If you have a C++ interview coming up, you are in the right place. Whether you are just starting out or have years of experience under your belt, interviewers test you differently at every level.
This guide covers C++ interview questions for freshers, intermediate developers and experienced professionals. It also includes scenario-based questions that top companies love to ask. Read every section that matches your level and you will walk into the interview confident and prepared.
C++ is still very much alive and well; companies such as Google, Microsoft, Amazon, Adobe and gaming studios throughout the world utilize it daily during their production processes! C++ allows for the development of operating systems, game engines of all types or embedded systems, high-frequency trading platforms as well as compilers.
Additionally, C++ is preferred among interviewers due to its ability to simultaneously assess a candidate's knowledge of memory management capabilities, performance optimization strategies and object-oriented design principles.
By having an overall concept of these different areas within C++, a candidate who is able to properly answer C++ interview questions will ultimately provide evidence that he/she truly understands how computers perform their tasks at the lowest possible level rather than merely writing code for computer execution as a finished product.
Related Article: C++ Programming MCQs (Multiple Choice Questions)
These questions test your understanding of C++ basics, syntax and core concepts. Freshers should be comfortable with all of these before attending any technical interview.
C++ is a general-purpose programming language developed by Bjarne Stroustrup in 1979 as an extension of C. The biggest difference is that C++ supports object-oriented programming. C is a procedural language, meaning you write step-by-step instructions. C++ lets you group data and functions into classes and objects. C++ also adds features like function overloading, references, templates and exception handling that C does not have.
The four pillars are:
The only technical difference is the default access level. Members of a struct are public by default. Members of a class are private by default. In practice, developers use struct for plain data containers and class for objects that have behavior and encapsulation.
A pointer is a variable that holds the memory address of another variable. A reference is an alias for an existing variable. Here are the key differences:
The code below shows both in action so you can see exactly how they behave:
#include <iostream>
using namespace std;
int main() {
int x = 10;
// Pointer
int* ptr = &x;
cout << "Pointer example:" << endl;
cout << "Value of x: " << x << endl;
cout << "Address stored in ptr: " << ptr << endl;
cout << "Value at ptr: " << *ptr << endl;
// Reference
int& ref = x;
cout << "\nReference example:" << endl;
cout << "ref is an alias for x: " << ref << endl;
ref = 99;
cout << "After ref = 99, x is now: " << x << endl;
// Pointer reassignment
int y = 50;
ptr = &y;
cout << "\nPointer reassigned to y: " << *ptr << endl;
return 0;
}
|
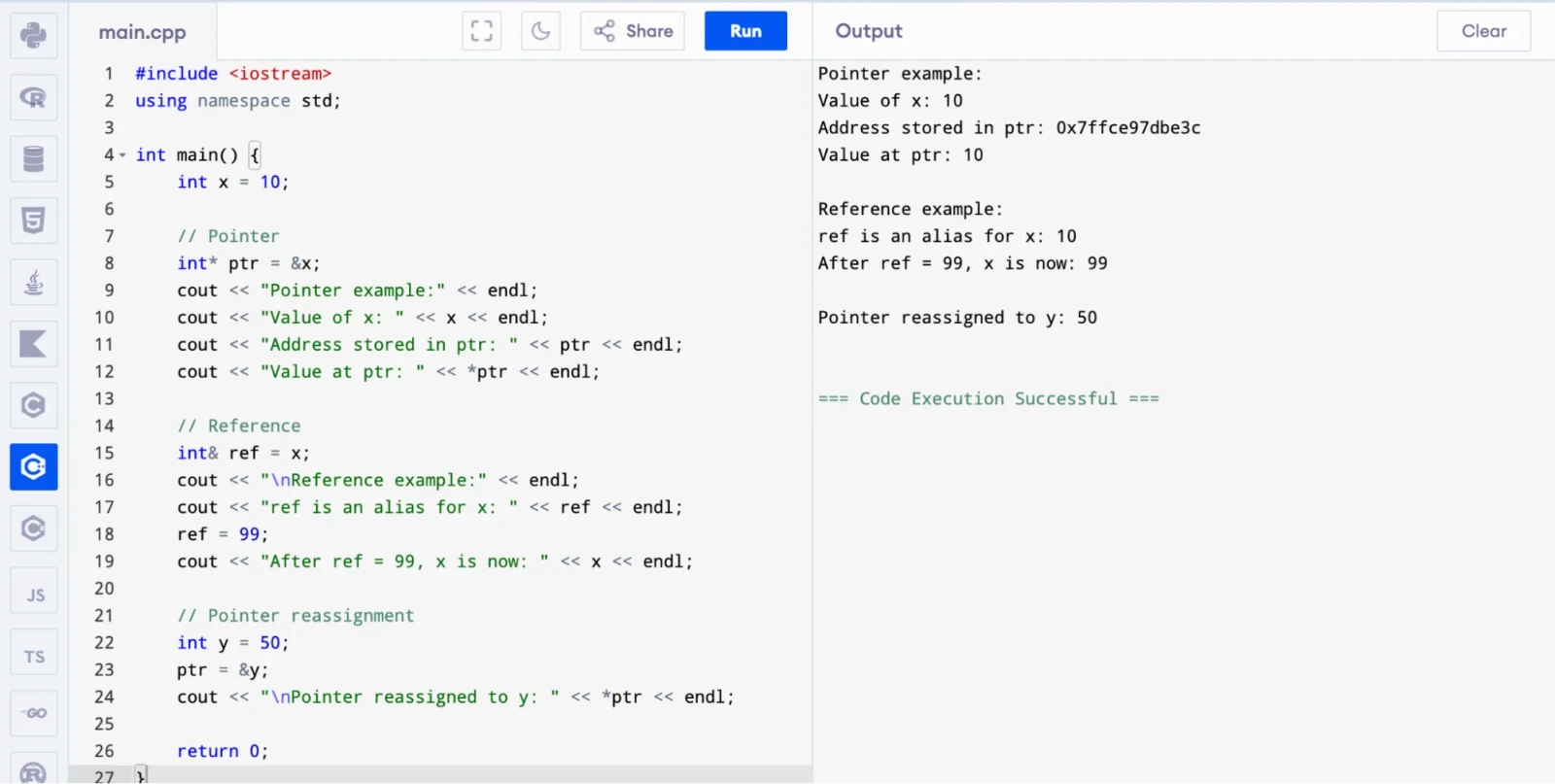
Notice that changing ref to 99 also changed x. That is because a reference and its target share the same memory location.
Also Read: Top Frontend Languages to Learn
Both allocate memory on the heap, but they work differently:
Always use new and delete in C++ code unless you are writing code that needs to be compatible with C.
