With continuous advancements in Machine Learning, Variational Autoencoders (VAEs) are changing the way data is processed and created. It combines the power of data encoding and innovative generative capabilities to offer excellent solutions to complicated problems in the field.
Think of them as neural networks with a creative twist. They just don't learn to compress and reconstruct data; they also create a hidden latent space full of possibilities. VAEs blend mathematics and creativity finely together to claim themselves as one of the most fascinating tools in generative AI.
I have created this blog to break this topic down in the simplest way possible. This guide is packed with several important topics to strengthen your understanding as a reader. It includes the meaning, types, architecture, mathematics, and implementation of VAEs along with other aspects.
Variational Autoencoders (VAEs) are machine learning models that learn the underlying structure of data in order to create completely new examples that share the same characteristics as the original output. Let me put it simply for you, they go through tons of data (images, sounds or handwriting). After that it learns the patterns to generate new and similar examples.
VAEs go beyond the basic functionality of standard autoencoders by learning a probabilistic distribution of important features along with encoding data. This is what makes them generate new and diverse data points that closely align with the original dataset. Now let me give you an example of cats to make you understand how it works.
A VAE will go through a bunch of cats' pictures to learn what makes a cat a 'cat' like their ear shape, eye size and fur pattern. Then it squeezes each cat picture into a little 'summary' of those features. After that it can use that summary to recreate the original cat picture or even mix-match features to create realistic brand brand-new images.
Explore igmGuru's Machine Learning training program to understand VAEs better.
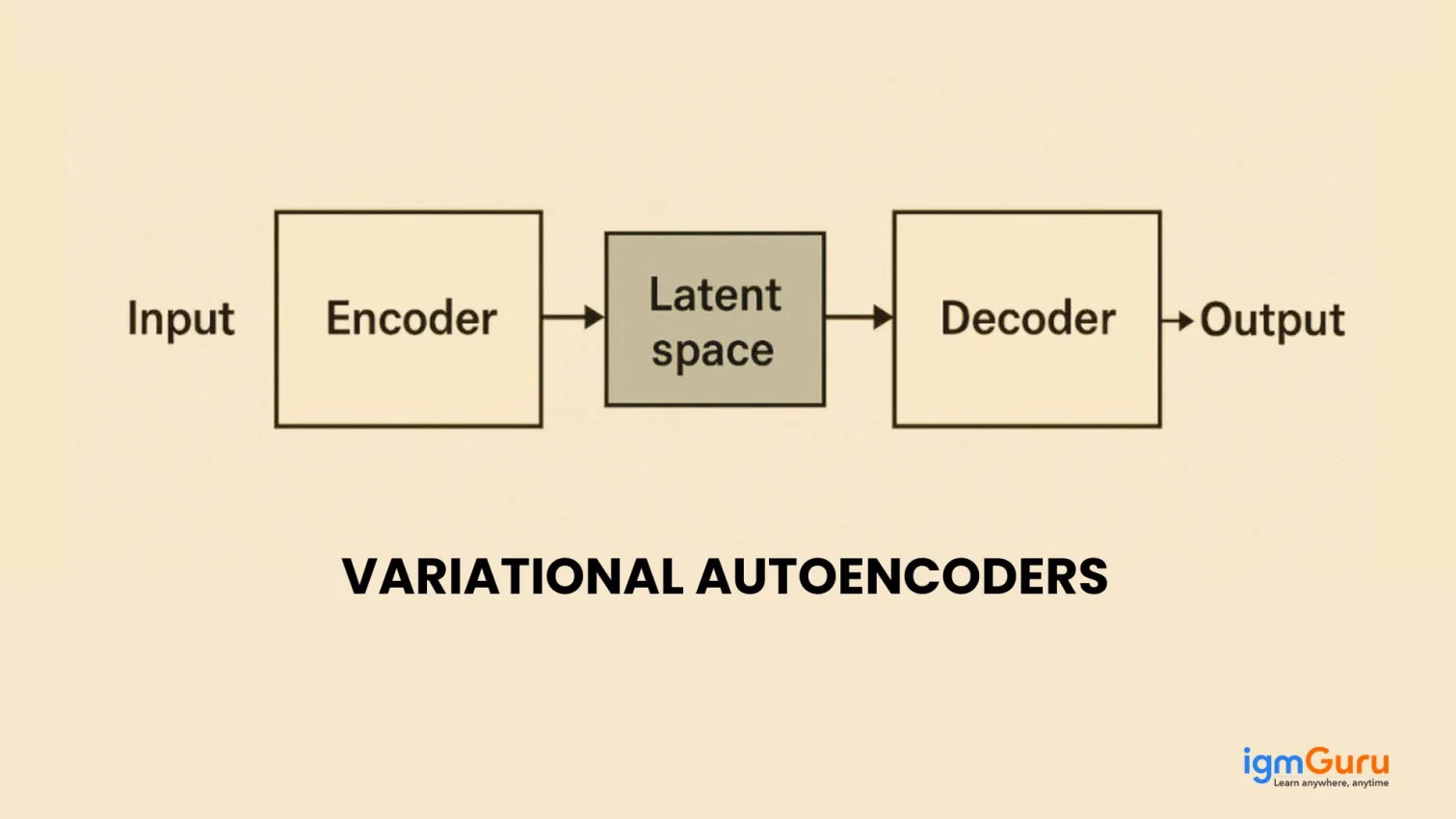
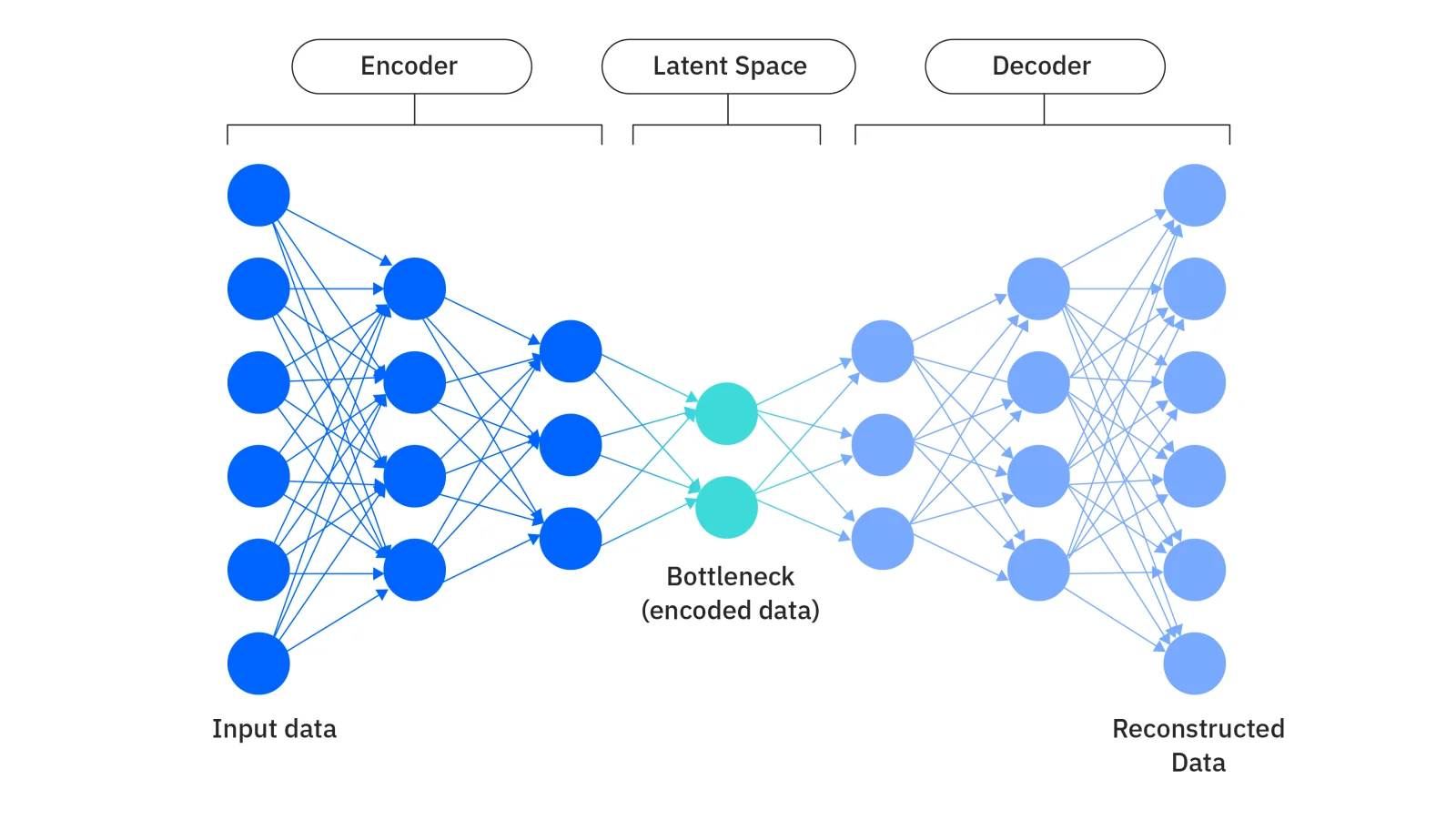
You must understand the architecture of Variational Autoencoder to grasp how the model learns to compress difficult data into simple representation. Let's see what it consists of-
The encoder processes input data like images or text to catch its important characteristics. It generates two vectors for each feature rather that giving a single fixed value-
This process involves the model selecting a random point from the range defined by the mean or standard deviation. It adds randomness which allows the model to create slightly varied versions of the data. This makes it effective for generating new and realistic samples.
The decoder receives a randomly sampled point from the latent space and attempts to recreate the original input. The decoder can generate outputs that resemble the original data but are not exact copies as the encoder gives a range. This allows for the creation of new yet similar content.
It combines of two parts which are as follows-
After a VAE has been trained, it can also generate new data along with reconstructing inputs.
Read Also- Machine Learning Roadmap For Beginners
Here are some important use cases of Variational Autoencoders -
VAEs can generate new, realistic looking images after training on a dataset (faces, digits or objects). You can take examples of MNIST digit generation or CelebA face synthesis. They are mostly used as a baseline against powerful models like GANs.
VAEs learn compact latent representations for denoising images which means removing noise while preserving structure. It is also capable of compressing high-dimensional data into smaller latent codes.
VAEs learn the underlying patterns of normal data and can flag anything that deviates from those patterns. This makes them useful across industries for purposes like spotting financial fraud or finding early signs of equipment failure in manufacturing.
They can also create a wide variety of data samples from images to audios and more. This generative power unlocks applications across industries like healthcare, logistics, marketing, business and much more.
Variational Autoencoders are useful for learning latent spaces for MRL/CT scans which helps in disease classification. They also help with drug discovery by generating novel molecular structures that obey chemical rules by sampling from latent space.
Variants like VAE-Transformers or VAE-LSTM are used for purposes like music composition, dialogue generation, speech synthesis, etc.
