Generative Adversarial Networks (GANs) are a deep learning (DL) architecture used to generate new and realistic data. It consists of two neural networks including generator and discriminator that compete with each other to give the best output. Do you know how? Continue to read this article and learn what are GANs, their types, working and more.
This article is curated by experienced industry experts as your guide to learn everything about Generative Adversarial Networks. It also explains its architecture, use cases and many more things. Let’s begin with understanding the definition of GANs.
GANs is an architecture used in machine learning models and deep learning models for generating realistic data. GANs are the core of deep learning, a subcategory of machine learning which has the ability to recognize complicated patterns in different data types like images, text and sounds.
You may have heard of neural networks, which are designed to imitate the structure and function of a human brain. It is a kind of neural network that consists of two elements: generator and discriminator. The two elements then interact with each other to create new images, sounds and text. This capability has made it a popular technology among various industries.
It has various types, which raises the question which one should be used when? To understand it you have to explore the types of Generative Adversarial Networks.

All GANs have the basic generator-discriminator adversarial training framework, especially for modifications leading to special types. Let us read a couple of examples of different kinds of GANs.
These focus on image-to-image translations. The training data set has two unpaired sets of data/groups of images without labels or correspondences. CycleGAN makes use of the information to learn how to change images from one set into images which could pass for belonging to the other set. For instance, you gave a CycleGAN two kinds of images: one showing dogs and one depicting tigers. The result may look like a realistic picture of a dog with stripes of a tiger or the inverse.
These are trained to increase image resolution through filling in details to blurry areas of a picture. SRGANs fulfill this through perceptual loss function, a technique which measures the difference between high-level perceptual features of two images. It allows a low-resolution image to be upscaled to a high-resolution image.
It is the easiest kind of GAN which has a generator and a discriminator which are both built through multi-layer perceptrons (MLPs). It makes use of its mathematical formulation through stochastic gradient descent (SGD).
CGAN adds an additional conditional parameter to lead the generation procedure. In spite of generating data randomly they let the model produce a particular kind of output. It makes sure that the generator makes data corresponding to the condition given, like creating images of particular objects.
This falls among the most famous kinds of GANs used for image generation. DCGAN is essential because it uses CNNs instead of simple multi-layer perceptrons (MLPs). It has max pooling layers which are replaced with convolutional stride helping in making the model more efficient. DCGAN has completely connected layers removed which helps in better spatial understanding of images. These are successful because they create high-quality realistic images.
This is made for generating ultra-high quality images through a multi-resolution approach. LAPGAN makes use of multiple generator-discriminator pairs at different levels of the Laplacian pyramid. Due to its ability to make highly thorough images, this technology is calculated as an important approach for photorealistic image creation.
Style Generative Adversarial Network is an AI architecture that can generate ultra-realistic images. It has precise control over various image features like separating style from content to allow manipulation. It builds upon previous GAN models by introducing a new generator architecture and a progressive growing technique. This enables the creation of high-quality and customizable images including photorealistic faces.
Read Also- Generative AI Tutorial
Generative Adversarial networks are used in many places in image generation like image synthesis and generation, image-to-image translation, text-to-image synthesis and more. Let us get an in-depth understanding on where to use generative adversarial networks.