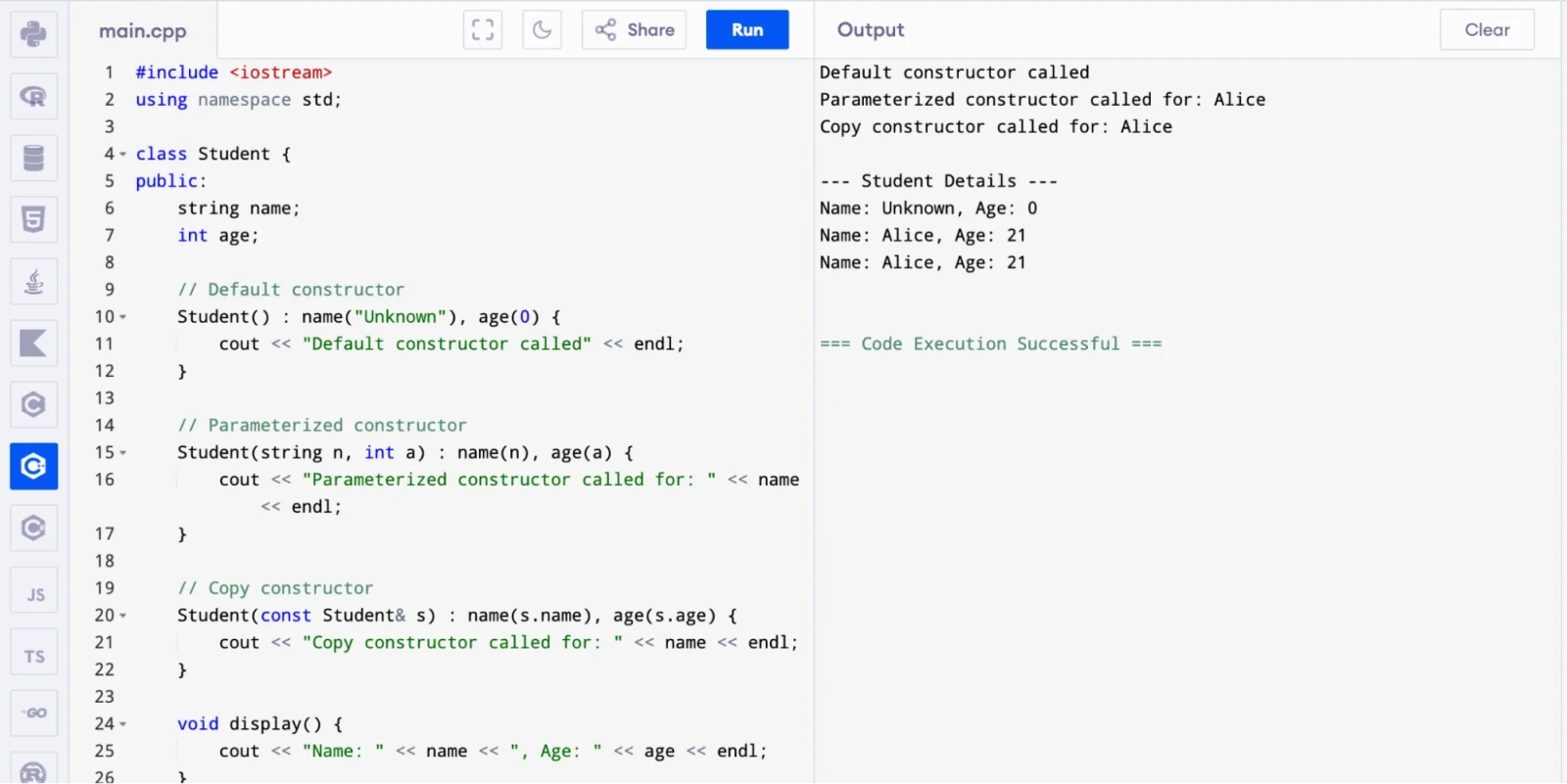
A constructor is a special member function that gets called automatically when you create an object. It initializes the object's data members. The types of constructors in C++ are:
Here is a working example that shows all three classic constructor types printing to the console:
#include <iostream>
using namespace std;
class Student {
public:
string name;
int age;
// Default constructor
Student() : name("Unknown"), age(0) {
cout << "Default constructor called" << endl;
}
// Parameterized constructor
Student(string n, int a) : name(n), age(a) {
cout << "Parameterized constructor called for: " << name << endl;
}
// Copy constructor
Student(const Student& s) : name(s.name), age(s.age) {
cout << "Copy constructor called for: " << name << endl;
}
void display() {
cout << "Name: " << name << ", Age: " << age << endl;
}
};
int main() {
Student s1; // Default
Student s2("Alice", 21); // Parameterized
Student s3 = s2; // Copy
cout << "\n--- Student Details ---" << endl;
s1.display();
s2.display();
s3.display();
return 0;
}
|
A destructor is a special member function that gets called automatically when an object goes out of scope or is explicitly deleted. It has the same name as the class but starts with a tilde (~). You use it to release resources like heap memory, file handles, or network connections. If you allocate memory in the constructor, you should release it in the destructor.
This example shows destructors running automatically when the block ends:
#include <iostream>
using namespace std;
class Resource {
public:
string name;
Resource(string n) : name(n) {
cout << "Constructor: " << name << " acquired" << endl;