Read Also- Top 10 Machine Learning Frameworks to Use In 2026
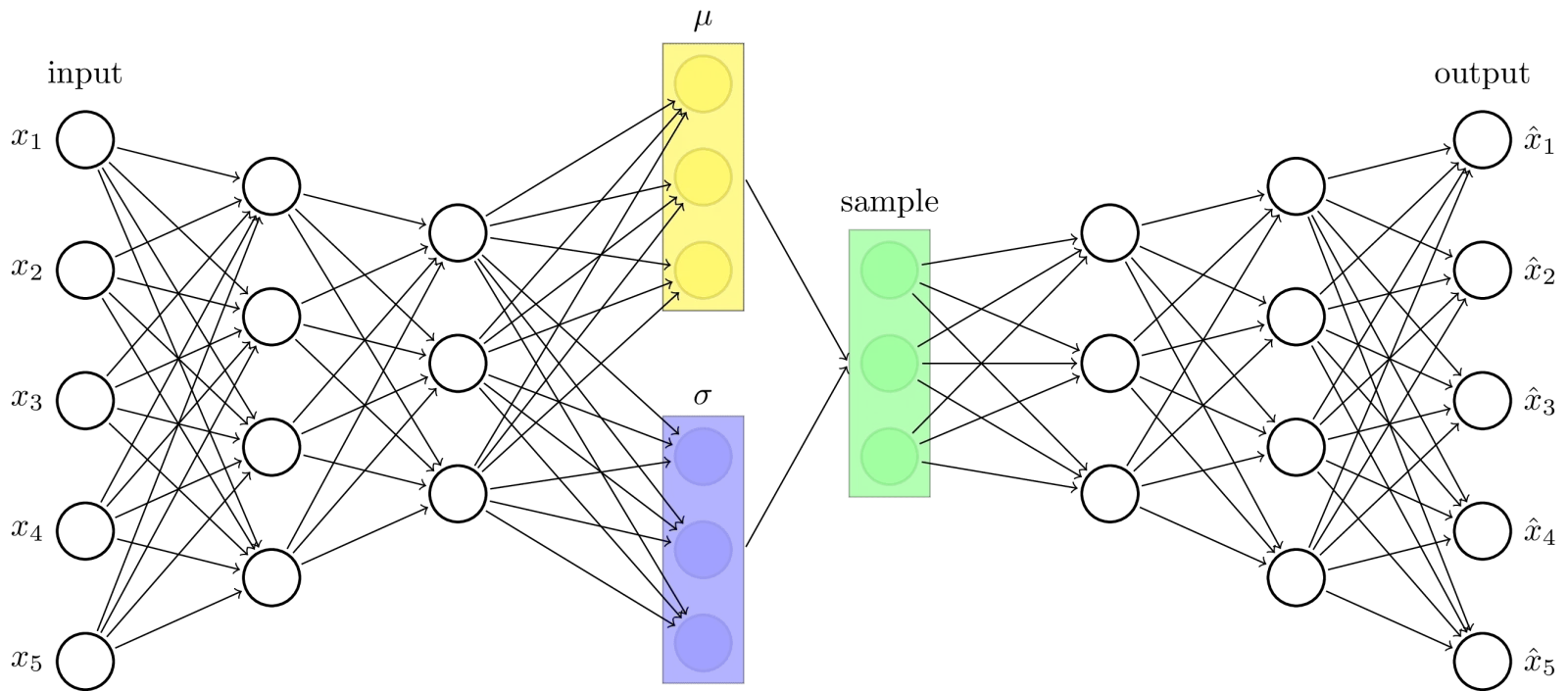
In this section, you will get familiar with how does variational autoencoders work. They have an encoder that compresses input data into a simpler form. It also has a decoder that reconstructs the original data from this compressed representation. When trained effectively, autoencoders can recreate the input with high accuracy. Let's understand this through the following 5 steps -
You begin with input data xx (let's say an image). The encoder network maps xx to a latent distribution instead of a fixed vector. The VAE learns to detect key elements from the training data.
A sample is drawn from the encoded probability distribution which represents a point in the latent space that holds the important features of the original data. This sampling step introduces a touch of randomness. This allows the model to go through different variations within the learned distribution and ultimately making it possible to generate diverse yet realistic outputs.
The decoder which is also a neural network receives the sampled point from the latent space as input. Its role is to use the information in this latent representation to reconstruct the original data as closely as possible.
The VAE is trained by minimizing a loss function made up of two key parts -
We can use the VAE once it's trained to use it to reconstruct existing data along with generating completely new samples.