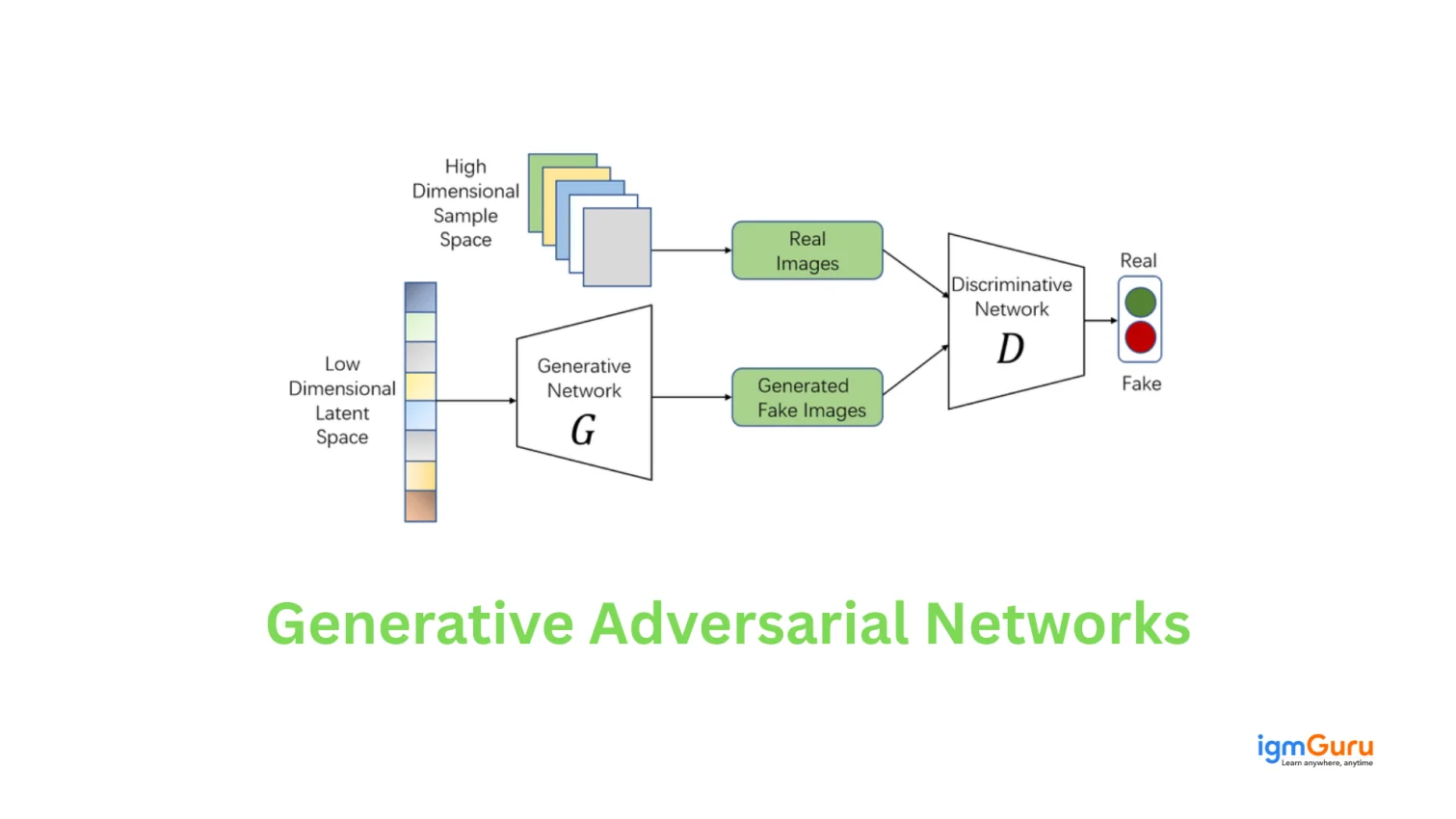
We were discussing the two neural networks of GANs through the article. Those are also the components of Generative Adversarial Networks architecture. It has total three components which are:
Generator is a type of deep neural network (DNN). It generates data samples like images or text using noises as input. It uses backpropagation to adjust its internal parameters during training to learn the underlying data patterns. Then it produces samples for discriminators. It uses a loss function to minimize the loss.
