Retrieval-Augmented Generation (RAG) integrates large language models (LLMs) and retrieval systems together to roll in related external information in the process of text generation. It has recently gained a lot of attention and has become a common topic in interviews for different roles. Professionals such as AI engineers, prompt engineers, data scientists and Machine Learning engineers benefit from these top RAG interview questions and answers.
RAG is the most in-demand and career-oriented skill today. Professionals with top skills like Data Science and Generative AI are showing their interest in learning RAG for multiple reasons. These RAG interview questions with answers have been created by industry experts to help you prepare and clear interview rounds in a one go.
Explore igmGuru's Machine Learning and AI Certification Courses to build your career in AI and ML.
The first step is to go through the basic RAG interview questions. These are basic level questions that are often asked by interviewer.
It is an AI framework used to improve the capabilities of Large Language Models (LLMs). It does so by integrating an information retrieval system. Its unique approach allows it to access and incorporate relevant information from external databases. This means there is no need of relying solely on the available knowledge of the LLMs. it leads to more accurate, up-to-date and contextually relevant text generation.
The retriever fetches relevant documents or data from a knowledge base based on the input query to provide context for the generator in a RAG system.
This system has two central components namely the retriever and the generator. The retriever explores and collects associated info from external sources like documents, websites or databases. The generator is an advanced language model that uses this info to create accurate and clear text.
The system gets the most updated information because of the retriever. This information is combined with the existing knowledge to produce better answers by the generator. Together they present highly accurate responses.
These systems gather information from structured as well as unstructured external sources. Structured sources encompass APIs, knowledge graphs and databases where the data is highly organized and easy to search. Unstructured sources encompass gigantic text collections like websites, archives or documents. The information here has to be processed by using natural language understanding.
The system stays limited to its trained-on data if one relies only on an LLM's built-in knowledge. This knowledge could lack details or even be outdated. RAG systems are a more advantageous option as fresh information is pulled in from external sources for more timely and accurate responses.
This approach reduces hallucinations which are errors wherein the model makes up facts. This mostly happens because the answers are reliant only on real data. Retrieval augmented generation benefits specific fields like medicine, tech and law where updated and specialized knowledge is needed.
Its retrieval component searches through the current data sources to identify pertinent information according to the input question. These data sources could be knowledge bases or document corpora. The retrieval component searches and extracts data points or documents containing related information by using different retrieval approaches. Common approaches include semantic search and keyword matching.
The relevant retrieved data is received by the generative model and used to elicit a response. The retrieval component exponentially increases the accuracy and context awareness of the system by making external knowledge highly accessible.
Evaluating these systems includes looking at the retrieval as well as generation components.
The accuracy and relevance of the retrieved documents are assessed for the retriever. Metrics like recall (the number of the total relevant documents found) and precision (the number of relevant retrieved documents) can be used here.
Metrics like ROUGE and BLEU can be used for comparing the generated text with human-written examples to understand the quality of the generator.
Modern RAG evaluation also uses frameworks such as RAGAS which measure faithfulness, context relevance, and answer correctness. These metrics help evaluate how well the generated response aligns with retrieved information.