Read Also- Machine Learning Tutorial- A Complete Guide For Beginners
A 'Variational Autoencoders vs Generative Adversarial (VAEs vs GANs) is a must topic in this blog. Both networks accomplish this task with the help of dual neural networks yet have different approaches. This is how they differ -
| Aspect | GAN (Generative Adversarial Network) | VAE (Variational Autoencoder) |
| Functionality | Consists of two networks — a Generator and a Discriminator — that work against each other. The generator creates fake samples, and the discriminator identifies whether samples are real or generated. | Built with an Encoder and a Decoder. The encoder compresses inputs into a latent space, while the decoder reconstructs data from that space back into the original domain. |
| Latent Space | The latent space in GANs is often unstructured, making it difficult to interpret or control generated features. | Produces a well-structured latent space that’s easier to understand and manipulate, allowing meaningful variations in outputs. |
| Output Quality | Capable of generating high-quality, realistic outputs that can closely resemble real data. | Outputs tend to be less sharp or slightly blurred compared to GANs. Quality depends on implementation and the dataset. |
| Use Cases | - Creative content generation - Image generation - Text-to-image synthesis - Style transfer | - Anomaly detection - Image denoising - Recommendation systems |
| Training Stability | Challenging and unstable to train due to the adversarial nature of its loss function. | More stable and easier to train since it uses a likelihood-based objective function. |
Read Also- How to Build A Machine Learning Model?
Before we discuss the types of variational autoencoders, it is important to note that there is not a fixed number of types. New variations keep popping up for better performance and different tasks. Let's discuss some common and popular variants-
Vanilla Autoencoders are the most basic type of autoencoder used in unsupervised learning. They have two key parts called an encoder to compress input data and a decoder to reconstruct the original input. These autoencoders serve as the building blocks for more advanced and complicated variants.
Denoising Autoencoders are built to handle noisy or corrupted inputs by learning to restore the clean and original data. The model is given corrupted inputs during the training and optimized to reduce reconstruction error against the uncorrupted version. This process encourages the network to learn strong features that remain consistent even in the presence of noise.
Contractive Autoencoders add a penalty term during training to make sure the learned representations remain stable under small changes in the input. They also include a regularization term that discourages sensitivity to input perturbations, along with reducing reconstruction error. This results in strong and invariant features that perform well in noisy environments.
Sparse Autoencoders introduce sparsity constraints so that only a small number of hidden neurons activate at a time. This leads to more effective and focused representations. Unlike basic autoencoders, these use techniques like dropout, L1 regularization, KL Divergence to enforce this sparsity. This selective activation allows the model to highlight important features and ignore irrelevant noise.
Read Also- How To Learn Machine Learning- A Complete Roadmap
Let's walk through the implementation of Variational Autoencoders -
We first need to prepare our Python environment with the required libraries to build a VAE. The key ones include numpy, matplotlib, PyTorch and torchvision. Given is the code to install these libraries -
pip install torch torchvision matplotlib numpy |
Follow the given steps to implement VAE., Importing the libraries is the first thing we must do -
import torch |
Here is the code to define encoder, decoder and VAE.
class Encoder(nn.Module): |
Next, we need to define the loss function. In VAEs, this combines two parts - a reconstruction loss and a KL divergence. This is how it can be implemented in PyTorch -
def loss_function(x, x_hat, mu, logvar): |
For training the VAE, we will load the MNIST dataset, set up an optimizer and run the model through the training process.
# Hyperparameters |
Once the training is complete, we can evaluate the VAE by looking at how well it reconstructs the inputs and by generating new samples from the latent space.
# visualizing reconstructed outputs |
For training the VAE, we'll load the MNIST dataset, set up an optimizer, and run the model through the training process.
Although Variational Autoencoders are powerful and flexible generative models, they are not perfect. Like every machine learning technique, VAEs come with certain limitations that are important to understand before using them in real-world projects. Knowing these drawbacks helps you choose the right model and set realistic expectations from its output.