| JG = − (1/m) Σi=1m log D(G(zi)) |
Think of a discriminator as a binary classifier. It helps in understanding the difference between real and generated data. It continuously refines its parameters to learn and improve its classification ability. It uses convolutional layers or relevant architectures to deal with images. This helps to extract features and improve the model’s capability. It also uses a loss function:
| JD = − (1/m) Σi=1m log D(xi) − (1/m) Σi=1m log (1 − D(G(zi))) |
MinMax Loss is the component here GANs are GANs are trained using a MinMax between the generator and discriminator. This generator tries to minimize this loss whereas the discriminator tries to maximize it, and it detects fakes perfectly. The MinMax Loss function is:
| minG maxD V(G, D) = [ Ex ∼ pdata [log D(x)] + Ez ∼ pz(z) [log (1 − D(G(z)))] ] |
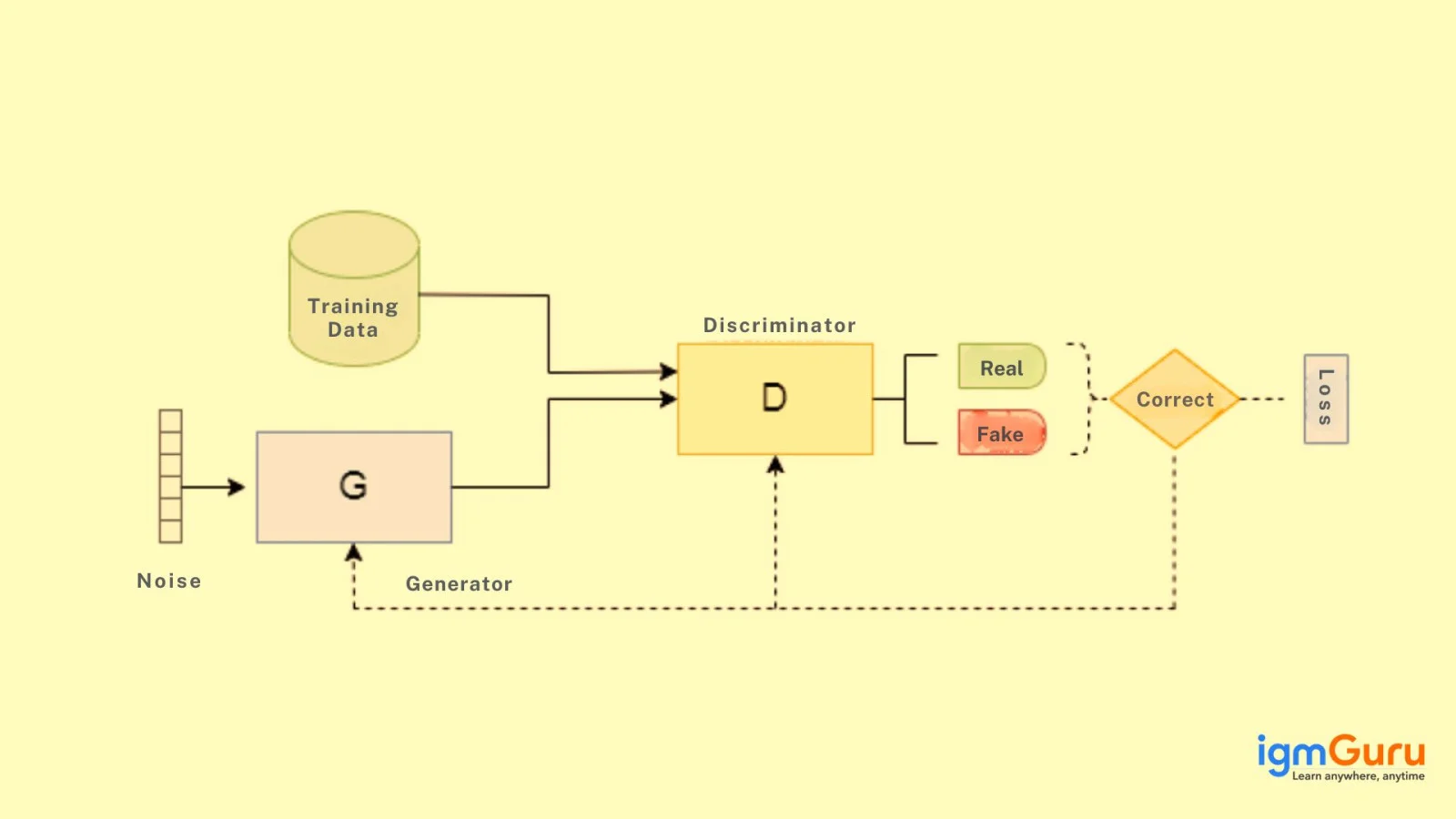
As we read GAN train by having two networks the Generator (G) and the Discriminator (D) compete and enhance altogether. So how do generative adversarial networks work? Let us dig into its process.