}
~Resource() {
cout << "Destructor: " << name << " released" << endl;
}
};
int main() {
cout << "Entering scope..." << endl;
{
Resource r1("File Handle");
Resource r2("Network Socket");
cout << "Inside scope - both resources active" << endl;
}
cout << "Left scope - destructors called automatically" << endl;
return 0;
}
|
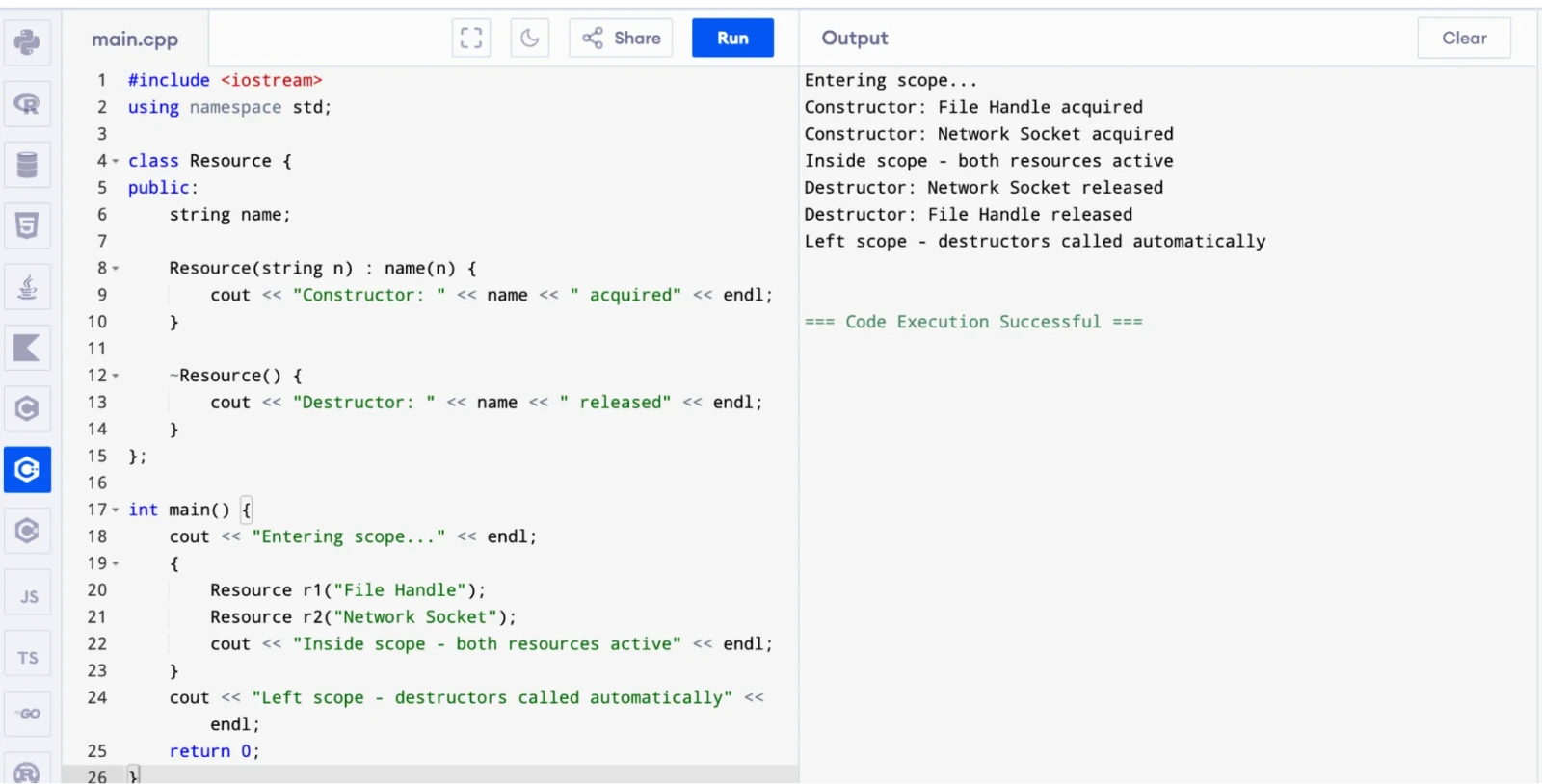
Notice that destructors run in reverse order of construction. r2 is destroyed before r1. This is how the C++ stack works.
Use delete to free a single object created with new. Use delete[] to free an array created with new[]. If you use delete on an array, you get undefined behavior. The runtime does not know how many destructors to call.
Function overloading means you can define multiple functions with the same name as long as they have different parameter lists. The compiler selects the right function based on the arguments you pass. The return type alone is not enough to overload a function.
#include <iostream>
using namespace std;
int add(int a, int b) {
cout << "int version called" << endl;
return a + b;
}
double add(double a, double b) {
cout << "double version called" << endl;
return a + b;
}
string add(string a, string b) {
cout << "string version called" << endl;
return a + b;
}
int main() {
cout << "add(3, 4) = " << add(3, 4) << endl;
cout << "add(2.5, 1.5) = " << add(2.5, 1.5) << endl;
cout << "add(\"Hi \", \"there\") = " << add(string("Hi "), string("there")) << endl;
return 0;
}
|
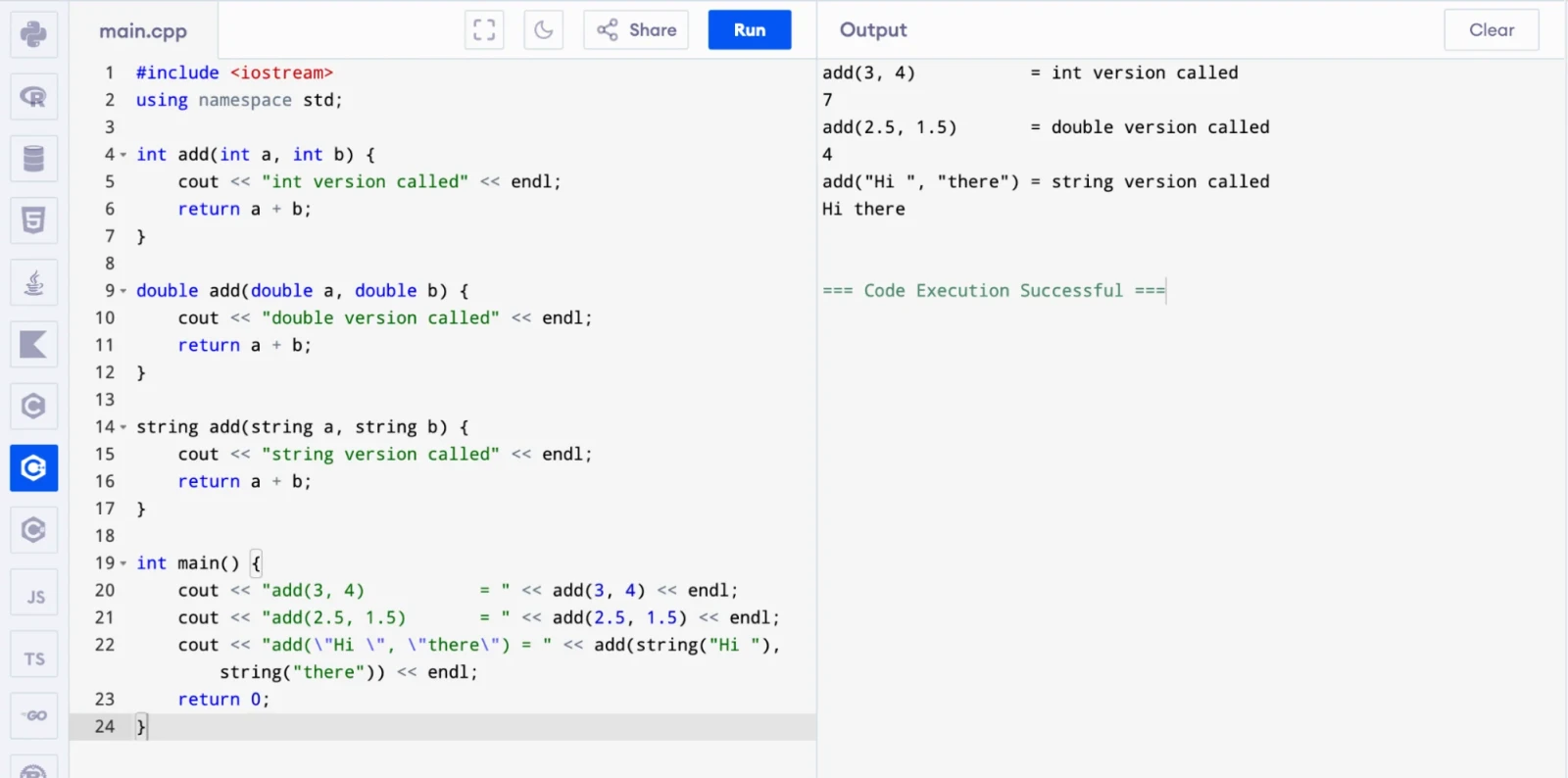
The compiler picks the right version automatically based on argument types. This is compile-time polymorphism in action.
