Recall measures how many of the actual positive cases the model correctly identified.
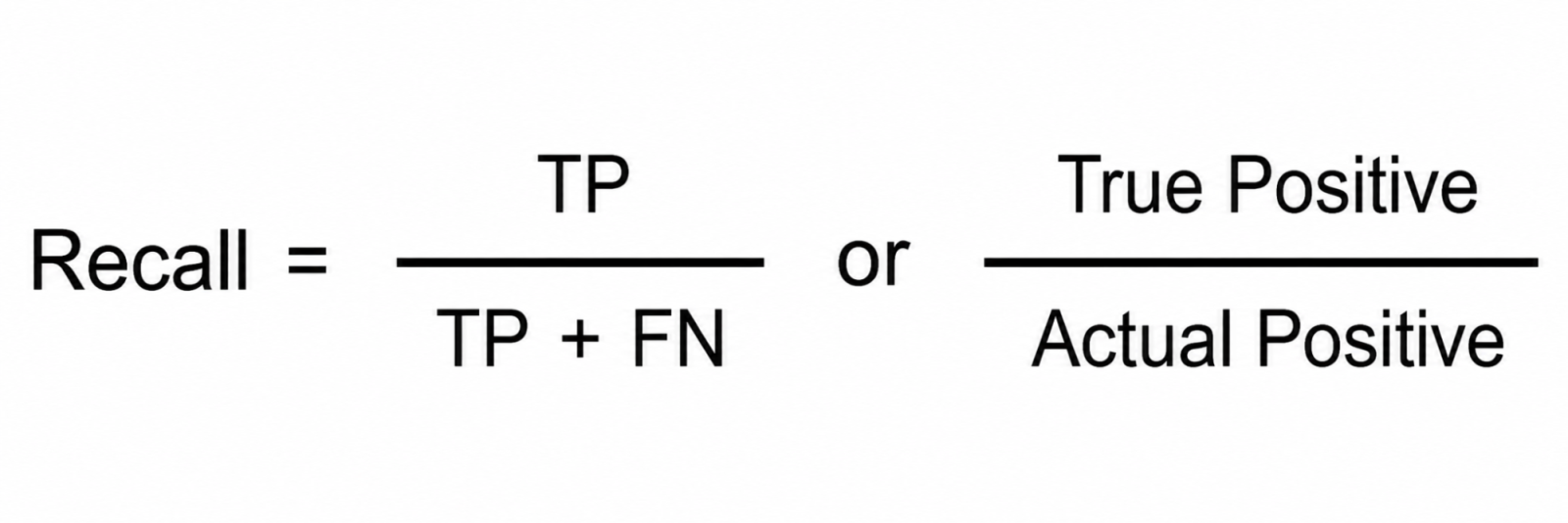
High recall means fewer missed positives. This matters when missing a positive case is dangerous. In cancer screening, missing a true cancer case is far worse than a false alarm.
The F1-score is the harmonic mean of precision and recall. It balances both metrics in a single number.