Prompt engineering plays a major role in this technology. It provides precise instructions to guide the large language model for data retrieval. The relevance and clarity of the output from this approach will only depend on the prompt. Here is a retrieval-augmented generation data flow -
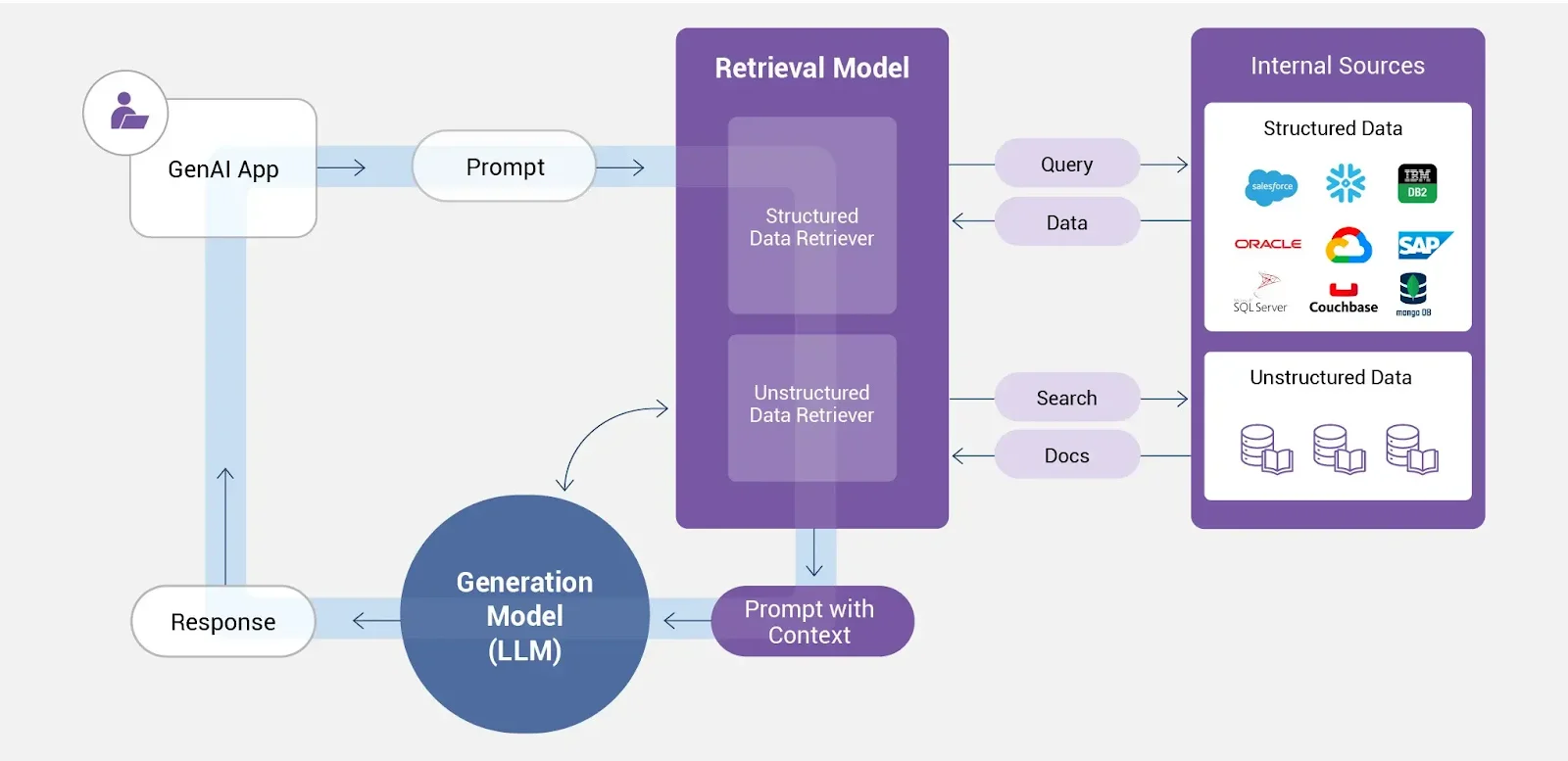
This flow diagram explains how prompt engineering improves the data retrieval process. This process involves 4 stages, in which -
Related Article- RAG Tutorial For Beginners
Here are some intermediate RAG interview questions that look at concepts in a deeper sense.
Hybrid search amalgamates the strengths of sparse and dense retrieval methods. One can begin with a sparse method (like BM25) for quickly finding documents according to the keywords. A dense retrieval model using embeddings (such as Sentence Transformers, OpenAI embeddings, or BGE models) can then re-rank the documents based on semantic similarity and contextual understanding. This hybrid approach gives the sparse search speed with the dense methods' accuracy.
This system mitigates misinformation and bias by using a two-step approach encompassing retrieval-based methods and generative models. The retrieval components are configured for prioritizing authoritative and credible sources when retrieving information from knowledge bases or document corpora. The generative model can be trained for cross-reference and validating the retrieved information prior to response generation.
Biased or inaccurate information propagation is reduced with this approach. More accurate and reliable responses are offered by including validation mechanisms and external knowledge sources.