Access specifiers control the visibility of class members. C++ has three:
Related Article: What is Laravel?
const tells the compiler that something should not change. You can apply it to variables, pointers, function parameters and member functions.
A namespace groups related identifiers (variables, functions, classes) under a name to avoid naming conflicts. The std namespace in C++ holds all standard library features. You use :: to access members of a namespace, or you bring them in with using namespace std.
Compile-time polymorphism happens during compilation. Function overloading and operator overloading are examples. The compiler decides which function to call.
Runtime polymorphism happens during program execution. Virtual functions and function overriding through base class pointers are examples. The decision happens at runtime via the vtable.
A virtual function is a member function declared in a base class with the virtual keyword. When you call it through a base class pointer or reference that actually points to a derived class object, C++ calls the derived class version of the function. This is how runtime polymorphism works.
This example brings virtual functions and abstract classes together in a way interviewers love to see:
#include <iostream>
using namespace std;
class Shape {
public:
virtual void draw() = 0; // pure virtual
virtual double area() = 0; // pure virtual
virtual ~Shape() {}
};
class Circle : public Shape {
double radius;
public:
Circle(double r) : radius(r) {}
void draw() override {
cout << "Drawing Circle" << endl;
}
double area() override {
return 3.14159 * radius * radius;
}
};
class Rectangle : public Shape {
double width, height;
public:
Rectangle(double w, double h) : width(w), height(h) {}
void draw() override {
cout << "Drawing Rectangle" << endl;
}
double area() override {
return width * height;
}
};
int main() {
Shape* shapes[2];
shapes[0] = new Circle(5.0);
shapes[1] = new Rectangle(4.0, 6.0);
for (int i = 0; i < 2; i++) {
shapes[i]->draw();
cout << "Area: " << shapes[i]->area() << endl;
cout << endl;
}
delete shapes[0];
delete shapes[1];
return 0;
}
|
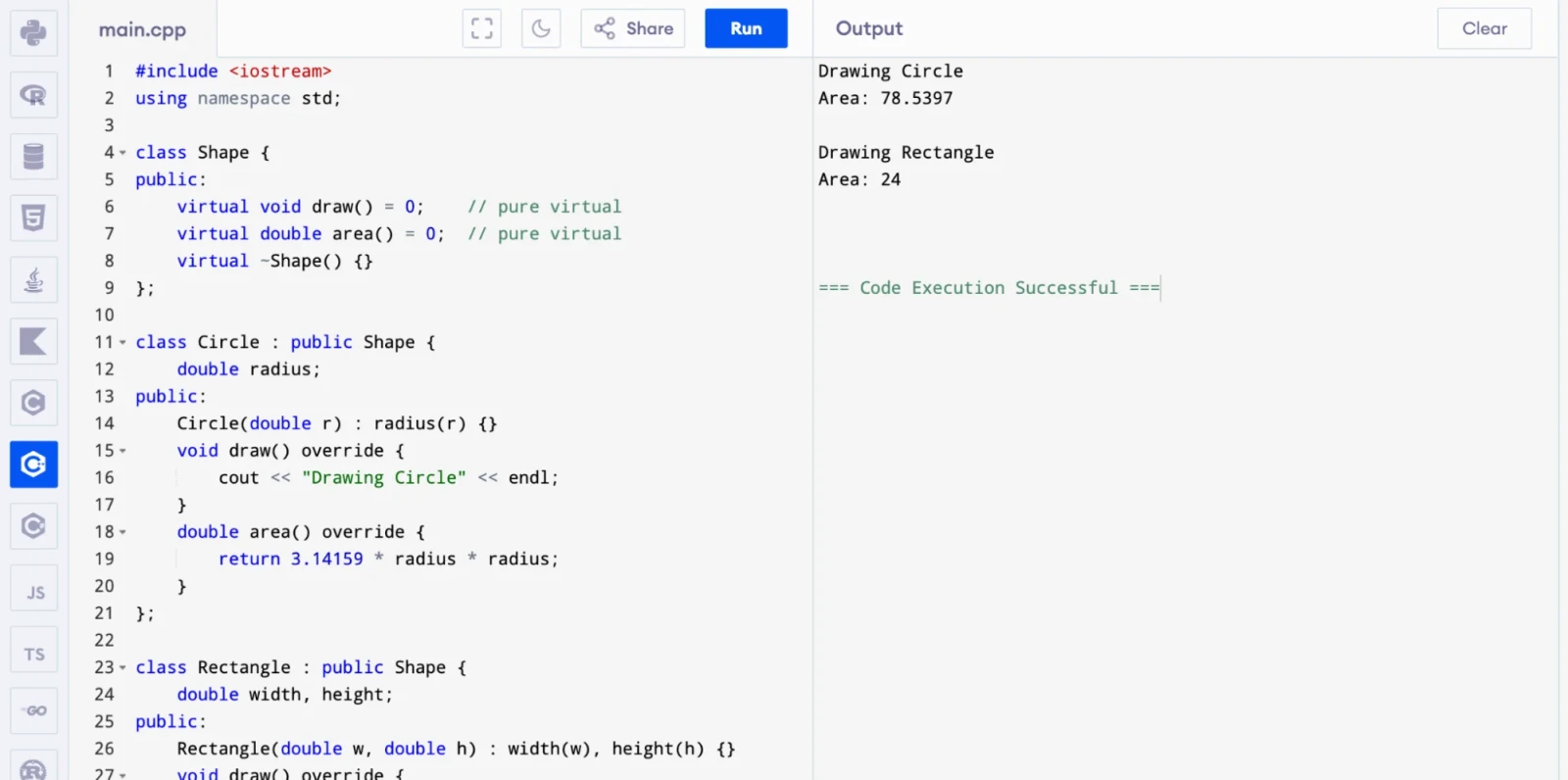
Both objects are accessed through a Shape* pointer. C++ automatically calls the correct derived class version at runtime. This is the vtable at work.
A pure virtual function is a virtual function with no implementation in the base class. You declare it like this: virtual void draw() = 0;. A class that contains at least one pure virtual function is an abstract class. You cannot create objects of an abstract class directly. Derived classes must implement all pure virtual functions to become concrete classes.
Read Also: Differences Between JDK, JRE and JVM
These questions go deeper into memory management, STL and object-oriented design. If you have one to three years of experience, expect these in your interview.
The Rule of Three says that if your class defines any one of these three special member functions, it should probably define all three:
The reason is that if you need a custom destructor to release resources, the default copy constructor and copy assignment operator will do a shallow copy, which leads to double-free bugs and dangling pointers.