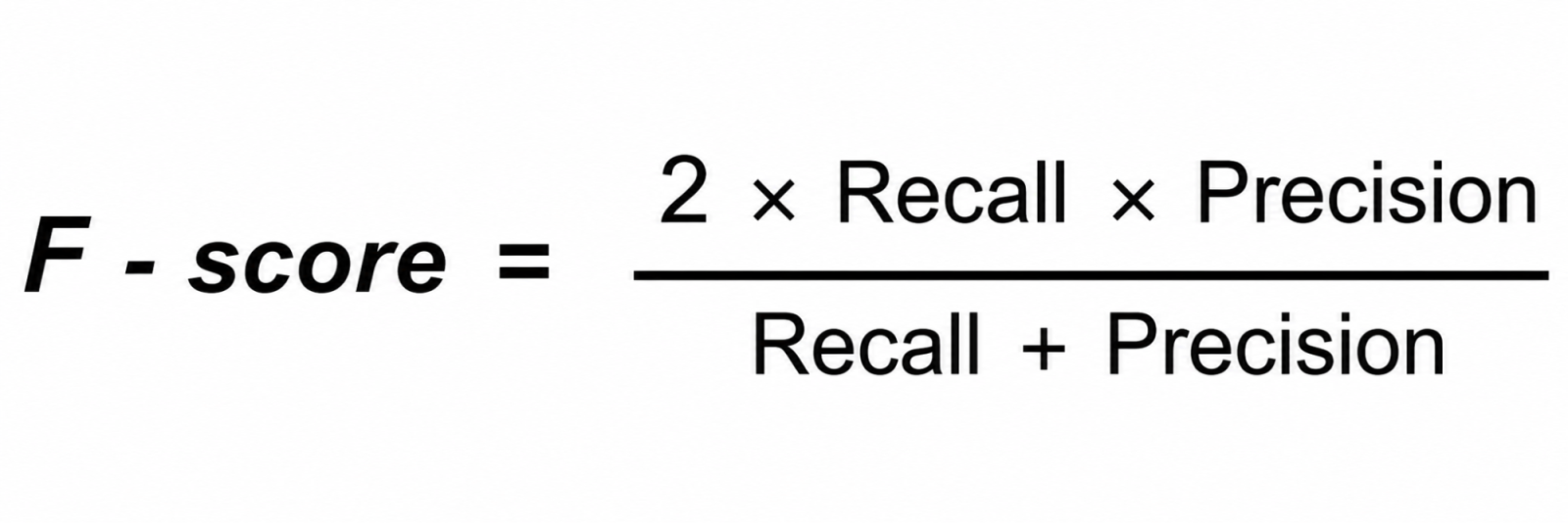
The F1-score is especially useful when you need to balance precision and recall and when the dataset is imbalanced.
Related Article: What Is Machine Learning Operations?
Specificity measures how well the model identifies negative cases.
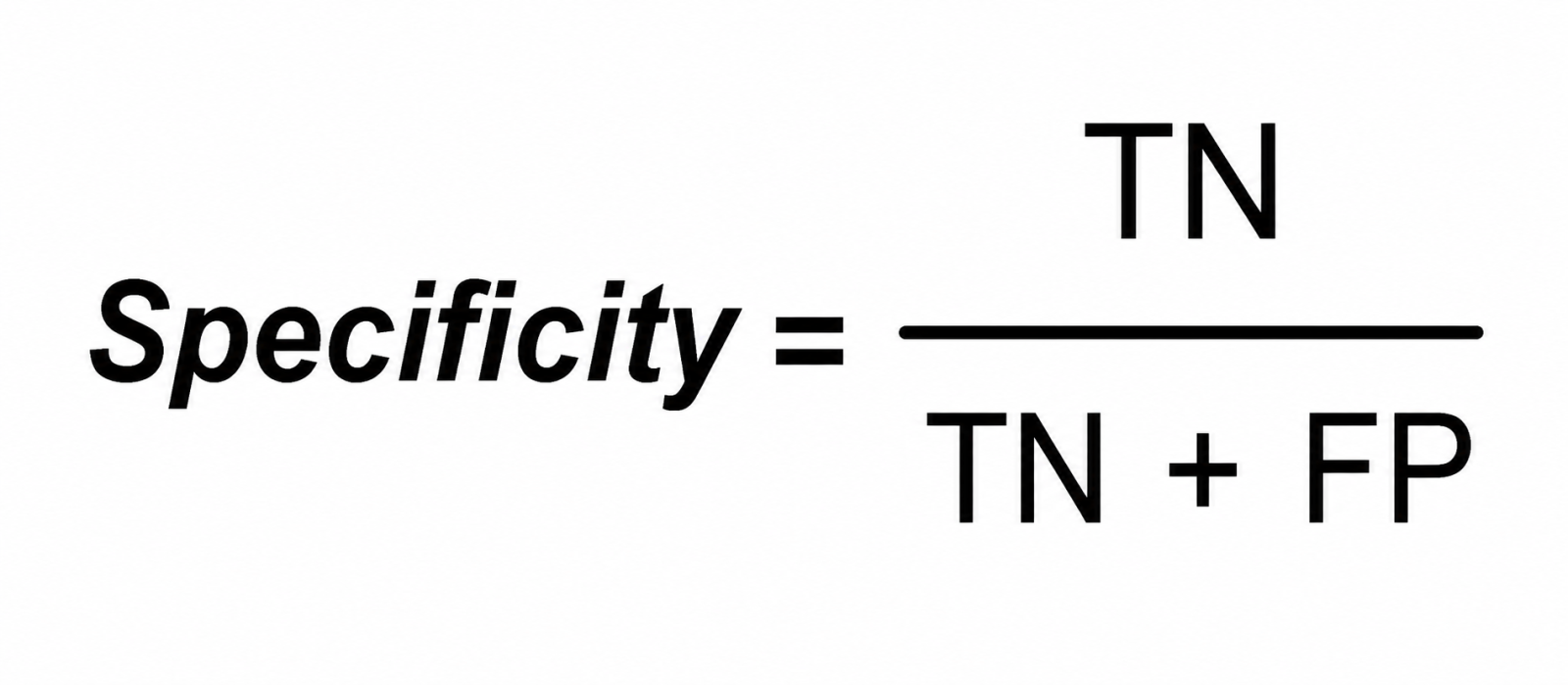
High specificity means fewer false positives. This is important in scenarios where flagging a negative case as positive carries a significant cost.
The right metric depends on your use case:
Also Read: What is MLOps (Machine Learning Operations)?
Binary classification is just one use case. Many real-world problems involve three or more classes, and the confusion matrix handles them just as well. The structure scales up naturally, though reading it does require a bit more attention.
So far, we have focused on binary classification with two classes. But confusion matrices also work for multiclass problems.
In a multiclass confusion matrix, the rows represent actual classes and the columns represent predicted classes. The size of the matrix grows with the number of classes. For a 3-class problem, you get a 3×3 matrix. For a 10-class problem, you get a 10×10 matrix.
Suppose you are building a model to classify animals into three categories: Cat, Dog, and Bird. You test on 30 samples and get this result:
| Predicted Cat | Predicted Dog | Predicted Bird | |
|---|---|---|---|
| Actual Cat | 8 | 2 | 0 |
| Actual Dog | 1 | 9 | 0 |
| Actual Bird | 0 | 1 | 9 |
The diagonal shows correct predictions. Off-diagonal values show confusion between classes. Here, the model sometimes confuses cats with dogs and dogs with birds, but never confuses cats with birds.
For multiclass problems, you calculate precision, recall, and F1-score for each class separately. Then you average them using:
Theory is important, but seeing it in code makes everything click. Python's scikit-learn library makes it very easy to generate and visualize a confusion matrix in just a few lines. Follow these steps and you will have a working implementation in minutes.
Python makes it easy to create a confusion matrix using scikit-learn. Here is a step-by-step example.
|
|
|
|
|
|
This report gives you precision, recall, F1-score, and support for each class in one output. It is the fastest way to evaluate a classification model in Python.
Read Also: Top Machine Learning Algorithms to Know
The confusion matrix is a powerful tool, but it works best when you understand how it fits alongside other evaluation metrics. Each metric has a purpose, and knowing which one to use in a given situation will make you a stronger practitioner.