One of the most common limitations of VAEs is that the generated images often appear slightly blurry when compared to models like GANs. This happens because VAEs focus on learning the overall data distribution rather than producing sharp details. The reconstruction objective encourages averaging, which can smooth out fine features.
Another challenge is posterior collapse. In this case, the decoder becomes so strong that it ignores the latent space and produces outputs without relying on meaningful latent representations. This reduces the usefulness of the latent space and limits the generative capability of the model.
VAEs also require careful tuning of hyperparameters such as latent space size and KL divergence weight. If these are not balanced properly, the model may struggle to reconstruct data accurately or fail to generate diverse samples. This trade-off between reconstruction quality and generative flexibility is an important limitation to keep in mind.
In recent years, diffusion models have become extremely popular in generative AI, especially for high-quality image generation. This naturally leads to comparisons between diffusion models and Variational Autoencoders, and whether VAEs are still relevant in modern machine learning workflows.
Diffusion models generate data by gradually removing noise over multiple steps, which allows them to produce very sharp and realistic images. However, this process is computationally expensive and requires significant training and inference time, making diffusion models slower and more resource-intensive.
VAEs, on the other hand, are much faster at generating new samples once trained. They generate outputs in a single forward pass and are easier to train and more stable overall. While they may not match diffusion models in visual quality, VAEs excel in efficiency, interpretability, and representation learning.
In practical applications such as anomaly detection, data compression, and structured feature learning, VAEs remain a strong and reliable choice. Diffusion models are better suited for creative tasks, while VAEs continue to perform well in analytical and production-focused environments.
Training Variational Autoencoders can be confusing for beginners, and small mistakes often lead to poor or misleading results. Understanding these common errors can help you train VAEs more effectively and avoid unnecessary frustration.
VAEs are sensitive to input scales, and unnormalized data can negatively affect both training stability and output quality. Ensuring consistent input scaling is essential, especially when using sigmoid-based decoders.
This means the model has failed. Blurriness is a known behavior of VAEs and does not always indicate poor training. Beginners often misinterpret this characteristic without understanding the probabilistic nature of the model.
Many beginners also overlook the balance between reconstruction loss and KL divergence. If the KL term dominates too early during training, the model may not learn meaningful latent representations. Techniques such as KL annealing are often required to train VAEs effectively and avoid posterior collapse.
Although VAEs are often introduced using simple datasets like MNIST, their real-world applications extend far beyond academic demonstrations. Many industries rely on Variational Autoencoders to extract meaningful patterns from complex and high-dimensional data.
VAEs are commonly used for anomaly detection, such as identifying unusual transaction behavior that may indicate fraud. By learning normal patterns, the model can highlight deviations that require attention.
VAEs help analyze medical imaging data such as MRI and CT scans by learning compact and informative representations. They are also used in drug discovery to generate new molecular structures that follow valid chemical and biological constraints.
VAEs also defect detection and predictive maintenance by spotting irregular machine behavior before failures occur. In recommendation systems and marketing analytics, VAEs help model user preferences and generate personalized insights at scale.
Variational Autoencoders (VAEs) are more than just another neural network. They are a bridge between compression and creativity. By combining the strengths of probabilistic modeling with the flexibility of deep learning, VAEs are capable of many things. Whether you are working in healthcare, finance or creative industries, understanding what are VAEs opens the door to powerful applications.
VAEs use probability distributions in the latent space, which allows them to generate new data as well.
It depends on the use case, GANs usually create sharp and more realistic images. On the other hand, VAEs produce slightly blurrier results but offer a more structured latent space.
VAEs are applied in image and speech generation, anomaly detection (like fraud detection), medical research (for molecule or protein generation), and even creative industries like art and design.
Yes, a VAE is a generative model because it learns data distributions and can generate new, similar data samples.
Course Schedule
| Course Name | Batch Type | Details |
| Machine Learning Course | Every Weekday | View Details |
| Machine Learning Course | Every Weekend | View Details |