C++11 introduced move semantics, which added two more special member functions:
The Rule of Five says that if you define any of the five special member functions, you should consider defining all five to ensure your class handles both copying and moving correctly.
Smart pointers are template classes that manage heap memory automatically. They release memory when it is no longer needed, preventing memory leaks.
A memory leak happens when you allocate heap memory with new and never call delete, causing that memory to remain occupied for the lifetime of the program. You prevent leaks by using RAII, smart pointers and tools like Valgrind or AddressSanitizer during development. Modern C++ code should rarely use raw new and delete directly.
RAII stands for Resource Acquisition Is Initialization. It is a C++ programming technique where you tie the lifetime of a resource (memory, file handle, mutex) to the lifetime of an object. The resource is acquired in the constructor and released in the destructor. When the object goes out of scope, the destructor runs automatically and the resource is freed. Smart pointers are a perfect example of RAII.
Also Read: What is Software Engineer? What Do They Do?
STL stands for Standard Template Library. It is a collection of generic classes and functions that provides common data structures and algorithms. The key components are:
vector stores elements in contiguous memory. It supports O(1) random access. Insertion and deletion in the middle are O(n) because elements must be shifted.
list is a doubly linked list. Elements are not stored contiguously. It does not support random access, so traversal is O(n). But insertion and deletion at any position are O(1) once you have an iterator to the position.
Use vector as your default. Use list when you need frequent insertions and deletions in the middle and do not need random access.
map stores key-value pairs in sorted order by key. It uses a red-black tree internally. Lookup, insertion and deletion are O(log n).
unordered_map uses a hash table internally. It does not maintain order. Lookup, insertion and deletion are O(1) on average, O(n) in the worst case due to hash collisions.
Use unordered_map when you need fast lookups and do not care about order. Use map when you need sorted keys.
Templates let you write generic, type-independent code. Instead of writing the same function or class for int, double and string separately, you write it once as a template and let the compiler generate the specific versions.
#include <iostream>
using namespace std;
template<typename T>
T maxVal(T a, T b) {
return (a > b) ? a : b;
}
int main() {
cout << maxVal(10, 20) << endl;
cout << maxVal(3.5, 7.2) << endl;
cout << maxVal('A', 'Z') << endl;
return 0;
}
|
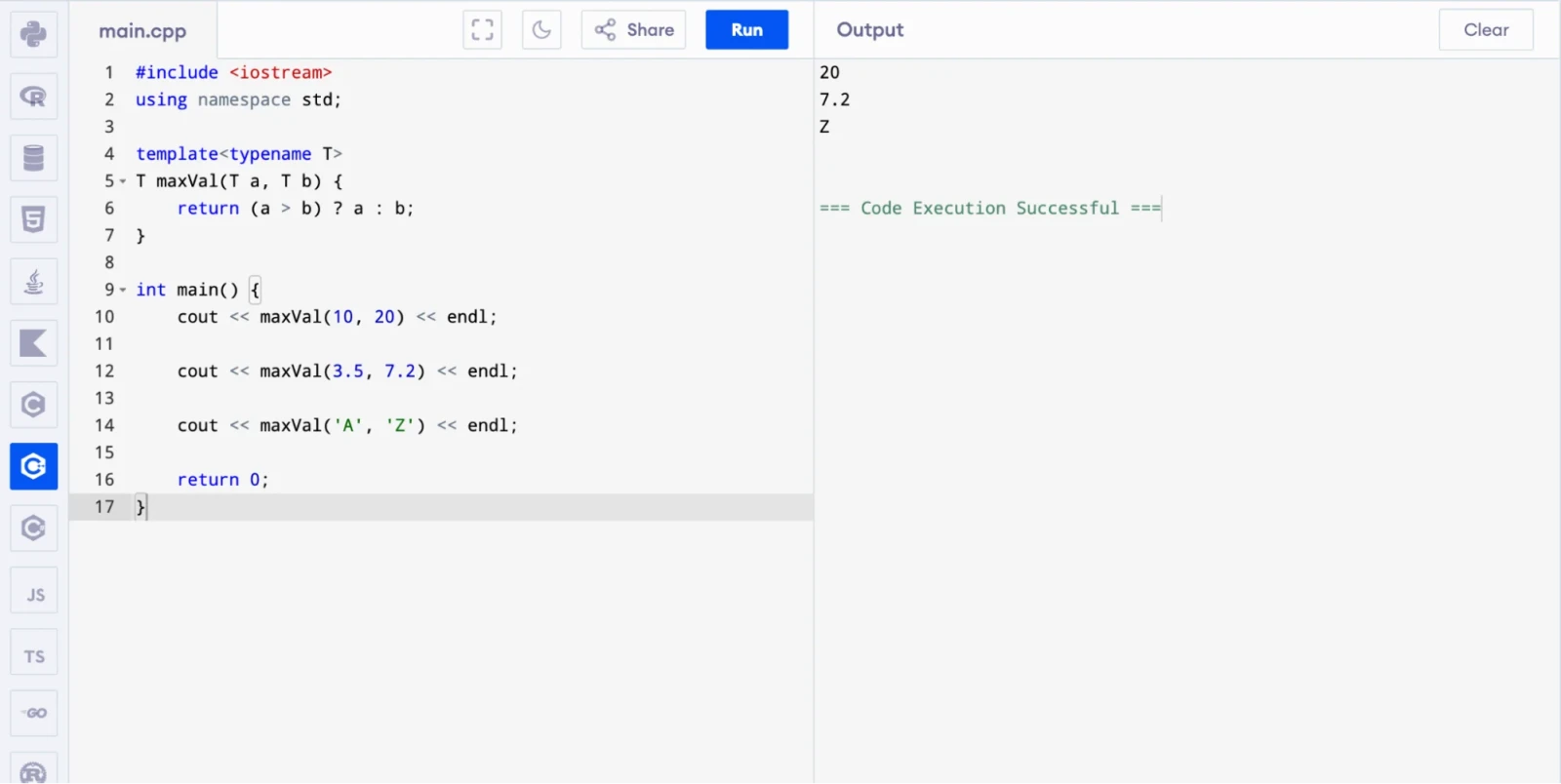
This one function works for any type that supports the > operator.
Template specialization lets you provide a custom implementation of a template for a specific type. If the generic template does not work correctly for char* (for example, comparing pointers instead of string content), you write a specialization that handles that type differently.
Related Article: What Is Bash?
Operator overloading lets you redefine the behavior of operators like +, -, *, <<, >>, == for user-defined types. Since operator overloading works directly with operators, it's helpful to understand the basics of Python Operators before exploring this concept. This feature makes classes feel natural to use.
Operators that cannot be overloaded include: :: (scope resolution), . (member access), .* (pointer-to-member access), ?: (ternary), and sizeof.
12. What is the difference between shallow copy and deep copy?
Shallow copy: Copies only the pointer value, not the data it points to. Both the original and the copy point to the same memory. Modifying one affects the other. Deleting one can leave the other with a dangling pointer.
Deep copy: Allocates new memory and copies the actual data. The original and the copy are completely independent.