Developers integrate RAG into the current ML pipelines by using it as a component important for handling NLP tasks. The retrieval component of this system is connected to a document corpus or database where it looks for associated information according to the input query.
The generative model subsequently processes the extracted information to generate a response. This unprecedented integration lets RAG use the existing data infrastructure and sources for easily incorporating into different machine learning systems and pipelines.
The main benefits of retrieval augmented generation usage over other NLP techniques are -
Some common challenges this technology resolves in natural language processing are -
In modern AI systems, RAG models are usually not trained from scratch. Instead, developers combine pre-trained LLMs with retrieval systems and vector databases. Training may only be required for improving the retriever or adapting the system to a specific domain.
Related Article- Top Prompt Engineer Skills You Can't Miss
These advanced RAG interview questions are a great learning point for seasoned professionals. The top RAG interview questions for a knowledgeable expert are going to include high-level topics.
Both of these are two separate approaches in natural language processing and have different outlooks.
RAG fuses generative models and retrieval-based techniques together to improve natural language processing problems. A retriever component is used for obtaining pertinent data which is then applied to a generative model for producing replies.
PEFT is the acronym for Parameter-Efficient Fine-Tuning and reduces the needed computing parameters and resources. It does so by fine-tuning and optimizing pre-trained language models to increase their performance on certain tasks. Information distillation, quantization and pruning are strategies for achieving superior performance with fewer parameters.
Contextualization here means guaranteeing that the information from the response is relevant to the query of the user. The system produces more relevant and better answers by matching the retrieved data with the query. The chances of irrelevant or incorrect results are very low for the output to fit the user's needs. Using an LLM to check whether the retrieved documents are relevant prior to sharing with the generative model is one approach.
Common limitations of this technology are -
Information acquired from previous encounters or within the present discussion is used for retaining the context in a discourse. The retriever component gives the generative model access to the context for producing contextually and coherent appropriate replies by constantly seeking and retrieving pertinent data according to the existing conversation. This iterative process makes interactions more exciting and organic by comprehending and adapting to the discussion's changing context.
Knowledge graphs give efficient and accurate information retrieval and reasoning through organized knowledge representations and connections between things. These are a part of RAG's retriever component for improving search capabilities by using the graph structure for traversing and retrieving pertinent information. Knowledge graphs are used by this system for recording and using semantic links between things and ideas for contextually rich answers to user inquiries.
The smaller chunks are fast and cheap to process, but they might lead to misinterpretation of information. It is because they might not have the complete context. Larger chunks, on the other hand, do have complete context and can give more relevant and accurate responses. But they are computationally expensive to process. Therefore, the choice of chunks depends on the requirements of the process.
Related Article- Best ChatGPT Prompts - How to Write Your Own
This system is highly useful for different professionals and that list includes AI engineers. These RAG interview questions for AI engineers are helpful in clearing face-to-face technical rounds.
Building a production-ready system encompasses dealing with different challenges. Potential solutions could be -
It begins with gathering and preparing data that is specific to the task. It could be annotated examples of summarization datasets or question-answer pairs. Techniques like retrieval-augmented language modeling (REALM) can then be used. These techniques are used by the model for integrating the retrieved documents into its responses. This usually means changing the training methods or architecture of the model to improve its way of handling context from retrieved documents.
Retrieval-Augmented Fine-Tuning (RAFT) can also be used for blending RAG's strengths with fine-tuning. It lets the model learn domain-specific knowledge and more about ways of effectively retrieving and using external information.
Balancing relevance and diversity is about providing well-rounded and accurate answers. Relevance is behind making sure that the retrieved documents closely match the query. Diversity is behind making sure that the system doesn't focus very narrowly on a single viewpoint or source.
It can be balanced by using re-ranking strategies that give importance to both these aspects. Diversity can be made better by pulling documents from different sections or sources within the knowledge base. Clustering alike results and picking documents from distinct clusters can be helpful too. Fine-tuning the retriever by focusing on relevance as well as diversity makes the system retrieve a complete set of documents.