The confusion matrix is not the only evaluation tool. Here is how it compares to others.
| Metric | What It Shows | Best For |
|---|---|---|
| Confusion Matrix | Full breakdown of predictions vs actuals | Diagnosing specific error types |
| Accuracy | Overall percentage correct | Balanced datasets only |
| Precision | Correctness of positive predictions | When false positives are costly |
| Recall | Coverage of actual positives | When false negatives are costly |
| F1-Score | Balance of precision and recall | Imbalanced datasets |
| ROC-AUC | Model performance across thresholds | Comparing multiple models |
| Log Loss | Confidence of predictions | Probabilistic classifiers |
The confusion matrix sits at the top of this list because most other metrics are derived from it. You should always start with the confusion matrix before moving to other metrics.
Understanding a concept in theory is one thing. Seeing where it gets used in the real world makes it stick. Confusion matrices are not just a classroom tool. They drive decisions in some of the most critical machine learning systems in use today.
Confusion matrices are used across industries wherever classification models exist.
In disease detection, a false negative can be life-threatening. Missing a cancer diagnosis is far worse than a false alarm. Doctors and data scientists use confusion matrices to evaluate recall and minimize false negatives.
Spam filters need to balance two risks. Missing spam is annoying. Blocking legitimate email is worse. The confusion matrix helps tune the model to find the right balance.
Banks and payment companies use confusion matrices to evaluate fraud detection models. The fraud class is a tiny minority, so accuracy is meaningless. The confusion matrix reveals how well the model catches actual fraud without blocking legitimate transactions.
Object recognition models in autonomous vehicles must correctly classify pedestrians, vehicles, and road signs. A confusion between a pedestrian and a road sign could be fatal. Confusion matrices help engineers identify and fix these classification errors.
Customer service teams use sentiment classifiers to tag reviews and tickets as positive, negative, or neutral. Confusion matrices help identify which sentiments the model handles well and which it consistently misclassifies.
Related Article: What is Natural Language Processing (NLP)?
There are many ways to evaluate a machine learning model. So why does the confusion matrix stand out? Because it gives you information that no other single tool provides. Here are the key advantages that make it a staple of every model evaluation workflow.
A confusion matrix offers several advantages over other evaluation approaches.
The confusion matrix is a great tool, but it is not a complete solution on its own. Like any evaluation method, it has blind spots. Knowing these limitations will help you use it more responsibly and pair it with the right complementary tools.
No tool is perfect. The confusion matrix has a few limitations you should know about.
Also Read: What is Hyperparameter Tuning?
Knowing what a confusion matrix is and knowing how to use it correctly are two different things. Several common errors can lead you to wrong conclusions. Being aware of them upfront will save you a lot of troubleshooting later.
Even experienced practitioners make these mistakes. Here is what to watch out for.
Avoiding mistakes is a good start. But using the confusion matrix well means going a step further and building good habits around how you apply it. These best practices will help you get reliable, repeatable results every time.
Follow these practices to get the most value from your confusion matrix.
Related Article: Deep Learning vs Machine Learning: Beginner's Guide
The confusion matrix is one of the most powerful and practical tools in machine learning evaluation. It gives you a clear, honest breakdown of how your classification model performs on every class, not just overall.
You now know what a confusion matrix is, how to read it, and how to build one in Python. You also know the four core components, the derived metrics that come from them, and how to apply all of this to real-world problems.
Next time you evaluate a classification model, start with the confusion matrix. Use it to guide your decisions about model selection, threshold tuning, and performance improvement.
Good models are not just accurate. They fail in the right places for the right reasons. The confusion matrix helps you confirm that.
Precision measures how many of the model's positive predictions are actually correct. Recall measures how many of the actual positive cases the model successfully identified. Precision focuses on false positives. Recall focuses on false negatives.
Use the F1-score when your dataset is imbalanced, meaning one class appears far more often than the other. Accuracy can be misleading in these type of situations. The F1-score balances precision and recall and gives a fairer picture of model performance.
A normalized confusion matrix divides each cell by the total number of actual samples in that class. This converts raw counts into percentages, making it easier to compare performance across classes with different sample sizes.
A good confusion matrix has high values along the main diagonal and low values everywhere else. This means the model makes correct predictions for most samples in every class with few misclassifications.