The default copy constructor does a shallow copy. If your class manages heap memory, you must write a custom copy constructor that does a deep copy.
Lambda expressions (introduced in C++11) let you define anonymous functions inline, right where you need them. They are especially useful with STL algorithms.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> nums = {5, 2, 8, 1, 9, 3};
cout << "Original: ";
for (int n : nums) cout << n << " ";
cout << endl;
// Sort using a lambda
sort(nums.begin(), nums.end(), [](int a, int b) { return a < b; });
cout << "Sorted: ";
for (int n : nums) cout << n << " ";
cout << endl;
// Transform: square each element
vector<int> squares(nums.size());
transform(nums.begin(), nums.end(), squares.begin(), [](int x) { return x * x; });
cout << "Squared: ";
for (int n : squares) cout << n << " ";
cout << endl;
// Capture a variable from surrounding scope
int threshold = 5;
cout << "Above " << threshold << ": ";
for_each(nums.begin(), nums.end(), [threshold](int x) {
if (x > threshold) cout << x << " ";
});
cout << endl;
return 0;
}
|
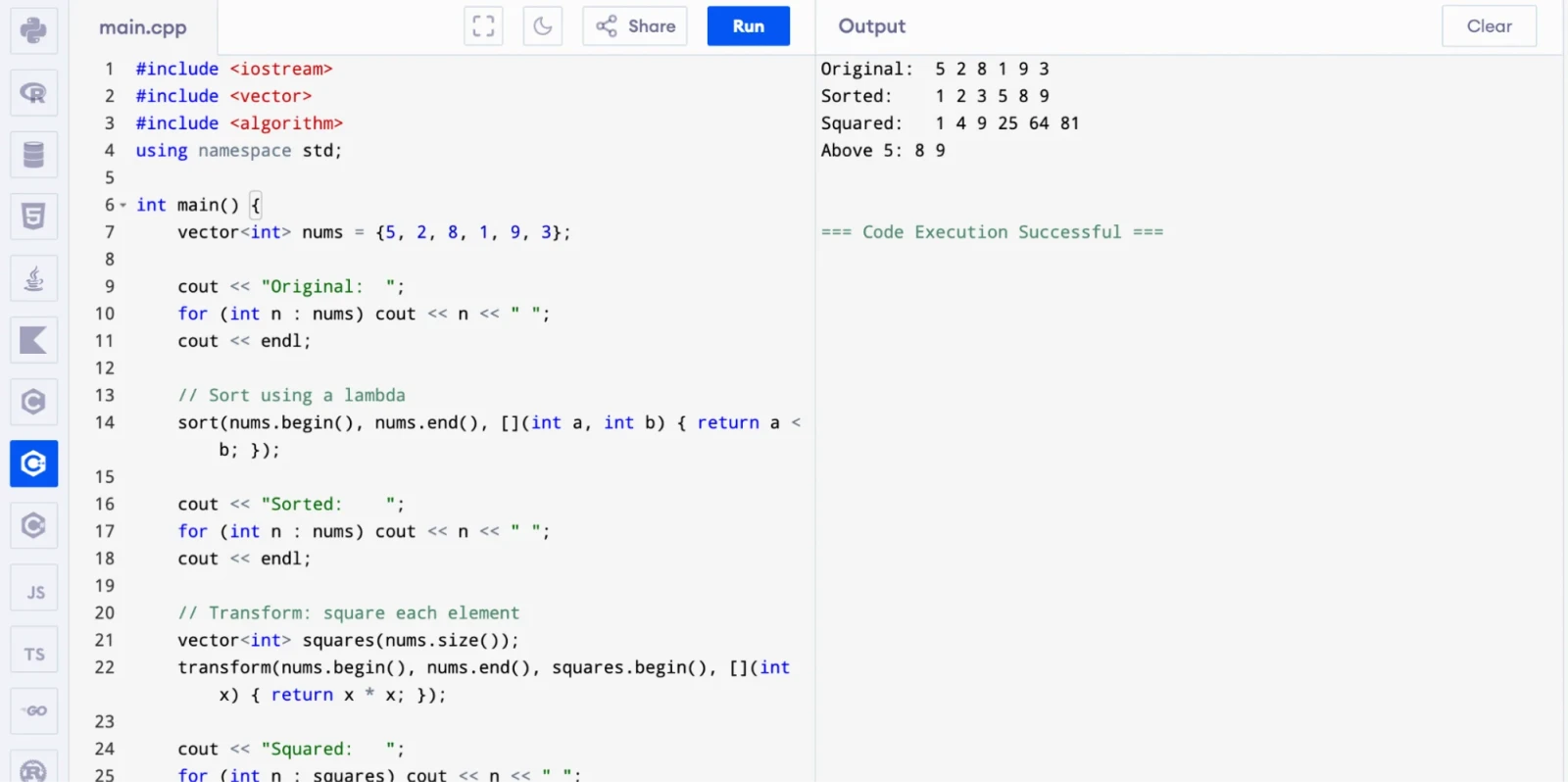
The [threshold] capture list is key. It copies the value of threshold from the enclosing scope into the lambda. You can use [&threshold] to capture by reference instead.
Move semantics (C++11) allows you to transfer resources from a temporary object instead of copying them. This avoids unnecessary, expensive deep copies. std::move casts an object to an rvalue reference, signaling that its resources can be stolen.
A move constructor takes an rvalue reference and "moves" the internal data (like a pointer) from the source object, then nullifies the source so its destructor does not double-free.
constexpr tells the compiler that a function or variable can be evaluated at compile time. This lets you compute values during compilation instead of at runtime, which improves performance.
Related Article: What is IDE: Integrated Development Environment
Senior developers face questions on design patterns, concurrency, advanced memory and system-level thinking. These are the questions you will see in FAANG and senior-level interviews.
Every class with virtual functions has a virtual table (vtable), which is a table of function pointers. Each object of that class holds a hidden pointer called the vptr that points to its class's vtable. When you call a virtual function through a base class pointer, the runtime looks up the function address in the vtable through the vptr and calls the correct derived class version. This is how runtime polymorphism is implemented under the hood.
Virtual functions come with small but real costs. Every call through a base class pointer involves a vtable lookup, which adds an extra memory indirection. This can hurt cache performance. The compiler also cannot inline virtual calls in most cases, which prevents certain optimizations. For performance-critical code in tight loops, you may want to avoid virtual dispatch.
Multiple inheritance allows a class to inherit from more than one base class. The diamond problem occurs when two base classes both inherit from the same grandparent and a derived class inherits from both base classes. This creates ambiguity: which copy of the grandparent's members does the derived class use?
C++ solves this with virtual inheritance. Declaring the common base as virtual ensures that only one shared copy of that base exists in the derived class.
shared_ptr maintains a control block with a reference count. Each time a new shared_ptr is created pointing to the same object, the count increases. When a shared_ptr is destroyed, the count decreases. When the count reaches zero, the object is deleted.