Latency can be reduced in several ways without sacrificing accuracy. Developers often use optimized vector indexes such as HNSW or FAISS for faster similarity search. Query caching and response caching can reduce repeated computation. Parallel retrieval and asynchronous pipelines also speed up processing. In addition, using smaller embedding models or reranking only the top-k documents helps maintain accuracy while keeping inference time low.
To build a question-answering system, we need to select two components including a retriever and fine-tune generator. The retriever will efficiently find and retrieve the documents relevant to the user query. It can use a traditional approach like keyword searches or use more advanced techniques such as dense embeddings. The fine-tuning generator will create coherent and accurate answers using the same document.
Creating a summarization system requires a retriever to gather content relevant to the topic at hand. Then the generator distills this content into concise and meaningful summaries. The prompt engineering also plays a crucial role here as the prompt can give more relevant and accurate responses.
There are many ways to manage irrelevant information from these systems. Here are some of them -
If my RAG system starts giving irrelevant or outdated answers, I first check the retrieval pipeline. I inspect what documents are being retrieved for that query. If they’re irrelevant, the issue is usually with embeddings, chunking, or index freshness. I verify whether the vector index is up to date or if ingestion failed, causing stale data.
Next, I test the retriever quality by running a few top-k searches manually to see if the embedding model changed or if metadata filters broke. If retrieval is fine but the answer is still wrong, then it’s likely an LLM grounding issue, so I tighten the prompt, add citations, or apply a reranker to improve context ranking.
Finally, I fix the root cause, usually by reindexing, re-embedding, adjusting chunking, or restoring filters, and add quick evaluation checks so the issue doesn’t recur.
A vector database is a specialized database designed to store and search vector embeddings efficiently. Embeddings are numerical representations of text, images, or other types of data that capture their semantic meaning. In a RAG system, documents are converted into embeddings using an embedding model and stored inside a vector database.
When a user submits a query, the query is also converted into an embedding. The vector database then performs a similarity search to find the documents whose embeddings are closest to the query embedding. These retrieved documents are provided as context to the large language model to generate accurate responses.
Popular vector databases used in RAG systems include Pinecone, Weaviate, Milvus, Chroma, and FAISS. These tools help retrieve relevant information quickly, making them an essential component of modern retrieval-augmented generation systems.
Chunking is the process of splitting large documents into smaller sections before storing them in the retrieval system. Instead of storing entire documents, RAG systems divide the content into manageable chunks so that the retriever can find more precise and relevant information for a user query.
This improves retrieval accuracy because smaller chunks allow the system to match specific parts of a document with the user’s question. If the document is too large, the retriever may return irrelevant sections, which can reduce the quality of generated responses.
Common chunking strategies include fixed-size chunking, semantic chunking, and sliding window chunking. Selecting the right chunk size is important because very small chunks may lose important context, while very large chunks may reduce retrieval precision.
Reranking is a technique used to improve the quality of retrieved documents before they are passed to the language model. The retriever usually returns multiple candidate documents, but not all of them are equally relevant to the user’s query.
A reranking model evaluates these documents and rearranges them based on their relevance and contextual similarity to the query. The top-ranked documents are then selected as context for the large language model to generate a more accurate and reliable response.
Modern RAG systems often use cross-encoder models or specialized reranking models such as Cohere Rerank or BGE Reranker. These tools help improve retrieval quality and ensure that the language model receives the most relevant information.
Let's explore some of the most asked scenario-based RAG interview questions and answers you need to prepare for your next interview.
In this situation, I would first inspect the retrieval pipeline rather than the language model. The problem usually occurs when the retriever returns semantically similar but contextually irrelevant documents.
I would follow these steps:
If retrieval quality is poor, I would re-embed documents, adjust chunking strategies, or introduce a reranking model to improve document relevance before passing context to the LLM.
For an enterprise knowledge assistant, I would create a scalable RAG architecture with separate ingestion, retrieval, and generation layers.
The implementation would include:
I would also implement access controls, document versioning, monitoring, and periodic re-indexing to keep the knowledge base current and secure.
High latency usually originates from vector search, reranking, or LLM inference delays. To improve performance, I would:
The goal is to maintain retrieval quality while reducing unnecessary computation throughout the pipeline.