This generator begins with a random noise vector like random numbers. Generator makes use of this noise as a starting point to make fake data samples like a generated image. It's internal layers change this noise into something that looks like real data.
It gets two kinds of data -
The discriminator's work is to analyze every input and find whether it is real data or something the generator made up. It results in a probability score between 0 and 1. Score of 1 represents the data which is likely real and 0 recommends that it is fake.
If the discriminator differentiates real and fake data correctly, it gets better at its job. And if the generator fools the discriminator by making realistic fake data then it gets a positive update and the discriminator gets a penalty for making the wrong decision.
Every time the discriminator makes a mistake in fake data for real, then the generator learns from this achievement. With many iterations, the generator enhances and develops more convincing fake samples.
The D learns continuously amongst updating itself to spot fake data in a better way. This continuous back-and-forth makes both the networks powerful with time.
As the training keeps going on, the generator becomes highly skilled at making realistic data. By then the discriminator struggles to differentiate between real from fake shows that the GAN has reached a disciplined state. At this very moment, the generator can make high-quality synthetic data which can be taken in use for multiple applications.
Read Also- Generative AI Interview Questions
There are many benefits of using Generative Adversarial networks like high quality results, unsupervised learning, synthetic data generation and more. Let us get an in-depth understanding on the benefits of using GANs.
They produce new, synthetic data which resembles real data distribution and creative tasks.
GANs don't need the help of labelled data in making them effective in situations where labeling is expensive or tough.
GANs can make photorealistic images, music, videos and other media with high quality.
These can be implemented all over multiple tasks involving image synthesis, text-to-image generation, style transfer, detecting abnormalities and more.
Implementing these is among the most critical developments in deep learning. It is a fundamental technology which can be used to train networks in doing all kinds of things, from making 3D models from 2D images to creating images which are based on text descriptions.
Read Also- Generative AI Roadmap
After traditional applications, GANs are now being taken in use in multiple advanced fields. Fields like security, privacy preserving applications, cyber threat detection and more. Below is a brief explanation on the use cases of GANs.
They assist in mitigating adversarial attacks on deep learning systems. Through generating fake data and training models to identify them GANs give power to the security of AI models specifically in cybersecurity.
These are being discovered for data encryption in sectors like defense and military. In a competitive field, through GANs they can generate and crack encryption codes providing a new approach to data security.
Organizations like healthcare, where data is limited, these are used to create realistic datasets. It is important for training AI models when there is less data for traditional approaches.
They also allow pseudo style transfer and permit modifications to particular features in an image. Like, they can adjust the eyes in a picture. This technique is also put to use in fields such as natural language processing and speech processing.
As we read, GANs are transforming and shaping the future of artificial intelligence. The technology is improving day by day, we can expect even more innovative applications which are going to transform how we develop, work and interact with digital content.
This technology is the first and greatest feature in their learning technology and that is why they prefer to follow strong unsupervised learning. This is one of the reasons why they do not need any labelled data.
Gallium Nitride (GaN) is a pretty tough, mechanically stable, binary III/V direct bandgap semiconductor.
Absolutely, they are used in NLPs for tasks like text generation, paraphrasing and language translation.
GANs generate new data using two competing models, while adversarial neural networks focus on making models robust or fair by resisting adversarial influence.
GANs are difficult to train and often unstable. They can suffer from issues like mode collapse and may produce biased or unrealistic results.