A circular reference happens when object A holds a shared_ptr to object B and object B holds a shared_ptr back to object A. The reference count never reaches zero and neither object is ever freed. You break this cycle by making one of the pointers a weak_ptr, which does not participate in reference counting.
Placement new constructs an object at a specific memory address you provide, rather than allocating new memory from the heap. This is useful in memory pools, embedded systems and real-time applications where you need full control over memory allocation.
#include <iostream>
#include <new>
using namespace std;
class MyClass {
public:
MyClass() {
cout << "Constructor called" << endl;
}
~MyClass() {
cout << "Destructor called" << endl;
}
};
int main() {
char buffer[sizeof(MyClass)];
// Placement new
MyClass* obj = new (buffer) MyClass();
// Manual destructor call
obj->~MyClass();
return 0;
}
|
You must call the destructor manually when using placement new, since you did not use new for allocation.
Read Also: What is Pandas?
Type punning means reading the bits of one type as if they were a different type. The classic unsafe approach is casting a pointer. In C++, most forms of type punning through pointer casts violate strict aliasing rules, leading to undefined behavior. The safe, standard way to do type punning in C++ is std::memcpy or (in C++20) std::bit_cast.
Undefined behavior is code that the C++ standard does not define a result for. The compiler is free to do anything, including producing incorrect results, crashing, or even appearing to work correctly in some builds. Common causes include signed integer overflow, dereferencing a null or dangling pointer, out-of-bounds array access, using a moved-from object and violating strict aliasing rules. Undefined behavior is one of the most dangerous aspects of C++ and a frequent interview topic at senior levels.
std::thread creates a new thread that runs immediately. You must manually call join() or detach(). If you let a thread object go out of scope without joining or detaching, the program terminates.
std::async is a higher-level abstraction. It may run the task on a new thread or defer it until you call .get(), depending on the launch policy. It returns a std::future that lets you retrieve the result safely.
Use std::async when you want a result back. Use std::thread when you need direct control over threading.
A race condition occurs when two or more threads access shared data concurrently and at least one of them writes to it, producing unpredictable results. You prevent race conditions by using synchronization primitives:
A deadlock occurs when two or more threads each hold a resource the other needs, so none of them can proceed. For example, Thread 1 holds Mutex A and waits for Mutex B. Thread 2 holds Mutex B and waits for Mutex A.
Prevention strategies include always locking mutexes in the same order across all threads, using std::lock() to acquire multiple mutexes atomically and using lock-free data structures where possible.
A Singleton ensures that only one instance of a class exists. In C++11 and later, you can implement a thread-safe Singleton using a function-local static variable. The standard guarantees that function-local statics are initialized exactly once, even in multi-threaded environments.
#include <iostream>
using namespace std;
class Singleton {
public:
static Singleton& getInstance() {
static Singleton instance;
return instance;
}
void showMessage() {
cout << "Singleton instance created!" << endl;
}
private:
Singleton() = default;
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
};
int main() {
Singleton& s1 = Singleton::getInstance();
s1.showMessage();
return 0;
}
|
SFINAE stands for Substitution Failure Is Not An Error. When the compiler tries to substitute template arguments and the substitution produces an invalid type, it does not raise an error. Instead, it silently removes that template from the set of candidates. This technique lets you enable or disable template overloads based on type traits.
Related Article: What are Programming Languages?
std::enable_if uses SFINAE to conditionally enable or disable function templates based on compile-time conditions. Type traits (from <type_traits>) let you query properties of types at compile time, such as std::is_integral<T>, std::is_pointer<T>, or std::is_same<T, U>. Together, they let you write highly generic and type-safe code.
Copy elision is a compiler optimization where unnecessary copy or move constructor calls are eliminated. Return Value Optimization (RVO) is the most common form: when a function returns a local object, the compiler constructs it directly in the caller's memory instead of making a copy. In C++17, certain forms of copy elision are mandatory.
size() returns the number of elements currently in the vector.
capacity() returns how much memory the vector has allocated in total.
When you push elements and the size reaches capacity, the vector allocates a larger block (typically double the current capacity), copies all elements to the new block and frees the old one. You can use reserve() to pre-allocate capacity and avoid repeated reallocations.
Run this code and watch how capacity jumps in powers of two while size grows by one:
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v;
cout << "Before adding elements:" << endl;
cout << " Size: " << v.size() << endl;
cout << " Capacity: " << v.capacity() << endl;
cout << "\nAdding elements one by one:" << endl;
for (int i = 1; i <= 8; i++) {
v.push_back(i * 10);
cout << " After push_back(" << i * 10 << ") -> Size: " << v.size()
<< " Capacity: " << v.capacity() << endl;
}
cout << "\nUsing reserve(20):" << endl;
vector<int> v2;
v2.reserve(20);
cout << " Size: " << v2.size() << ", Capacity: " << v2.capacity() << endl;
return 0;
}
|
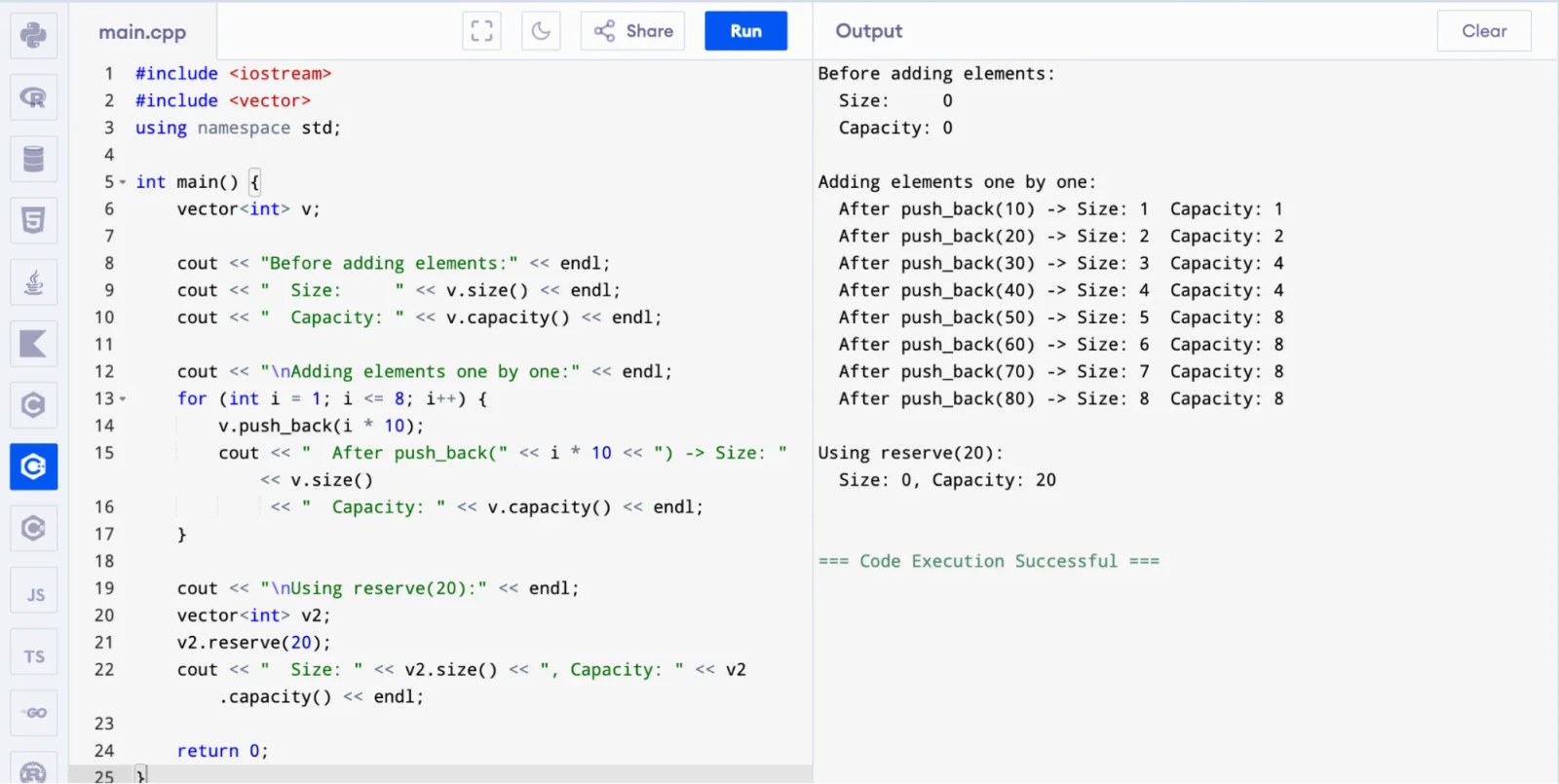
Capacity doubles at positions 3, 5 and so on. This is why calling reserve() upfront saves you from repeated reallocations when you know the final size in advance.