In regulated industries, explainability is as important as accuracy. I would implement source attribution by:
This approach improves transparency, regulatory compliance, and user trust because every answer can be traced back to its source.
Building a multilingual RAG system requires careful handling of both retrieval and generation. I would address the following challenges:
This design allows users to ask questions in one language while retrieving relevant information from documents written in another language, creating a more flexible enterprise knowledge system.
Traditional RAG follows a fixed sequence of retrieving relevant documents and passing them to an LLM for response generation. Agentic RAG, however, gives the language model the ability to make decisions during the retrieval process. Instead of retrieving information only once, the model can plan, retrieve additional documents, call external tools, refine queries, and verify its own responses before generating the final answer.
This approach is useful for complex enterprise tasks where a single retrieval is not enough. Agentic RAG generally produces more accurate and context-aware responses but introduces additional latency, complexity, and infrastructure requirements.
Prompt injection is one of the biggest security risks in modern RAG systems because malicious instructions can be hidden inside retrieved documents. I would first sanitize and validate retrieved content before sending it to the LLM and clearly separate system prompts from retrieved context.
I would also implement content filtering, restrict the model from executing instructions found inside documents, use metadata-based trust scoring, and log suspicious retrieval patterns. Regular security testing with adversarial prompts would help identify vulnerabilities before deployment.
GraphRAG combines knowledge graphs with Retrieval-Augmented Generation to capture relationships between entities rather than relying only on semantic similarity. Instead of retrieving isolated document chunks, it retrieves connected information through graph traversal.
I would choose GraphRAG when applications require reasoning over relationships, such as fraud detection, healthcare, legal research, scientific knowledge, or enterprise knowledge graphs. Traditional vector search works well for semantic similarity, while GraphRAG performs better when understanding entity relationships is critical.
I would first create separate ingestion pipelines for different content types. Text would be embedded directly, while PDFs would undergo OCR if necessary, and images would be processed using vision-language models capable of generating embeddings.
All embeddings would be stored inside a vector database along with metadata describing the content source. During retrieval, the system would search across all modalities, rerank the retrieved results, and provide them as context to a multimodal language model capable of understanding both text and images.
Model Context Protocol (MCP) provides a standardized way for AI models to access external tools, databases, APIs, and enterprise applications. Instead of building custom integrations for every data source, the model communicates with standardized MCP servers that expose approved resources.
In a RAG environment, MCP simplifies access to enterprise knowledge sources, improves interoperability between AI systems, reduces maintenance effort, and allows the language model to retrieve fresh information from multiple business applications through a consistent interface.
Q1. What does RAG stand for in the context of AI and machine learning?
Q2. What is the primary function of the retrieval component in a RAG system?
Q3. Which type of model is typically used for the generative component in RAG?
Q4. How does RAG improve the performance of language models?
Q5. What is a common challenge when implementing RAG systems?
Q6. Which technology is often used for document retrieval in RAG systems?
Q7. What role does the context from retrieved documents play in RAG?
Q8. Which of the following is a key benefit of RAG over traditional LLMs?
Q9. What is a typical use case for RAG in enterprise applications?
Q10. What is a common method to improve the retrieval step in RAG?
Every individual of the emerging AI world will benefit from these RAG interview questions and questions. Different level professionals have to prepare with different sets of questions and they're mentioned in this blog for a complete outlook. Staying confident and preparing well are the two key ingredients to acing any job interview.
You can start by understanding retrieval mechanisms, practicing using embeddings, studying generative AI workflows, and familiarizing yourself with evaluation metrics and tools.
There are many but some of the topics include retrieval mechanisms, embeddings, scalability, and evaluation metrics.
The following are the common use cases of this system -
Basic knowledge of Python, machine learning, embeddings, vector databases and LLMs is helpful to work with RAG.
Python is the most commonly used language for building RAG applications. It offers strong libraries and tools that make retrieval and AI integration easy.
Explore Our Trending Articles-
Salesforce Interview Questions
Generative AI Interview Questions
Machine Learning Interview Questions
Course Schedule
| Course Name | Batch Type | Details |
| Generative AI Training | Every Weekday | View Details |
| Generative AI Training | Every Weekend | View Details |