Related Article: What Is CRUD? Create, Read, Update, and Delete
Interviewers at top companies love scenario-based questions because they reveal how you think under pressure. These test your problem-solving ability and your understanding of real-world C++ trade-offs.
Start by reproducing the problem in a controlled environment. Run the application under Valgrind or AddressSanitizer to get a detailed report of where the leak originates. Look for raw new calls without corresponding delete, containers holding pointers to heap objects that are never freed, or circular shared_ptr references. Once you identify the source, refactor toward smart pointers and RAII. Add leak detection to your CI pipeline so similar issues get caught before they reach production.
Profile first. Use a profiler like perf, Callgrind, or Visual Studio's profiler to find exactly where time is spent. Common C++ performance culprits include unnecessary copies of large objects (fix with const references or move semantics), virtual function calls in tight loops (fix with templates or devirtualization), cache misses from non-contiguous data structures (fix with vector instead of list or map) and excessive heap allocations (fix with object pools or stack allocation). Do not guess. Let the profiler guide you.
Delete the copy constructor and copy assignment operator and define a move constructor and move assignment operator.std::unique_ptr follows exactly this pattern.
#include <iostream>
using namespace std;
class MyResource {
public:
MyResource() {
cout << "Resource acquired" << endl;
}
// Delete copy constructor
MyResource(const MyResource&) = delete;
// Delete copy assignment
MyResource& operator=(const MyResource&) = delete;
// Move constructor
MyResource(MyResource&& other) noexcept {
cout << "Resource moved" << endl;
}
// Move assignment operator
MyResource& operator=(MyResource&& other) noexcept {
cout << "Move assignment" << endl;
return *this;
}
~MyResource() {
cout << "Resource released" << endl;
}
};
int main() {
MyResource r1;
MyResource r2 = std::move(r1);
return 0;
}
|
Use inheritance when the relationship is genuinely "is-a". A Dog is an Animal. The derived class truly represents a more specific version of the base class and you need runtime polymorphism through a common interface.
Use composition when the relationship is "has-a". A Car has an Engine. Composition is more flexible because it does not lock you into a class hierarchy. Changing a composed component is easier than changing a base class. The famous guideline from the Gang of Four book is: prefer composition over inheritance.
Use a std::queue protected by a std::mutex. Use a std::condition_variable so the consumer thread sleeps when the queue is empty and wakes up when the producer adds an item. The producer locks the mutex, pushes to the queue, unlocks and notifies the condition variable. The consumer waits on the condition variable, wakes up, locks the mutex, checks that the queue is not empty (guard against spurious wakeups), pops the item and processes it. For high-performance systems, consider lock-free queues using std::atomic or pre-built solutions like Intel TBB's concurrent queue.
Read Also: How to Learn Coding?
Custom allocators let you replace the default new/delete behavior for specific containers or classes. You can implement a memory pool allocator that pre-allocates a large block of memory and hands out chunks from it. This eliminates the overhead of system calls for each allocation and improves cache locality because allocations are contiguous. STL containers accept custom allocators as template parameters. In C++17, polymorphic allocators via std::pmr make this even more flexible.
Without a custom copy constructor, the compiler generates a default one that copies the pointer value, not the data it points to. This is a shallow copy. Now two objects hold the same raw pointer. When the first object is destroyed, its destructor calls delete on the pointer. The second object now holds a dangling pointer. When it is destroyed, it calls delete again on the same address. This is a double-free, which is undefined behavior and can crash the program or corrupt the heap. The fix is to implement the Rule of Five: write a proper copy constructor, copy assignment operator, move constructor, move assignment operator and destructor. Better yet, replace the raw pointer with a unique_ptr.
C++ interviews test more than just syntax. They test how you think about memory, performance, design and correctness. Freshers need to nail the basics of OOP, pointers and constructors. Intermediate developers should be comfortable with STL, smart pointers and move semantics. Experienced professionals need to speak fluently about concurrency, undefined behavior, template metaprogramming and system-level design.
The best way to prepare is to write code every day. Build something real. Read the error messages carefully. Profile your code. Read the C++ Core Guidelines. Practice these questions out loud, because being able to explain something clearly is just as important as knowing the answer.
Read Also: JavaScript Interview Questions and Answers
For junior positions, understand basic templates and why they exist. For senior and advanced positions, interviewers may ask about SFINAE, template specialization and variadic templates.
Memory management. Understanding pointers, dynamic allocation, smart pointers, copy vs. move and RAII separates strong C++ candidates from the rest.
C++ interviews focus heavily on memory management, pointers and undefined behavior because the developer controls memory directly. Java has garbage collection, so those topics do not appear in Java interviews. C++ also tests knowledge of the STL, templates and low-level performance optimization.
Yes, knowing vector, map, unordered_map, set and common algorithms like sort and find is expected even at the fresher level. Interviewers often ask you to solve problems using STL containers.
LeetCode (filter by C++), HackerRank, Codeforces and Codechef are great platforms to practice. The C++ Core Guidelines and Effective C++ by Scott Meyers are excellent reading for deeper understanding.